

Digitaler Kolonialismus bezieht sich auf die Dominanz von Tech-Giganten und mächtigen Unternehmen über die digitale Landschaft, die den Informations-, Wissens- und Kulturfluss im Sinne ihrer Interessen gestalten.
Bei dieser Dominanz geht es nicht nur um die Kontrolle der digitalen Infrastruktur, sondern auch um die Beeinflussung der Erzählungen und Wissensstrukturen, die unser digitales Zeitalter bestimmen.
Der digitale Kolonialismus und nun auch der KI-Kolonialismus sind weithin anerkannte Begriffe, und Institutionen wie MIT hat geforscht und geschrieben über sie ausgiebig.
Spitzenforscher von Anthropic, Google, DeepMind und anderen Technologieunternehmen haben offen über die begrenzten Möglichkeiten der KI für Menschen mit unterschiedlichem Hintergrund gesprochen, insbesondere in Bezug auf Vorspannung in maschinellen Lernsystemen.
Maschinenlernende Systeme fundamental die Daten widerspiegeln, auf denen sie trainiert wurden - Daten, die cist als ein Produkt unseres digitalen Zeitgeistes zu betrachten - eine Sammlung von vorherrschenden Erzählungen, Bildern und Ideen, die die Online-Welt beherrschen.
Aber wer darf diese Informationskräfte gestalten? Wessen Stimmen werden verstärkt und wessen abgeschwächt?
Wenn KI aus Trainingsdaten lernt, erbt sie bestimmte Weltanschauungen, die nicht unbedingt mit globalen Kulturen und Erfahrungen übereinstimmen oder diese repräsentieren. Darüber hinaus werden die Steuerungen, die den Output generativer KI-Tools bestimmen, durch zugrunde liegende soziokulturelle Vektoren geprägt.
Dies hat Entwickler wie Anthropic dazu veranlasst demokratische Methoden suchen das Verhalten der KI durch die öffentliche Meinung zu beeinflussen.
Wie Jack Clark, der Leiter der Anthropic-Politik, in einem jüngstes Experiment Wir versuchen, einen Weg zu finden, eine Verfassung zu entwickeln, die von einer ganzen Reihe von Dritten entwickelt wird, und nicht von Leuten, die zufällig in einem Labor in San Francisco arbeiten.
Die derzeitigen generativen KI-Trainingsparadigmen bergen die Gefahr, eine digitale Echokammer zu schaffen, in der dieselben Ideen, Werte und Perspektiven ständig verstärkt werden, wodurch die Dominanz derjenigen, die in den Daten bereits überrepräsentiert sind, noch weiter gefestigt wird.
Da die KI in die komplexe Entscheidungsfindung einfließt, von Sozialhilfe und Anwerbung zu Finanzentscheidungen und medizinische DiagnosenEine unausgewogene Vertretung führt zu Verzerrungen und Ungerechtigkeiten in der Realität.
Die Datensätze sind geografisch und kulturell verortet
Eine aktuelle Studie der Data Provenance Initiative untersuchte 1.800 populäre Datensätze für die Verarbeitung natürlicher Sprache (NLP), eine Disziplin der KI, die sich mit Sprache und Text befasst.
NLP ist die vorherrschende Methode des maschinellen Lernens, die hinter großen Sprachmodellen (LLMs) wie ChatGPT und den Llama-Modellen von Meta steht.
Die Studie zeigt eine westliche Ausrichtung der Sprachrepräsentation in den Datensätzen, wobei Englisch und westeuropäische Sprachen die Textdaten bestimmen.
Sprachen aus asiatischen, afrikanischen und südamerikanischen Ländern sind deutlich unterrepräsentiert.
Folglich können LLMs nicht darauf hoffen, die kulturell-sprachlichen Nuancen dieser Regionen in gleichem Maße zu repräsentieren wie westliche Sprachen.
Selbst wenn Sprachen aus dem globalen Süden vertreten sind, stammen Herkunft und Dialekt der Sprache in erster Linie von nordamerikanischen oder europäischen Autoren und Webquellen.

A vorheriges Anthropisches Experiment stellten fest, dass der Sprachwechsel in Modellen wie ChatGPT immer noch zu westlich geprägten Ansichten und Stereotypen in Gesprächen führte.
Die Anthropologie-Forscher kamen zu dem Schluss: "Wenn ein Sprachmodell bestimmte Meinungen unverhältnismäßig stark repräsentiert, besteht die Gefahr, dass es potenziell unerwünschte Auswirkungen hat, wie z. B. die Förderung hegemonialer Weltanschauungen und die Homogenisierung der Perspektiven und Überzeugungen der Menschen."
Die Data Provenance-Studie untersuchte auch die geografische Landschaft der Datensatzkuration. Akademische Organisationen sind mit 69% der Datensätze die Hauptakteure, gefolgt von Industrielabors (21%) und Forschungseinrichtungen (17%).
Die größten Beitragszahler sind AI2 (12,3%), die University of Washington (8,9%) und Facebook AI Research (8,4%).
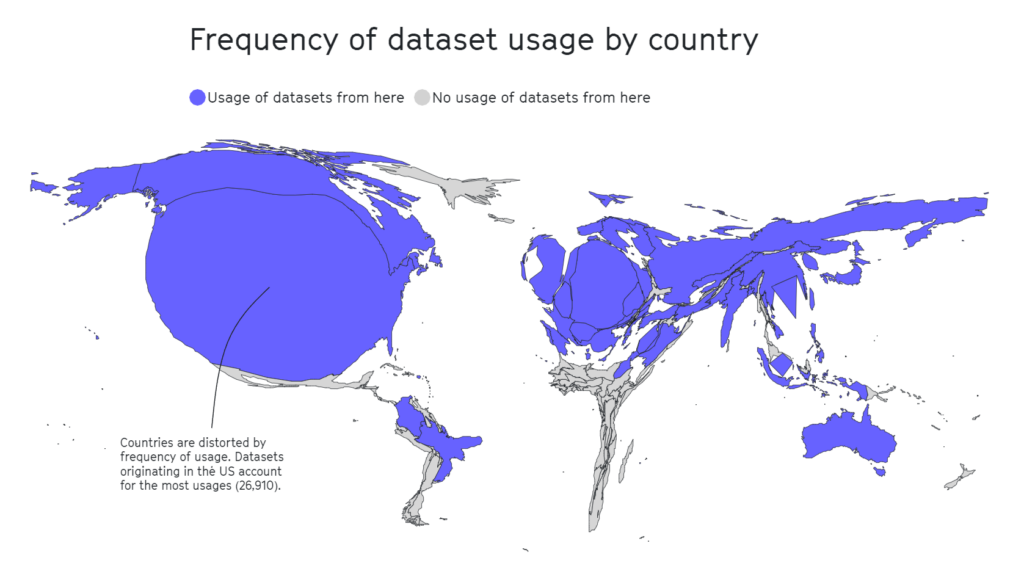
A separate Studie 2020 hebt hervor, dass die Hälfte der für die KI-Bewertung von rund 26 000 Forschungsartikeln verwendeten Datensätze von nur 12 Spitzenuniversitäten und Technologieunternehmen stammt.
Auch hier zeigte sich, dass geografische Gebiete wie Afrika, Süd- und Mittelamerika sowie Zentralasien stark unterrepräsentiert sind (siehe unten).
In anderen Forschungsarbeiten enthielten einflussreiche Datensätze wie MIT's Tiny Images oder Labeled Faces in the Wild vor allem weiße westliche männliche Bilder, mit etwa 77,5% männlichen und 83,5% weißhäutigen Individuen im Fall von Labeled Faces in the Wild.
Im Fall von Tiny Images, einer 2020 Analyse von The Register stellte fest, dass viele Tiny Images obszöne, rassistische und sexistische Bezeichnungen enthielten.
Antonio Torralba vom MIT sagte, dass man sich der Kennzeichnungen nicht bewusst gewesen sei und der Datensatz gelöscht wurde. Torralba sagte: "Es ist klar, dass wir sie manuell hätten überprüfen müssen.
Englisch dominiert das KI-Ökosystem
Pascale Fung, Informatikerin und Direktorin des Zentrums für KI-Forschung an der Hong Kong University of Science and Technology, erörterte die mit hegemonialer KI verbundenen Probleme.
Fung verweist auf mehr als 15 Forschungsarbeiten, in denen die mehrsprachige Kompetenz von LLM untersucht wurde und die durchweg zu dem Ergebnis kamen, dass sie insbesondere bei der Übersetzung aus dem Englischen in andere Sprachen Mängel aufweisen. Beispielsweise zeigen Sprachen mit nicht-lateinischer Schrift, wie Koreanisch, die Grenzen der LLMs auf.
Hinzu kommt die mangelhafte mehrsprachige Unterstützung, andere Studien legen nahe, dass die meisten Bias-Benchmarks und -Maßnahmen mit Blick auf englischsprachige Modelle entwickelt worden sind.
Es gibt nur wenige Benchmarks für nicht-englische Verzerrungen, was zu einer erheblichen Lücke in unserer Fähigkeit führt, Verzerrungen in mehrsprachigen Sprachmodellen zu bewerten und zu korrigieren.
Es gibt Anzeichen für Verbesserungen, wie die Bemühungen von Google mit seinem PaLM 2-Sprachmodell und Metas Massiv mehrsprachige Sprache (MMS) das mehr als 4.000 gesprochene Sprachen erkennen kann, 40 Mal mehr als andere Ansätze. MMS bleibt jedoch experimentell.
Forscher erstellen vielfältige, mehrsprachige Datensätze, aber die überwältigende Menge an englischen Textdaten, die oft kostenlos und leicht zugänglich sind, macht sie de facto zur ersten Wahl für Entwickler.
Jenseits von Daten: Strukturelle Fragen der KI-Arbeit
MITs umfassender Überblick über den KI-Kolonialismus lenkte die Aufmerksamkeit auf einen relativ verborgenen Aspekt der KI-Entwicklung - ausbeuterische Arbeitspraktiken.
KI hat zu einem starken Anstieg der Nachfrage nach Datenetikettierungsdiensten geführt. Unternehmen wie Appen und Sama haben sich als wichtige Akteure etabliert und bieten Dienstleistungen zur Kennzeichnung von Texten, Bildern und Videos, zur Sortierung von Fotos und zur Transkription von Audiodaten an, um maschinelle Lernmodelle zu speisen.
Menschliche Datenspezialisten kennzeichnen auch manuell Inhaltstypen, oft um Daten zu sortieren, die illegale, unerlaubte oder unethische Inhalte enthalten, wie Beschreibungen von sexuellem Missbrauch, schädlichem Verhalten oder anderen illegalen Aktivitäten.
Auch wenn KI-Unternehmen einige dieser Prozesse automatisieren, ist es nach wie vor unerlässlich, dass der Mensch in der Schleife bleibt, um die Genauigkeit der Modelle und die Einhaltung der Sicherheitsvorschriften zu gewährleisten.
Der Marktwert dieser "Geisterarbeit", wie sie von der Anthropologin Mary Gray und dem Sozialwissenschaftler Siddharth Suri bezeichnet wird, wird auf bis 2030 auf $13,7 Milliarden ansteigen.
Bei der Schwarzarbeit werden häufig billige Arbeitskräfte ausgebeutet, insbesondere aus wirtschaftlich schwachen Ländern. Venezuela zum Beispiel ist aufgrund seiner Wirtschaftskrise zu einer Hauptquelle für KI-Arbeitskräfte geworden.
Als das Land mit der schlimmsten Wirtschaftskatastrophe in Friedenszeiten und einer astronomischen Inflation zu kämpfen hatte, wandte sich ein beträchtlicher Teil der gut ausgebildeten und mit dem Internet verbundenen Bevölkerung an Crowdworking-Plattformen, um zu überleben.
Das Zusammentreffen von gut ausgebildeten Arbeitskräften und wirtschaftlicher Verzweiflung machte Venezuela zu einem attraktiven Markt für Data-Labeling-Unternehmen.
Dies ist kein kontroverser Punkt - wenn das MIT Artikel mit Titeln wie "Künstliche Intelligenz schafft eine neue koloniale WeltordnungEs ist klar, dass einige in der Branche versuchen, den Vorhang über diese hinterhältigen Arbeitspraktiken zu lüften.
Wie das MIT berichtet, war die aufblühende KI-Industrie für viele Venezolaner ein zweischneidiges Schwert. Während sie inmitten der Verzweiflung eine wirtschaftliche Rettungsleine bot, setzte sie die Menschen auch der Ausbeutung aus.
Julian Posada, Doktorand an der Universität von Toronto, weist auf das "enorme Machtgefälle" in diesen Arbeitsverhältnissen hin. Die Plattformen diktieren die Regeln und lassen die Arbeitnehmer mit wenig Mitspracherecht und begrenzter finanzieller Entschädigung zurück, obwohl sie am Arbeitsplatz Herausforderungen ausgesetzt sind, z. B. verstörenden Inhalten.
Diese Dynamik erinnert auf unheimliche Weise an historische koloniale Praktiken, bei denen Imperien die Arbeitskraft anfälliger Länder ausbeuteten, Gewinne abschöpften und sie verließen, sobald die Gelegenheit schwand, oft weil es anderswo "bessere Werte" gab.
Ähnliche Situationen wurden in Nairobi, Kenia, beobachtet, wo eine Gruppe ehemaliger Moderatoren, die für ChatGPT eine Petition eingereicht mit der kenianischen Regierung.
Sie beriefen sich auf "ausbeuterische Bedingungen" während ihrer Tätigkeit bei Sama, einem in den USA ansässigen Unternehmen für Datenannotationsdienste, das von OpenAI beauftragt wurde. Die Petenten behaupteten, dass sie beunruhigenden Inhalten ohne angemessene psychosoziale Unterstützung ausgesetzt waren, was zu schweren psychischen Problemen, einschließlich PTBS, Depressionen und Angstzuständen, führte.

Dokumente bewertet von TIME dass OpenAI mit Sama Verträge im Wert von rund $200.000 abgeschlossen hat. Diese Verträge beinhalteten die Kennzeichnung von Beschreibungen von sexuellem Missbrauch, Hassreden und Gewalt.
Die Auswirkungen auf die psychische Gesundheit der Arbeitnehmer waren gravierend. Mophat Okinyi, ein ehemaliger Moderator, sprach über den psychologischen Tribut und beschrieb, wie der Kontakt mit grafischen Inhalten zu Paranoia, Isolation und erheblichen persönlichen Verlusten führte.
Die Löhne für eine derart belastende Arbeit waren schockierend niedrig - ein Sprecher von Sama gab an, dass die Arbeiter zwischen $1,46 und $3,74 pro Stunde verdienten.
Widerstand gegen den digitalen Kolonialismus
Wenn die KI-Industrie zu einer neuen Grenze des digitalen Kolonialismus geworden ist, dann wird der Widerstand schon jetzt kohärenter.
Aktivisten, die oft von KI-Forschern unterstützt werden, setzen sich für Rechenschaftspflicht, politische Veränderungen und die Entwicklung von Technologien ein, die den Bedürfnissen und Rechten lokaler Gemeinschaften Vorrang einräumen.
Nanjala Nyabola's Kiswahili-Projekt für digitale Rechte bietet ein innovatives Beispiel dafür, wie lokale Basisprojekte die Infrastruktur schaffen können, die erforderlich ist, um Gemeinschaften vor digitaler Hegemonie zu schützen.
Das Projekt berücksichtigt die Hegemonie westlicher Vorschriften bei der Definition der digitalen Rechte einer Gruppe, da nicht jeder durch die Gesetze zum Schutz des geistigen Eigentums, des Urheberrechts und der Privatsphäre geschützt ist, die viele von uns als selbstverständlich ansehen. Dadurch sind erhebliche Teile der Weltbevölkerung der Ausbeutung durch Technologieunternehmen ausgesetzt.
Nyabola und ihr Team haben erkannt, dass Diskussionen über digitale Rechte nur dann geführt werden können, wenn die Menschen sich nicht in ihrer Muttersprache verständigen können, und übersetzten die wichtigsten Begriffe zu digitalen Rechten und Technologien in die Sprache Kisuaheli, die hauptsächlich in Tansania, Kenia und Mosambik gesprochen wird.
Nyabola Beschreibung des ProjektsWährend dieses Prozesses [der Huduma-Namba-Initiative] hatten wir nicht wirklich die Sprache und die Mittel, um nicht spezialisierten oder nicht Englisch sprechenden Gemeinschaften in Kenia zu erklären, was die Initiative bedeutete.
Im Rahmen eines ähnlichen Basisprojekts verfügte Te Hiku Media, ein gemeinnütziger Radiosender, der hauptsächlich in der Māori-Sprache sendet, über eine riesige Datenbank mit jahrzehntelangen Aufnahmen, von denen viele die Stimmen der nicht mehr gesprochenen Redewendungen der Vorfahren widerspiegeln.
Herkömmliche Spracherkennungsmodelle, ähnlich wie LLMs, neigen dazu, zu wenig zu leisten, wenn sie in verschiedenen Sprachen oder englischen Dialekten abgefragt werden.
Die Te Hiku Medien hat mit Forschern und Open-Source-Technologien zusammengearbeitet, um ein auf die Māori-Sprache zugeschnittenes Spracherkennungsmodell zu trainieren. Der Māori-Aktivist Te Mihinga Komene steuerte etwa 4.000 Sätze bei, während unzählige andere an dem Projekt teilnahmen.
Die resultierendes Modell und Daten sind geschützt durch das Kaitiakitanga Lizenz - Kaitiakitanga ist ein Māori-Wort ohne spezifische englische Definition, bedeutet aber so viel wie "Wächter" oder "Hüter".
Keoni Mahelona, ein Mitbegründer von Te Hiku Media, bemerkte treffend: "Daten sind die letzte Grenze der Kolonisierung".
Diese Projekte haben andere indigene und einheimische Gemeinschaften inspiriert, die unter dem Druck des digitalen Kolonialismus und anderer Formen des sozialen Umbruchs stehen, wie etwa die Mohawk-Völker in Nordamerika und die Ureinwohner Hawaiis.
Da Open-Source-KI billiger und leichter zugänglich wird, sollte die Iteration und Feinabstimmung von Modellen mit einzigartigen lokalisierten Datensätzen einfacher werden, was den kulturübergreifenden Zugang zu dieser Technologie verbessert.
Auch wenn die KI-Branche noch jung ist, ist es jetzt an der Zeit, diese Herausforderungen zu thematisieren, damit die Menschen gemeinsam Lösungen entwickeln können.
Lösungen können sowohl auf der Makroebene in Form von Vorschriften, politischen Maßnahmen und Schulungsansätzen für das maschinelle Lernen als auch auf der Mikroebene in Form von lokalen und basisorientierten Projekten gefunden werden.
Gemeinsam können Forscher, Aktivisten und lokale Gemeinschaften Methoden finden, die sicherstellen, dass KI allen zugute kommt.



