

Nvidia announced new open source software that it says will supercharge inference performance on its H100 GPUs.
A lot of the current demand for Nvidia’s GPUs is to build computing power for training new models. But once trained, those models need to be used. Inference in AI refers to the ability of an LLM like ChatGPT to draw conclusions or make predictions from data it’s been trained on and generate output.
When you try to use ChatGPT and a message pops up to say its servers are taking strain, it’s because the computing hardware is struggling to keep up with the demand for inference.
Nvidia says that its new software, TensorRT-LLM, can make its existing hardware run a whole lot faster and more energy-efficient too.
The software includes optimized versions of the most popular models including Meta Llama 2, OpenAI GPT-2 and GPT-3, Falcon, Mosaic MPT, and BLOOM.
It uses some clever techniques like more efficient batching of inference tasks and quantization techniques to achieve the performance boost.
LLMs generally use 16-bit floating point values to represent weights and activations. Quantization takes those values and reduces them to 8-bit floating point values during inference. Most models manage to retain their accuracy with this reduced precision.
Companies that have computing infrastructure based on Nvidia’s H100 GPUs can expect a huge improvement in inference performance without having to spend a cent by using TensorRT-LLM.
Nvidia used an example of running a small open source model, GPT-J 6, to summarize articles in the CNN/Daily Mail dataset. Its older A100 chip is used as the baseline speed and then compared to the H100 without and then with TensorRT-LLM.
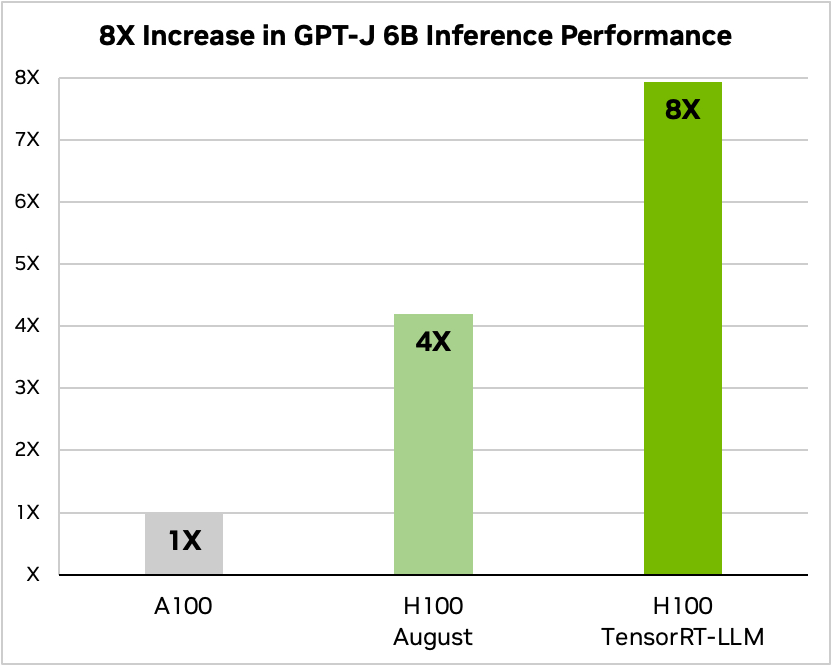
Source: Nvidia
And here’s a comparison when running Meta’s Llama 2
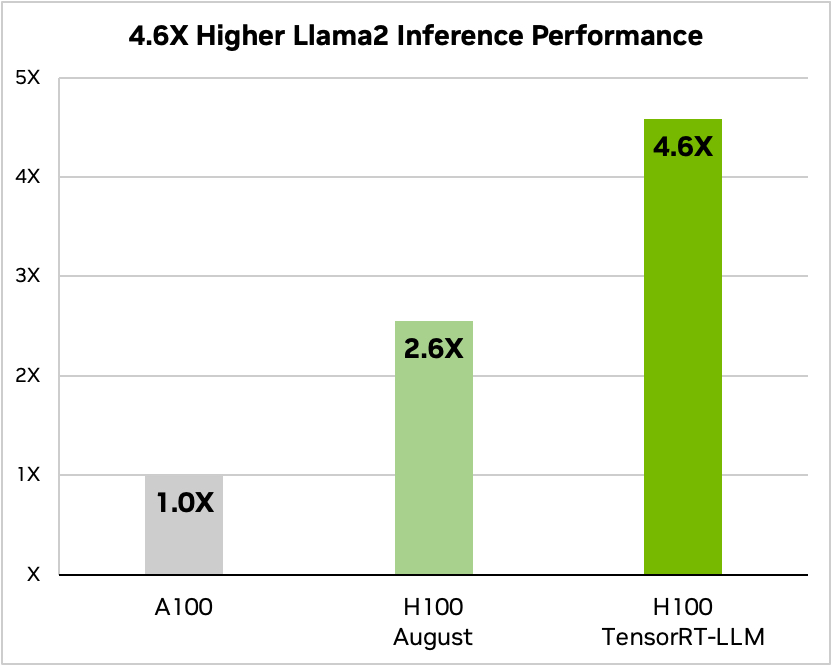
Source: Nvidia
Nvidia said its testing showed that, depending on the model, an H100 running TensorRT-LLM uses between 3.2 and 5.6 times less energy than an A100 during inference.
If you’re running AI models on H100 hardware this means that not only is your inference performance going to almost double, but your energy bill is going to be a whole lot less once you install this software.
TensorRT-LLM will also be made available for Nvidia’s Grace Hopper Superchips but the company hasn’t released performance figures for the GH200 running its new software.
The new software wasn’t yet ready when Nvidia put its GH200 Superchip through the industry-standard MLPerf AI performance benchmarking tests. The results showed that the GH200 performed up to 17% better than a single-chip H100 SXM.
If Nvidia achieves even a modest inference performance boost using TensorRT-LLM with the GH200, it will put the company way out in front of its nearest rivals. Being a sales rep for Nvidia must be the easiest job in the world right now.



