
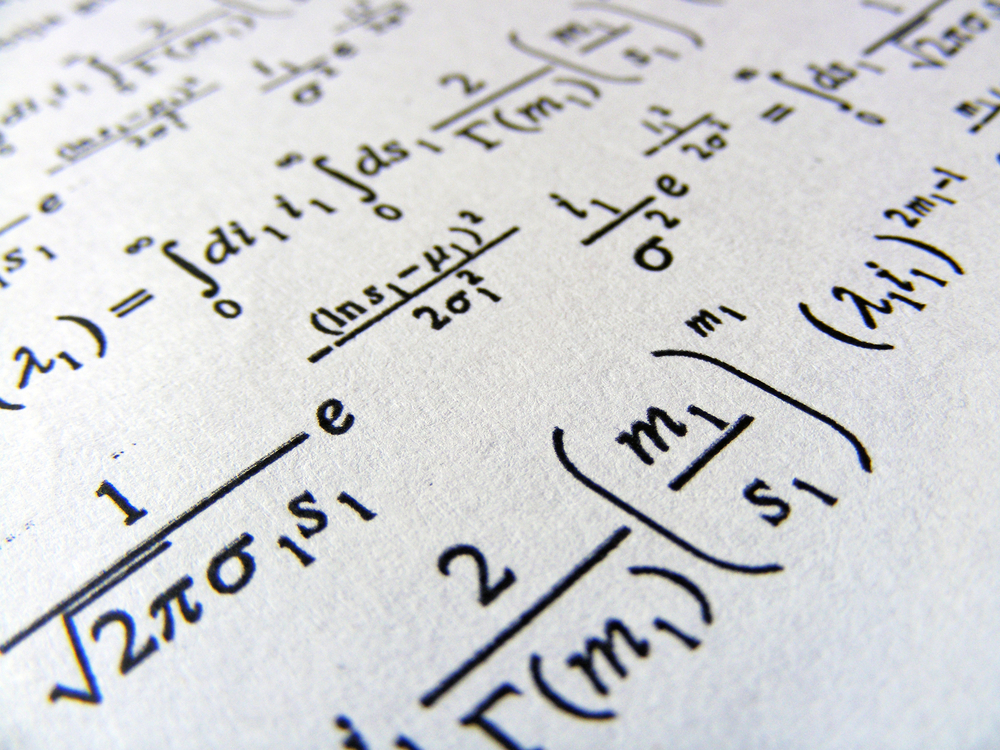
Meta has developed a new AI model called Nougat that can reliably turn scientific text into machine-readable text.
If you’ve ever tried to read a scientific research paper then you begin to understand why it’s tough for it to be processed electronically. Current Optical Character Recognition (OCR) tools parse text line by line.
That’s fine for purely text-based documents but scientific papers add a level of complexity that these standard tools can’t deal with.
Scientific papers include mathematical and scientific symbols and formulas that are often added as subscripts or superscripts. Even the best OCRs have trouble capturing these properly.
What makes it even more challenging is that a lot of these research papers are poorly scanned and the originals are no longer available. Nougat, which stands for Neural Optical Understanding for Academic Documents, is up for the challenge.
Instead of scanning line by line, Nougat processes the entire page using a variant of Meta’s Vision Transformer for image analysis. The model was trained on a dataset of articles published on PubMed Central and arXiv which had corresponding LaTeX source code.
LaTeX is software that’s used to write scientific papers that call for complex formulas and math symbols. The model was trained by looking at the image of the paper and comparing it to the code that generated the complex text.
Here’s an example of one of Meta’s experiments in digitizing an old research paper.

Source: Meta
There are some more impressive examples on the Facebook Research page.
Nougat isn’t perfect, but it still achieved a BLEU score of over 91% and an accuracy of over 96% with continuous text. The BLEU score measures the similarity of the machine-translated text to a set of high-quality reference translations.
For formulas and tables, it fared a little worse with an accuracy of just over 75%. That’s still a lot better than competing models like GROBID which only manages to get it right 11% of the time.
There are millions of pages of research that aren’t indexable or searchable because they can only effectively be read by humans. Nougat changes that by allowing even poorly scanned research PDFs to be converted into machine-readable text.
As with so many of its other new tools, Meta has made this one freely available on GitHub. There may be some level of self-interest in this development, though. Once old research papers are machine-readable they become available for training other AI models.
It will be interesting to see what long-lost research gems are rediscovered using Nougat.



