

Etter hvert som den generative AI-æraen skrider frem, har et bredt spekter av selskaper meldt seg på i kampen, og selve modellene har blitt stadig mer varierte.
Midt i denne AI-boomen har mange selskaper fremhevet modellene sine som "åpen kildekode", men hva betyr dette egentlig i praksis?
Begrepet åpen kildekode har sine røtter i programvareutviklingsmiljøet. Tradisjonell programvare med åpen kildekode gjør kildekoden fritt tilgjengelig for alle, slik at alle kan se, endre og distribuere den.
Åpen kildekode er i bunn og grunn en samarbeidsform for kunnskapsdeling som drives av programvareinnovasjon, noe som har ført til utvikling av blant annet operativsystemet Linux, nettleseren Firefox og programmeringsspråket Python.
Det er imidlertid langt fra enkelt å anvende åpen kildekode-etikken på dagens massive AI-modeller.
Disse systemene trenes ofte opp på enorme datasett som inneholder terabytes eller petabytes med data, ved hjelp av komplekse nevrale nettverksarkitekturer med milliarder av parametere.
Dataressursene som kreves, koster millioner av dollar, talentene er få, og immaterielle rettigheter er ofte godt beskyttet.
Dette kan vi observere i OpenAI, som, som navnet antyder, tidligere var et AI-forskningslaboratorium som i stor grad var dedikert til åpen forskning.
Det er imidlertid etos raskt erodert da selskapet luktet penger og trengte å tiltrekke seg investeringer for å nå sine mål.
Hvorfor er det slik? Fordi åpen kildekode-produkter ikke er innrettet mot profitt, og kunstig intelligens er dyrt og verdifullt.
Etter hvert som generativ AI har eksplodert, har imidlertid selskaper som Mistral, Meta, BLOOM og xAI lansert modeller med åpen kildekode for å fremme forskningen, samtidig som de hindrer selskaper som Microsoft og Google i å få for stor innflytelse.
Men hvor mange av disse modellene er egentlig åpen kildekode, og ikke bare av navn?
Klargjøre hvor åpne modeller med åpen kildekode egentlig er
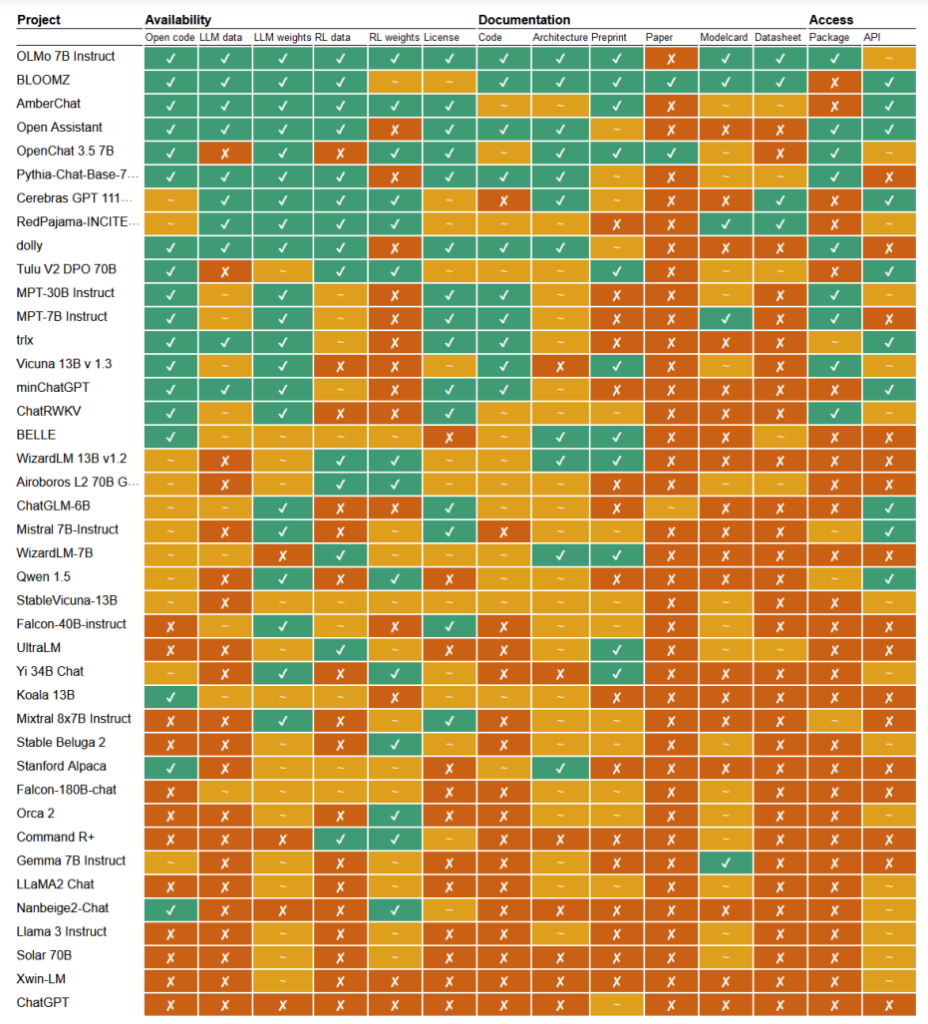
I en nylig publisert studieI en ny studie har forskerne Mark Dingemanse og Andreas Liesenfeld fra Radboud University i Nederland analysert en rekke fremtredende AI-modeller for å undersøke hvor åpne de er. De studerte flere kriterier, for eksempel tilgjengeligheten av kildekode, treningsdata, modellvekter, forskningsartikler og API-er.
For eksempel viste det seg at Metas LLaMA-modell og Googles Gemma rett og slett var "åpen vekt" - noe som betyr at den trente modellen er offentlig tilgjengelig for bruk uten full åpenhet om koden, opplæringsprosessen, dataene og finjusteringsmetodene.
I den andre enden av spekteret fremhevet forskerne BLOOM, en stor flerspråklig modell som er utviklet av et samarbeid mellom over 1000 forskere over hele verden, som et eksempel på ekte åpen kildekode-AI. Hvert eneste element i modellen er fritt tilgjengelig for inspeksjon og videre forskning.
Artikkelen vurderte mer enn 30 modeller (både tekst og bilde), men disse viser den enorme variasjonen blant de som hevder å være åpen kildekode:
- BloomZ (BigScience): Helt åpen på tvers av alle kriterier, inkludert kode, treningsdata, modellvekter, forskningsartikler og API. Fremhevet som et eksempel på AI med åpen kildekode.
- OLMo (Allen Institute for AI): Åpen kode, treningsdata, vekter og forskningsartikler. API bare delvis åpent.
- Mistral 7B-Instruct (Mistral AI): Åpne modellvekter og API. Kode og forskningsartikler bare delvis åpne. Treningsdata utilgjengelig.
- Orca 2 (Microsoft): Delvis åpne modellvekter og forskningsartikler. Kode, opplæringsdata og API lukket.
- Gemma 7B instruksjon (Google): Delvis åpen kode og vekter. Opplæringsdata, forskningsartikler og API lukket. Beskrevet som "åpen" av Google i stedet for "åpen kildekode".
- Llama 3 Instruksjon (Meta): Delvis åpne vekter. Kode, treningsdata, forskningsartikler og API lukket. Et eksempel på en "åpen vekt"-modell uten full åpenhet.
Mangel på åpenhet
Mangelen på åpenhet rundt AI-modeller, spesielt de som er utviklet av store teknologiselskaper, gir grunn til alvorlig bekymring når det gjelder ansvarlighet og tilsyn.
Uten full tilgang til modellens kode, treningsdata og andre nøkkelkomponenter blir det ekstremt utfordrende å forstå hvordan disse modellene fungerer og tar beslutninger. Dette gjør det vanskelig å identifisere og håndtere potensielle skjevheter, feil eller misbruk av opphavsrettslig beskyttet materiale.
Brudd på opphavsretten i AI-treningsdata er et godt eksempel på problemene som oppstår som følge av denne mangelen på åpenhet. Mange proprietære AI-modeller, som GPT-3.5/4/40/Claude 3/Gemini, er sannsynligvis trent på opphavsrettslig beskyttet materiale.
Men siden opplæringsdataene oppbevares under lås og slå, er det nesten umulig å identifisere spesifikke data i dette materialet.
New York Times' nylig søksmål mot OpenAI viser hvilke konsekvenser denne utfordringen kan få i den virkelige verden. OpenAI anklaget NYT for å ha brukt prompt engineering-angrep for å eksponere treningsdata og lokke ChatGPT til å gjengi artiklene ordrett, og dermed bevise at OpenAIs treningsdata inneholder opphavsrettslig beskyttet materiale.
"The Times betalte noen for å hacke OpenAIs produkter", uttalte OpenAI.
Ian Crosby, NYTs juridiske rådgiver, svarte: "Det OpenAI på merkelig vis feilaktig karakteriserer som 'hacking', er ganske enkelt å bruke OpenAIs produkter til å lete etter bevis på at de har stjålet og reprodusert The Times' opphavsrettsbeskyttede verk. Og det er akkurat det vi fant."
Dette er bare ett eksempel fra en stor bunke søksmål som for øyeblikket er blokkert, delvis på grunn av AI-modellenes ugjennomsiktige og ugjennomtrengelige natur.
Dette er bare toppen av isfjellet. Uten robuste tiltak for åpenhet og ansvarlighet risikerer vi en fremtid der uforklarlige AI-systemer tar beslutninger som har stor innvirkning på livene våre, økonomien og samfunnet, men som ikke blir gransket.
Oppfordrer til åpenhet
Det har vært oppfordringer til selskaper som Google og OpenAI om å gi tilgang til modellenes indre funksjoner i forbindelse med sikkerhetsevaluering.
Sannheten er imidlertid at selv AI-selskaper ikke helt forstår hvordan modellene deres fungerer.
Dette kalles "black box"-problemet, som oppstår når man prøver å tolke og forklare modellens spesifikke beslutninger på en måte som er forståelig for mennesker.
En utvikler kan for eksempel vite at en dyp læringsmodell er nøyaktig og gir gode resultater, men de kan slite med å finne ut nøyaktig hvilke funksjoner modellen bruker for å ta sine beslutninger.
Anthropic, som har utviklet Claude-modellene, har nylig gjennomførte et eksperiment for å identifisere hvordan Claude 3 Sonnet fungerer, og forklarer: "Vi behandler stort sett AI-modeller som en svart boks: Noe går inn og et svar kommer ut, og det er ikke klart hvorfor modellen ga akkurat det svaret i stedet for et annet. Dette gjør det vanskelig å stole på at disse modellene er trygge: Hvis vi ikke vet hvordan de fungerer, hvordan kan vi da vite at de ikke gir skadelige, partiske, usanne eller på annen måte farlige svar? Hvordan kan vi stole på at de er trygge og pålitelige?"
Det er egentlig en ganske bemerkelsesverdig innrømmelse at skaperen av en teknologi ikke forstår produktet sitt i AI-æraen.
Dette antropiske eksperimentet illustrerte at det er en usedvanlig vanskelig oppgave å forklare resultater objektivt. Anthropic anslo faktisk at det ville kreve mer datakraft å "åpne den svarte boksen" enn å trene opp selve modellen!
Utviklere forsøker aktivt å bekjempe black-box-problemet gjennom forskning som "Explainable AI" (XAI), som tar sikte på å utvikle teknikker og verktøy for å gjøre AI-modeller mer transparente og tolkbare.
XAI-metoder søker å gi innsikt i modellens beslutningsprosess, fremheve de mest innflytelsesrike funksjonene og generere forklaringer som kan leses av mennesker. XAI har allerede blitt brukt på modeller som brukes i bruksområder som legemiddelutviklinghvor det å forstå hvordan en modell fungerer, kan være avgjørende for sikkerheten.
Initiativer med åpen kildekode er avgjørende for XAI og annen forskning som søker å trenge gjennom den svarte boksen og gi innsyn i AI-modeller.
Uten tilgang til modellens kode, treningsdata og andre nøkkelkomponenter kan forskerne ikke utvikle og teste teknikker for å forklare hvordan AI-systemer virkelig fungerer og identifisere spesifikke data de er trent opp på.
Regelverket kan gjøre situasjonen for åpen kildekode enda mer uoversiktlig
Den europeiske unions nylig vedtatt AI Act er i ferd med å innføre nye regler for AI-systemer, med bestemmelser som spesifikt tar for seg modeller med åpen kildekode.
I henhold til loven vil generelle modeller med åpen kildekode opp til en viss størrelse være unntatt fra omfattende krav til åpenhet.
Men som Dingemanse og Liesenfeld påpeker i sin studie, er den nøyaktige definisjonen av "åpen kildekode-KI" i henhold til AI-loven fortsatt uklar og kan bli et stridspunkt.
Loven definerer i dag modeller med åpen kildekode som modeller som er utgitt under en "fri og åpen" lisens som gir brukerne mulighet til å endre modellen. Den spesifiserer likevel ikke krav til tilgang til treningsdata eller andre nøkkelkomponenter.
Denne tvetydigheten gir rom for tolkning og potensiell lobbyvirksomhet fra bedriftsinteresser. Forskerne advarer om at en presisering av definisjonen av åpen kildekode i AI-loven "sannsynligvis vil utgjøre et enkelt trykkpunkt som vil bli et mål for bedriftslobbyer og store selskaper".
Uten klare, robuste kriterier for hva som utgjør virkelig åpen kildekode-KI, er det en risiko for at regelverket utilsiktet kan skape smutthull eller insentiver for selskaper til å drive med "open-washing" - å hevde åpenhet for å oppnå juridiske og PR-messige fordeler, samtidig som viktige aspekter ved modellene deres fortsatt er proprietære.
Den globale karakteren til AI-utviklingen betyr dessuten at ulike regelverk på tvers av jurisdiksjoner kan komplisere landskapet ytterligere.
Hvis store AI-produsenter som USA og Kina har ulike tilnærminger til krav om åpenhet og innsyn, kan det føre til et fragmentert økosystem der graden av åpenhet varierer mye avhengig av hvor en modell kommer fra.
Forfatterne av studien understreker behovet for at lovgiverne samarbeider tett med forskningsmiljøer og andre interessenter for å sikre at eventuelle bestemmelser om åpen kildekode i AI-lovgivningen bygger på en dyp forståelse av teknologien og prinsippene for åpenhet.
Som Dingemanse og Liesenfeld konkluderer i en diskusjon med naturen"Det er rimelig å si at begrepet åpen kildekode vil få en helt ny juridisk tyngde i de landene som omfattes av EUs AI Act."
Hvordan dette utspiller seg i praksis, vil ha stor betydning for den fremtidige retningen for forskning på og bruk av kunstig intelligens.



