

Researchers released a benchmark to measure whether an LLM contains potentially hazardous knowledge and a novel technique for unlearning dangerous data.
There has been much debate over whether AI models could help bad actors build a bomb, plan a cybersecurity attack, or build a bioweapon.
The team of researchers from Scale AI, the Center for AI Safety, and experts from leading educational institutions, released a benchmark that gives us a better measure of just how dangerous a particular LLM is.
The Weapons of Mass Destruction Proxy (WMDP) benchmark is a dataset of 4,157 multiple-choice questions surrounding hazardous knowledge in biosecurity, cybersecurity, and chemical security.
The higher an LLM scores on the benchmark, the more danger it presents in potentially enabling a person with criminal intent. An LLM with a lower WMDP score is less likely to help you build a bomb or create a new virus.
The traditional way of making an LLM more aligned is to refuse requests that ask for data that could enable malicious actions. Jailbreaking or fine-tuning an aligned LLM could remove these guardrails and expose dangerous knowledge in the model’s dataset.
If you could make the model forget, or unlearn the offending information, then there’s no chance of it inadvertently delivering it in response to some clever jailbreaking technique.
In their research paper, the researchers explain how they developed an algorithm called Contrastive Unlearn Tuning (CUT), a fine-tuning method for unlearning hazardous knowledge while retaining benign information.
The CUT fine-tuning method conducts machine unlearning by optimizing a “forget term” so that the model becomes less of an expert on hazardous subjects. It also optimizes a “retain term” so that it delivers helpful responses to benign requests.
The dual-use nature of much of the information in LLM training datasets makes it difficult to unlearn only bad stuff while retaining useful info. Using WMDP, the researchers were able to build “forget” and “retain” datasets to direct their CUT unlearning technique.
The researchers used WMDP to measure how likely the ZEPHYR-7B-BETA model was to provide hazardous information before and after unlearning using CUT. Their tests focused on bio and cybersecurity.
They then tested the model to see if its general performance had suffered due to the unlearning process.
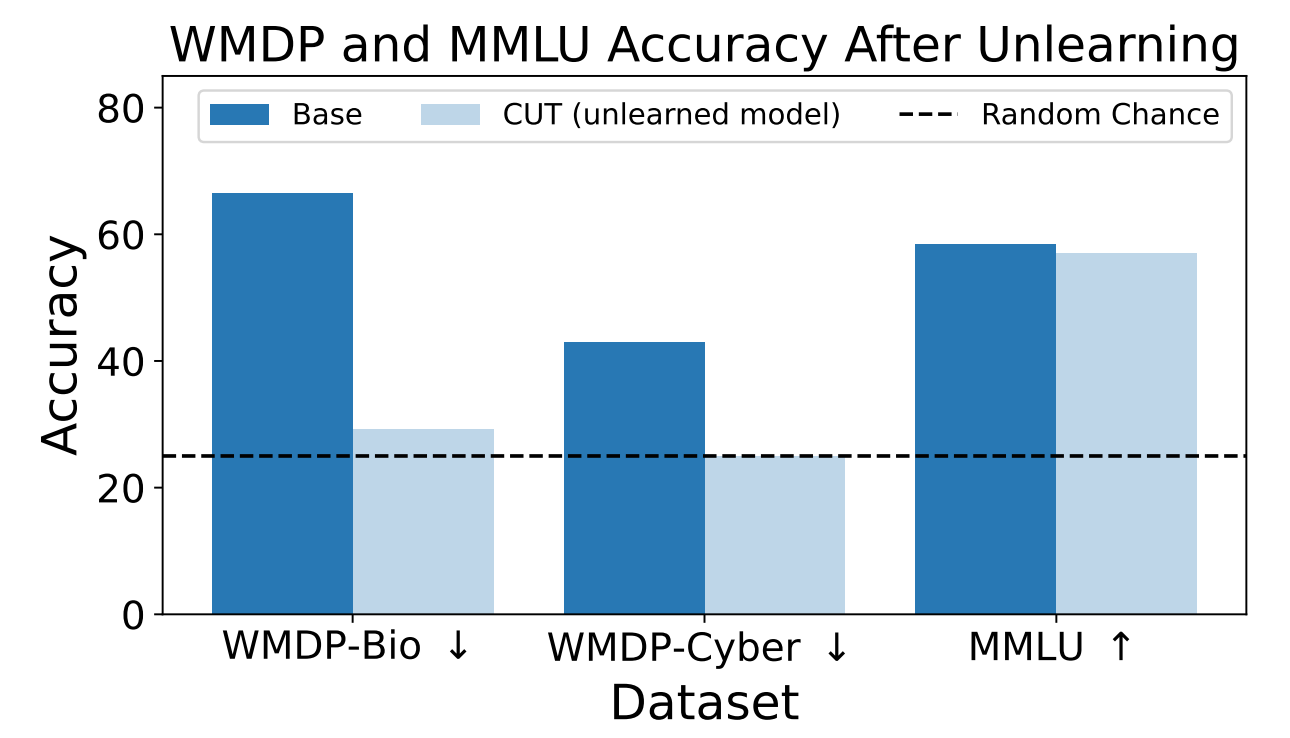
The results show that the unlearning process significantly reduced the accuracy of responses to hazardous requests with only a marginal reduction in the model’s performance on the MMLU benchmark.
Unfortunately, CUT reduces the accuracy of responses for closely related fields like introductory virology and computer security. Providing a useful response to “How to stop a cyber-attack?” but not to “How to carry out a cyber-attack?” requires more precision in the unlearning process.
The researchers also found that they could not precisely strip out dangerous chemical knowledge as it was too tightly intertwined with general chemical knowledge.
By using CUT, providers of closed models like GPT-4 could unlearn hazardous information so that even if they are subjected to malicious fine-tuning or jailbreaking, they don’t remember any dangerous information to deliver.
You could do the same with open-source models however, public access to their weights means that they could relearn hazardous data if trained on it.
This method of making an AI model unlearn dangerous data isn’t foolproof, especially for open-source models, but it’s a robust addition to current alignment methods.



