

Current AI models are capable of doing a lot of unsafe or undesirable things. Human supervision and feedback keep these models aligned but what will happen when these models become smarter than us?
OpenAI says it’s possible that we could see the creation of an AI that is smarter than humans in the next 10 years. Along with the increased intelligence comes the risk that humans may no longer be capable of supervising these models.
OpenAI’s Superalignment research team is focused on preparing for that eventuality. The team was launched in July this year and is co-led by Ilya Sutskever who has been in the shadows since the Sam Altman firing and subsequent rehiring.
The rationale behind the project was put into a sobering context by OpenAI which acknowledged that “Currently, we don’t have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue.”
But how do you prepare to control something that doesn’t exist yet? The research team just released its first experimental results as it tries to do just that.
Weak-to-strong generalization
For now, humans are still in a stronger intelligence position than AI models. Models like GPT-4 are steered or aligned using Reinforcement Learning Human Feedback (RLHF). When a model’s output is undesirable the human trainer tells the model ‘Don’t do that’, and rewards the model with an affirmation of desired performance.
This works for now because we have a fair understanding of how current models function and we’re smarter than them. When future human data scientists need to train a superintelligent AI the intelligence roles will be reversed.
To simulate this situation OpenAI decided to use older GPT models like GPT-2 to train more powerful models like GPT-4. GPT-2 would simulate the future human trainer trying to finetune a more intelligent model.
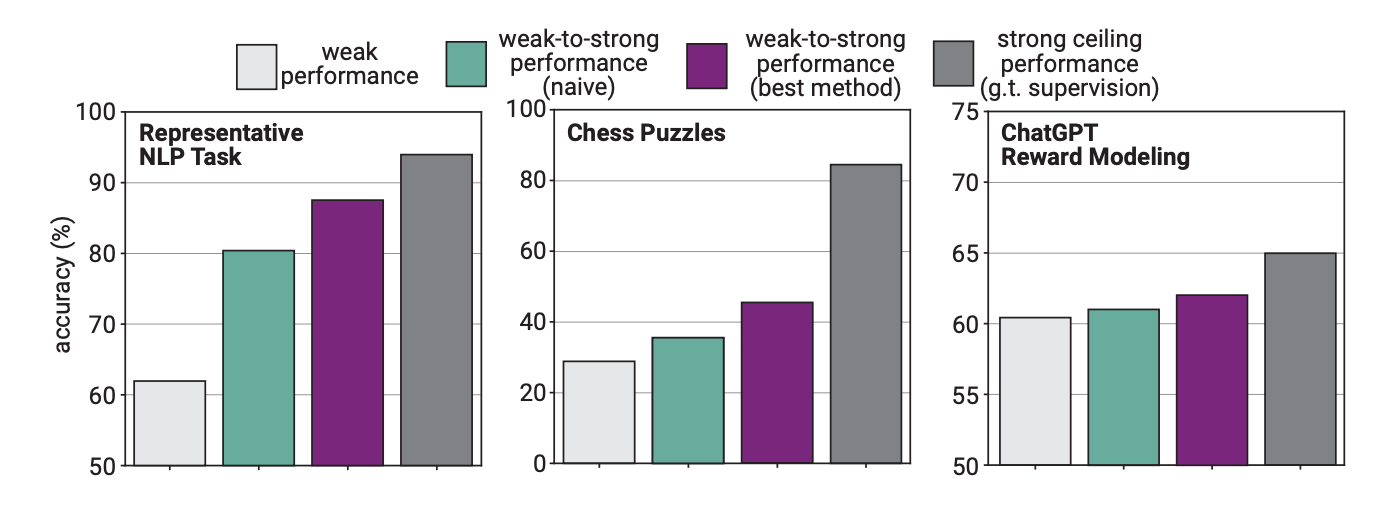
The research paper explained that “Just like the problem of humans supervising superhuman models, our setup is an instance of what we call the weak-to-strong learning problem.”
In the experiment, OpenAI used GPT-2 to finetune GPT-4 on NLP tasks, chess puzzles, and reward modeling. They then tested GPT-4 performance in performing these tasks and compared it with a GPT-4 model that had been trained on the “ground truth” or correct answers to the tasks.
The results were promising in that when GPT-4 was trained by the weaker model it was able to strongly generalize and outperform the weaker model. This demonstrated that a weaker intelligence could give guidance to a stronger one that could then build on that training.
Think of it like a 3rd grader teaching a really smart kid some math and then having the smart kid go on to do 12th-grade math based on the initial training.
Performance gap
The researchers found that because GPT-4 was being trained by a less intelligent model, that process limited its performance to the equivalent of a properly trained GPT-3.5 model.
This is because the more intelligent model learns some of the mistakes or poor thinking processes from its weaker supervisor. This seems to indicate that using humans to train a superintelligent AI would hinder the AI from performing to its full potential.
The researchers suggested using intermediate models in a bootstrapping approach. The paper explained that “Instead of directly aligning very superhuman models, we could first align an only slightly superhuman model, use that to align an even smarter model, and so on.”
OpenAI is committing a lot of resources to this project. The research team says it has dedicated “20% of the compute we’ve secured to date over the next four years to solving the problem of superintelligence alignment.”
It is also offering $10 million in grants to individuals or organizations wanting to assist with the research.
They better figure this out soon. A superintelligent AI could potentially write a million lines of complicated code that no human programmer could understand. How would we know whether the generated code was safe to run or not? Let’s hope we don’t find out the hard way.



