

Das Zeitalter der künstlichen Intelligenz stellt ein komplexes Zusammenspiel zwischen Technologie und gesellschaftlicher Einstellung dar.
Die zunehmende Raffinesse von KI-Systemen lässt die Grenzen zwischen Mensch und Maschine verschwimmen - ist die KI-Technologie von uns getrennt? Inwieweit erbt die KI neben Fähigkeiten und Wissen auch menschliche Schwächen und Unzulänglichkeiten?
Es ist vielleicht verlockend, sich KI als eine empirische Technologie vorzustellen, die durch die Objektivität von Mathematik, Code und Berechnungen unterstrichen wird.
Wir haben jedoch erkannt, dass die von KI-Systemen getroffenen Entscheidungen sehr subjektiv sind und auf den Daten beruhen, denen sie ausgesetzt sind - und Menschen entscheiden, wie sie diese Daten auswählen und zusammenstellen.
Darin liegt eine Herausforderung, denn die KI-Trainingsdaten verkörpern oft die Vorurteile, die Voreingenommenheit und die Diskriminierung, die die Menschheit bekämpft.
Selbst scheinbar subtile Formen unbewusster Voreingenommenheit können durch das Modelltraining verstärkt werden und sich schließlich in Form von falschen Gesichtsübereinstimmungen bei der Strafverfolgung, verweigerten Krediten, Fehldiagnosen von Krankheiten und beeinträchtigten Sicherheitsmechanismen für selbstfahrende Fahrzeuge usw. äußern.
Die Versuche der Menschheit, Diskriminierung in der Gesellschaft zu verhindern, sind noch nicht abgeschlossen, aber die KI treibt die Entscheidungsfindung schon jetzt entscheidend voran.
Können wir schnell genug arbeiten, um KI mit modernen Werten zu synchronisieren und einseitige, lebensverändernde Entscheidungen und Verhaltensweisen zu verhindern?
Voreingenommenheit in der KI enträtseln
Im letzten Jahrzehnt haben KI-Systeme bewiesen, dass sie gesellschaftliche Vorurteile widerspiegeln.
Diese Systeme sind nicht von Natur aus voreingenommen, sondern nehmen die Voreingenommenheit ihrer Schöpfer und der Daten, auf denen sie trainiert wurden, auf.
KI-Systeme lernen wie Menschen, indem sie sich ihnen aussetzen. Das menschliche Gehirn ist ein scheinbar unendlicher Index von Informationen - eine Bibliothek mit nahezu unbegrenzten Regalen, in denen wir Erfahrungen, Wissen und Erinnerungen speichern.
Neurowissenschaftlich Studien zeigen, dass das Gehirn nicht wirklich eine "maximale Kapazität" hat und bis ins hohe Alter Informationen sortiert und speichert.
Der progressive, iterative Lernprozess des Gehirns ist zwar alles andere als perfekt, aber er hilft uns, uns an neue kulturelle und gesellschaftliche Werte anzupassen - vom Wahlrecht für Frauen über die Akzeptanz unterschiedlicher Identitäten bis hin zur Abschaffung der Sklaverei und anderer Formen bewusster Vorurteile.
Wir leben heute in einem Zeitalter, in dem KI-Tools anstelle des menschlichen Urteilsvermögens für wichtige Entscheidungen eingesetzt werden.
Viele Modelle des maschinellen Lernens (ML) lernen aus Trainingsdaten, die die Grundlage für ihre Entscheidungsfindung bilden, und können neue Informationen nicht so effizient aufnehmen wie das menschliche Gehirn. Daher können sie oft nicht die aktuellen, minutengenauen Entscheidungen treffen, die wir von ihnen erwarten.
So werden beispielsweise KI-Modelle zur Identifizierung von Gesichtsübereinstimmungen für Strafverfolgungszwecke eingesetzt, Analyse von Lebensläufen für Bewerbungen, und treffen gesundheitsrelevante Entscheidungen im klinischen Umfeld.
Da die Gesellschaft die KI immer weiter in unseren Alltag einbindet, müssen wir sicherstellen, dass sie für alle gleich und genau ist.
Dies ist derzeit nicht der Fall.
Fallstudien zu KI-Voreingenommenheit
In der Praxis gibt es zahlreiche Beispiele für Vorurteile, Vorverurteilungen und Diskriminierung im Zusammenhang mit KI.
In einigen Fällen sind die Auswirkungen von KI-Voreingenommenheit lebensverändernd, während sie in anderen Fällen im Hintergrund verbleiben und Entscheidungen subtil beeinflussen.
1. Die Verzerrung des MIT-Datensatzes
Ein MIT-Trainingsdatensatz aus dem Jahr 2008 namens Winzige Bilder enthielt etwa 80.000.000 Bilder in rund 75.000 Kategorien.
Ursprünglich sollte es KI-Systemen das Erkennen von Personen und Objekten in Bildern beibringen und wurde zu einem beliebten Benchmarking-Datensatz für verschiedene Anwendungen im Bereich der Computer Vision (CV).
A 2020 Analyse von The Register festgestellt, dass viele Tiny Images enthielt obszöne, rassistische und sexistische Aufschriften.
Antonio Torralba vom MIT sagte, das Labor sei sich dieser anstößigen Bezeichnungen nicht bewusst gewesen und erklärte gegenüber The Register: "Es ist klar, dass wir sie manuell hätten überprüfen müssen." Das MIT veröffentlichte später eine Erklärung, in der es mitteilte, dass es den Datensatz aus dem Verkehr gezogen habe.

Dies ist nicht das einzige Mal, dass ein ehemaliger Benchmark-Datensatz mit Problemen behaftet ist. Der Datensatz "Labeled Faces in the Wild" (LFW), ein Datensatz mit Gesichtern von Prominenten, der häufig für Gesichtserkennungsaufgaben verwendet wird, besteht aus 77,5% männlichen und 83,5% weißhäutigen Personen.
Viele dieser altgedienten Datensätze fanden ihren Weg in moderne KI-Modelle, stammen aber aus einer Ära der KI-Entwicklung, in der der Schwerpunkt auf der Entwicklung von Systemen lag, die einfach arbeiten und nicht solche, die für den Einsatz in realen Szenarien geeignet sind.
Ist ein KI-System erst einmal auf einen solchen Datensatz trainiert, hat es nicht unbedingt das gleiche Privileg wie das menschliche Gehirn, sich auf aktuelle Werte einzustellen.
Modelle können zwar iterativ aktualisiert werden, aber das ist ein langsamer und unvollkommener Prozess, der nicht mit dem Tempo der menschlichen Entwicklung mithalten kann.
2: Bilderkennung: Vorurteile gegenüber dunkelhäutigen Personen
Im Jahr 2019 wird die US-Regierung gefunden dass leistungsstarke Gesichtserkennungssysteme Schwarze 5 bis 10 Mal häufiger falsch identifizieren als Weiße.
Es handelt sich dabei nicht nur um eine statistische Anomalie, sondern hat auch schwerwiegende Auswirkungen in der Praxis: von Google Fotos, die schwarze Menschen als Gorillas identifizieren, bis hin zu selbstfahrenden Autos, die dunkelhäutige Menschen nicht erkennen und in sie hineinfahren.
Darüber hinaus gab es eine Reihe unrechtmäßiger Verhaftungen und Inhaftierungen, die mit falschen Gesichtsübereinstimmungen zusammenhingen, vielleicht am häufigsten Nijeer Parks'. der fälschlicherweise des Ladendiebstahls und des Straßenverkehrsdelikts beschuldigt wurde, obwohl er 30 Meilen von dem Vorfall entfernt war. Parks verbrachte daraufhin 10 Tage im Gefängnis und musste Tausende von Gerichtskosten zahlen.

Die einflussreiche Studie von 2018, Gender-FarbenDie Studie untersuchte außerdem algorithmische Verzerrungen. Die Studie analysierte Algorithmen von IBM und Microsoft und stellte fest, dass die Fehlerquote bei dunkelhäutigen Frauen bis zu 34% höher war als bei hellhäutigen Männern.
Dieses Muster wurde bei 189 verschiedenen Algorithmen festgestellt.
Das nachstehende Video der leitenden Forscherin Joy Buolamwini bietet einen ausgezeichneten Leitfaden dafür, wie die Leistung der Gesichtserkennung je nach Hautfarbe variiert.
3: Das CLIP-Projekt von OpenAI
OpenAIs CLIP-Projektdie 2021 veröffentlicht wurde und Bilder mit beschreibendem Text abgleichen soll, zeigte ebenfalls die anhaltenden Probleme mit Verzerrungen.
In einem Audit-Papier wiesen die CLIP-Macher auf ihre Bedenken hin: "CLIP hat einige Bezeichnungen, die hochrangige Berufe beschreiben, überproportional oft an Männer vergeben, wie z. B. 'Führungskraft' und 'Arzt'. Dies ähnelt den Verzerrungen, die bei Google Cloud Vision (GCV) festgestellt wurden, und deutet auf historische geschlechtsspezifische Unterschiede hin."
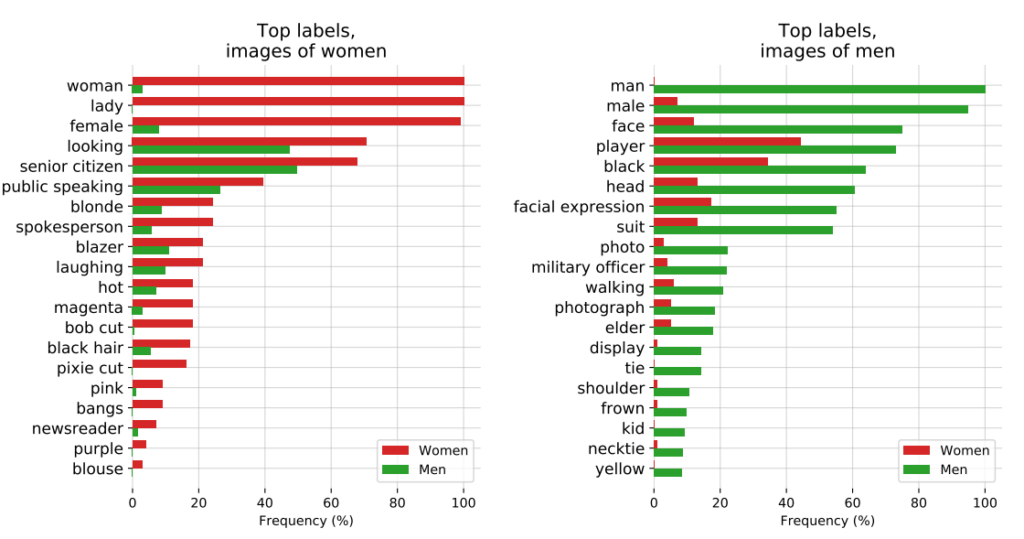
4: Strafverfolgung: die PredPol-Kontroverse
Ein weiteres Beispiel für algorithmische Voreingenommenheit, bei dem viel auf dem Spiel steht, ist PredPolein Algorithmus zur vorausschauenden Polizeiarbeit, der von verschiedenen Polizeidienststellen in den Vereinigten Staaten eingesetzt wird.
PredPol wurde anhand historischer Verbrechensdaten trainiert, um künftige Kriminalitätsschwerpunkte vorherzusagen.
Da diese Daten jedoch inhärent voreingenommene Polizeipraktiken widerspiegeln, wurde der Algorithmus dafür kritisiert, dass er die Erstellung von Rassenprofilen aufrechterhält und unverhältnismäßig viele Minderheitenviertel ins Visier nimmt.
5: Voreingenommenheit in der Dermatologie AI
Im Gesundheitswesen werden die potenziellen Risiken der KI-Voreingenommenheit noch deutlicher.
Nehmen wir das Beispiel der KI-Systeme, die zur Erkennung von Hautkrebs entwickelt wurden. Viele dieser Systeme werden anhand von Datensätzen trainiert, die überwiegend aus hellhäutigen Personen bestehen.
A 2021 Studie der Universität von Oxford untersuchten 21 frei zugängliche Datensätze auf Bilder von Hautkrebs. Sie entdeckten, dass von den 14 Datensätzen, die ihre geografische Herkunft offenlegten, 11 ausschließlich aus Bildern aus Europa, Nordamerika und Ozeanien bestanden.
Nur 2.436 der 106.950 Bilder in den 21 Datenbanken enthielten Angaben zum Hauttyp. Die Forscher stellten fest, dass "nur 10 Bilder von Personen mit brauner Haut und eines von einer Person mit dunkelbrauner oder schwarzer Haut aufgenommen wurden".
Was die Angaben zur ethnischen Zugehörigkeit betrifft, so enthielten nur 1.585 Bilder diese Informationen. Die Forscher stellten fest, dass "keine Bilder von Personen mit afrikanischem, afrikanisch-karibischem oder südasiatischem Hintergrund" stammten.
Sie kamen zu dem Schluss, dass "in Verbindung mit der geografischen Herkunft der Datensätze eine massive Unterrepräsentation von Bildern mit Hautläsionen aus dunkelhäutigen Bevölkerungsgruppen festzustellen war".
Wenn solche KI im klinischen Umfeld eingesetzt werden, besteht aufgrund der verzerrten Datensätze ein sehr reales Risiko von Fehldiagnosen.
Analyse von Verzerrungen in KI-Trainingsdaten: ein Produkt ihrer Schöpfer?
Trainingsdaten - meist Text-, Sprach-, Bild- und Videodaten - bieten einem überwachten Modell für maschinelles Lernen (ML) eine Grundlage für das Lernen von Konzepten.
KI-Systeme sind zu Beginn nichts anderes als leere Leinwände. Sie lernen und bilden Assoziationen auf der Grundlage unserer Daten, wobei sie im Wesentlichen ein Bild der Welt malen, wie es von ihren Trainingsdaten dargestellt wird.
Durch das Lernen aus Trainingsdaten hofft man, dass das Modell die gelernten Konzepte auf neue, ungesehene Daten anwenden kann.
Sobald sie eingesetzt werden, können einige fortgeschrittene Modelle aus neuen Daten lernen, aber ihre Trainingsdaten bestimmen immer noch ihre grundlegende Leistung.
Die erste Frage, die es zu beantworten gilt, lautet: Woher stammen die Daten? Daten, die aus nicht repräsentativen, oft homogenen und historisch ungleichen Quellen stammen, sind problematisch.
Dies gilt wahrscheinlich für eine beträchtliche Menge von Online-Daten, einschließlich Text- und Bilddaten, die aus "offenen" oder "öffentlichen" Quellen stammen.
Das Internet, das erst vor wenigen Jahrzehnten entwickelt wurde, ist kein Allheilmittel für das menschliche Wissen und weit davon entfernt, gerecht zu sein. Die Hälfte der Welt nutzt das Internet nicht, geschweige denn leistet einen Beitrag dazu, was bedeutet, dass es die globale Gesellschaft und Kultur im Grunde nicht repräsentiert.
Und obwohl die KI-Entwickler ständig daran arbeiten, die Vorteile der Technologie nicht auf die englischsprachige Welt zu beschränken, werden die meisten Trainingsdaten (Text und Sprache) in englischer Sprache produziert - was bedeutet, dass englischsprachige Mitarbeiter die Modellausgabe steuern.
Forscher von Anthropic haben kürzlich ein Papier veröffentlicht zu genau diesem Thema und kommt zu dem Schluss: "Wenn ein Sprachmodell bestimmte Meinungen unverhältnismäßig stark repräsentiert, besteht die Gefahr, dass es potenziell unerwünschte Auswirkungen hat, wie die Förderung hegemonialer Weltanschauungen und die Homogenisierung der Perspektiven und Überzeugungen der Menschen".
Letztlich funktionieren KI-Systeme zwar auf der Grundlage "objektiver" Prinzipien der Mathematik und der Programmierung, sie existieren jedoch in einem zutiefst subjektiven sozialen Kontext und werden von diesem geprägt.
Mögliche Lösungen für algorithmische Verzerrungen
Wenn Daten das Grundproblem sind, scheint die Lösung für die Entwicklung gerechter Modelle einfach: Man macht einfach ausgewogenere Datensätze, richtig?
Nicht ganz. A Studie 2019 hat gezeigt, dass der Abgleich von Datensätzen unzureichend ist, da Algorithmen immer noch unverhältnismäßig stark auf geschützte Merkmale wie Geschlecht und Rasse einwirken.
Die Autoren schreiben: "Überraschenderweise zeigen wir, dass selbst bei ausgeglichenen Datensätzen, bei denen jedes Label gleich häufig mit jedem Geschlecht vorkommt, die gelernten Modelle die Assoziation zwischen Label und Geschlecht genauso stark verstärken, wie wenn die Daten nicht ausgeglichen wären!"
Sie schlagen eine Entschärfungstechnik vor, bei der solche Kennzeichnungen vollständig aus dem Datensatz entfernt werden. Andere Techniken umfassen das Hinzufügen von zufälligen Störungen und Verzerrungen, die die Aufmerksamkeit eines Algorithmus auf bestimmte geschützte Merkmale verringern.
Auch wenn die Modifizierung von Trainingsmethoden für das maschinelle Lernen und die Optimierung für die Erzeugung unvoreingenommener Ergebnisse unabdingbar sind, sind fortgeschrittene Modelle anfällig für Veränderungen oder "Drift", d. h. ihre Leistung bleibt nicht unbedingt langfristig konstant.
Ein Modell kann bei der Einführung völlig unvoreingenommen sein, aber später mit zunehmender Exposition gegenüber neuen Daten verzerrt werden.
Die Bewegung für algorithmische Transparenz
In ihrem provokativen Buch Künstliche Unintelligenz: Wie Computer die Welt missverstehenMeredith Broussard plädiert für mehr "algorithmische Transparenz", um KI-Systeme auf mehreren Ebenen einer ständigen Überprüfung zu unterziehen.
Dies bedeutet, dass klare Informationen darüber bereitgestellt werden müssen, wie das System funktioniert, wie es trainiert wurde und mit welchen Daten es trainiert wurde.
Während Transparenzinitiativen leicht in die Open-Source-KI-Landschaft aufgenommen werden, sind proprietäre Modelle wie GPT, Bard und Anthropic's Claude "Black Boxes", und nur ihre Entwickler wissen genau, wie sie funktionieren - und selbst das ist umstritten.
Das "Blackbox"-Problem in der KI bedeutet, dass externe Beobachter nur sehen, was in das Modell hineingeht (Eingaben) und was herauskommt (Ausgaben). Die inneren Mechanismen sind außer ihren Schöpfern völlig unbekannt - ähnlich wie der magische Zirkel die Geheimnisse der Zauberer schützt. Die KI zieht einfach das Kaninchen aus dem Hut.
Die Blackbox-Problematik kristallisierte sich kürzlich durch Berichte über Der mögliche Leistungsabfall von GPT-4. GPT-4-Benutzer argumentieren, dass die Fähigkeiten des Modells rapide abgenommen haben, und während OpenAI bestätigt, dass dies wahr ist, haben sie nicht ganz klar gemacht, warum das passiert. Das wirft die Frage auf, ob sie es überhaupt wissen.
Der KI-Forscher Dr. Sasha Luccioni sagt, dass die mangelnde Transparenz von OpenAI ein Problem ist, das auch für andere proprietäre oder geschlossene KI-Modellentwickler gilt. "Alle Ergebnisse von Closed-Source-Modellen sind nicht reproduzierbar und nicht überprüfbar, und daher vergleichen wir aus wissenschaftlicher Sicht Waschbären und Eichhörnchen.
“Es liegt nicht an den Wissenschaftlern, die eingesetzten LLMs ständig zu überwachen. Es ist die Aufgabe der Modellentwickler, Zugang zu den zugrunde liegenden Modellen zu gewähren, zumindest für Prüfungszwecke", sagte sie.
Luccioni betonte, dass die Entwickler von KI-Modellen Rohergebnisse von Standard-Benchmarks wie SuperGLUE und WikiText sowie von Bias-Benchmarks wie BOLD und HONEST bereitstellen sollten.
Der Kampf gegen KI-gesteuerte Voreingenommenheit und Vorurteile wird wahrscheinlich ein ständiger sein und erfordert ständige Aufmerksamkeit und Forschung, um die Ergebnisse der Modelle in Schach zu halten, während sich KI und Gesellschaft gemeinsam weiterentwickeln.
Während die Regulierung Formen der Überwachung und Berichterstattung vorschreiben wird, gibt es nur wenige feste und schnelle Lösungen für das Problem der algorithmischen Verzerrung, und wir werden nicht zum letzten Mal davon hören.



