

Anthropic forskere har lykkes med å identifisere millioner av konsepter innenfor Claude Sonnet, en av deres avanserte LLM-er.
AI-modeller anses ofte som svarte bokser, noe som betyr at man ikke kan "se" inn i dem for å forstå nøyaktig hvordan de fungerer.
Når du gir en LLM en input, genererer den et svar, men det er uklart hva som ligger bak valgene.
Inndataene dine går inn, og resultatet kommer ut - og selv AI-utviklerne forstår ikke helt hva som skjer inne i denne "boksen".
Nevrale nettverk skaper sine egne interne representasjoner av informasjon når de tilordner inndata til utdata under datatreningen. Byggesteinene i denne prosessen, kalt "nevronaktiveringer", representeres av numeriske verdier.
Hvert begrep er fordelt på flere nevroner, og hver nevron bidrar til å representere flere begreper, noe som gjør det vanskelig å tilordne begreper direkte til enkeltnevroner.
Dette er i stor grad analogt med menneskehjernen. På samme måte som hjernen vår behandler sanseinntrykk og genererer tanker, atferd og minner, er de milliarder, til og med billioner, av prosesser som ligger bak disse funksjonene, stort sett ukjente for vitenskapen.
Anthropic's studie forsøker å se inn i AIs svarte boks med en teknikk som kalles "ordboklæring".
Dette innebærer å dekomponere komplekse mønstre i en AI-modell til lineære byggesteiner eller "atomer" som gir intuitiv mening for mennesker.
Kartlegging av LLM-er med ordboklæring
I oktober 2023, Anthropic brukte denne metoden på en liten "leke"-språkmodell og fant sammenhengende trekk som tilsvarte begreper som store bokstaver, DNA-sekvenser, etternavn i sitater, matematiske substantiver eller funksjonsargumenter i Python-kode.
Denne siste studien skalerer opp teknikken til å fungere for dagens større AI-språkmodeller, i dette tilfellet, Anthropic's Claude 3 Sonett.
Her er en trinnvis gjennomgang av hvordan studien fungerte:
Identifisere mønstre med ordboklæring
Anthropic brukte ordboklæring til å analysere nevronaktiveringer i ulike kontekster og identifisere felles mønstre.
Ordboklæring grupperer disse aktiveringene i et mindre sett med meningsfulle "funksjoner", som representerer begreper på høyere nivå som modellen har lært.
Ved å identifisere disse funksjonene kan forskerne bedre forstå hvordan modellen behandler og representerer informasjon.
Trekker ut funksjoner fra det midterste laget
Forskerne fokuserte på det midterste laget av Claude 3.0 Sonnet, som fungerer som et kritisk punkt i modellens prosesseringspipeline.
Ved å bruke ordboklæring på dette laget ekstraheres millioner av funksjoner som fanger opp modellens interne representasjoner og innlærte begreper på dette stadiet.
Ved å trekke ut funksjoner fra det midterste laget kan forskerne undersøke modellens forståelse av informasjon etter den har behandlet inndataene før som genererer det endelige resultatet.
Oppdage ulike og abstrakte begreper
De ekstraherte funksjonene avslørte et ekspansivt spekter av begreper lært av Claudefra konkrete enheter som byer og mennesker til abstrakte begreper knyttet til vitenskapelige felt og programmeringssyntaks.
Interessant nok viste det seg at funksjonene var multimodale og reagerte på både tekstlig og visuell input, noe som tyder på at modellen kan lære og representere begreper på tvers av ulike modaliteter.
I tillegg tyder de flerspråklige funksjonene på at modellen kan forstå begreper som er uttrykt på ulike språk.

Analysere organiseringen av konsepter
For å forstå hvordan modellen organiserer og relaterer ulike konsepter, analyserte forskerne likheten mellom funksjonene basert på aktiveringsmønstrene deres.
De oppdaget at funksjoner som representerte relaterte konsepter, hadde en tendens til å gruppere seg sammen. For eksempel viste det seg at funksjoner knyttet til byer eller vitenskapelige disipliner hadde større likhet med hverandre enn med funksjoner som representerte urelaterte konsepter.
Dette tyder på at modellens interne organisering av begreper til en viss grad samsvarer med menneskelige intuisjoner om konseptuelle relasjoner.
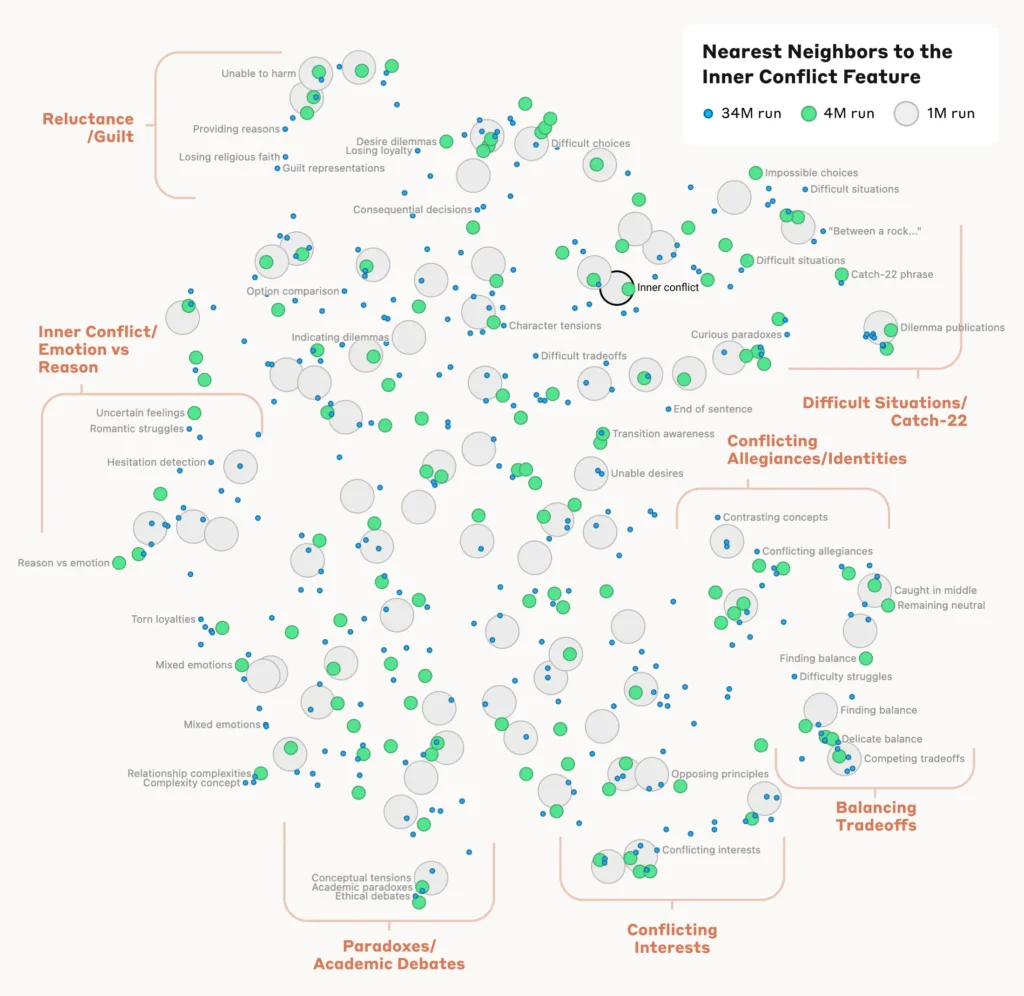
Verifisering av funksjonene
For å bekrefte at de identifiserte funksjonene påvirker modellens atferd og resultater direkte, utførte forskerne eksperimenter med "funksjonsstyring".
Dette innebar at man selektivt forsterket eller undertrykte aktiveringen av bestemte funksjoner under modellens prosessering, og observerte hvordan dette påvirket responsene.
Ved å manipulere individuelle funksjoner kunne forskerne etablere en direkte kobling mellom individuelle funksjoner og modellens atferd. For eksempel førte en forsterkning av en funksjon knyttet til en bestemt by til at modellen genererte bybaserte resultater, selv i irrelevante sammenhenger.
Les hele studien her.
Hvorfor tolkbarhet er avgjørende for AI-sikkerhet
Anthropic's forskning er grunnleggende relevant for AI-tolkbarhet og, i forlengelsen av dette, sikkerhet.
Ved å forstå hvordan LLM-er behandler og representerer informasjon, kan forskere bedre forstå og redusere risiko. Det legger grunnlaget for å utvikle mer transparente og forklarlige AI-systemer.
Som Anthropic "Vi håper at vi og andre kan bruke disse oppdagelsene til å gjøre modeller tryggere. Det kan for eksempel være mulig å bruke teknikkene som er beskrevet her, til å overvåke AI-systemer for farlig atferd (for eksempel å lure brukeren), til å styre dem mot ønskelige resultater (debiasing), eller til å fjerne visse farlige emner helt."
Å få en bedre forståelse av atferden til kunstig intelligens blir stadig viktigere etter hvert som de blir allestedsnærværende i kritiske beslutningsprosesser på områder som helse, finans og strafferett. Det bidrar også til å avdekke årsaken til skjevhet, hallusinasjoner og annen uønsket eller uforutsigbar atferd.
For eksempel kan en fersk undersøkelse fra Universitetet i Bonn avdekket hvordan grafnevrale nettverk (GNN) som brukes til legemiddeloppdagelse, i stor grad baserer seg på å gjenkalle likheter fra treningsdata i stedet for å lære seg nye, komplekse kjemiske interaksjoner.
Dette gjør det vanskelig å forstå nøyaktig hvordan disse modellene finner nye interessante forbindelser.
I fjor ble Den britiske regjeringen forhandlet med store teknologigiganter som OpenAI og DeepMindsom ønsker innsyn i AI-systemenes interne beslutningsprosesser.
Regulering som EUs lov om kunstig intelligens vil presse AI-selskapene til å være mer åpne, selv om forretningshemmeligheter ser ut til å forbli under lås og slå.
Anthropic's forskning gir et glimt av hva som befinner seg inne i boksen ved å "kartlegge" informasjon på tvers av modellen.
Sannheten er imidlertid at disse modellene er så omfattende at de ved Anthropic"Vi tror det er ganske sannsynlig at vi mangler mange størrelsesordener, og at hvis vi ønsket å få med alle funksjonene - i alle lag! - ville vi måtte bruke mye mer databehandling enn det som trengs for å trene opp de underliggende modellene."
Det er et interessant poeng - å reversere en modell er mer komplisert enn å konstruere modellen i utgangspunktet.
Det minner om enormt kostbare nevrovitenskapelige prosjekter som Human Brain Project (HBP)som brukte milliarder på å kartlegge vår egen menneskelige hjerne, men som til slutt mislyktes.
Undervurder aldri hvor mye som ligger inne i den svarte boksen.



