

Meta announced the release of Code Llama, its new AI tool for coding.
Code Llama is a fine-tuned version of Meta’s Llama 2 LLM, which has been trained to write and document code. The new tool takes natural language descriptions and turns them into code. It can also debug, explain, and document code that is supplied as input.
This is a great tool if you’re just learning to code, but it’s software engineers who will benefit most from Code Llama.
The tool supports most of the popular programming languages, including Python, C++, Java, PHP, Typescript (Javascript), C#, Bash, and others.
With Code Llama you can ask it to “Write a function in Python to calculate the first 100 prime numbers,” and it’ll generate the code for you.
Tools like ChatGPT can already write code but Code Llama has a number of features that arguably may make it a better coding tool.
ChatGPT has a context window of between 4,000 and 8,000 tokens, whereas Code Llama can handle up to 100,000 tokens of context. The first obvious benefit of having a bigger context window is that it can write substantially longer code.
The more exciting prospect is being able to input a huge chunk of code and then have Code Llama debug it for you. If you wanted to use ChatGPT to do that, you’d have to debug small pieces at a time.
Today we’re releasing Code Llama, a large language model built on top of Llama 2, fine-tuned for coding & state-of-the-art for publicly available coding tools.
Keeping with our open approach, Code Llama is publicly-available now for both research & commercial use.
More ⬇️
— Meta AI (@MetaAI) August 24, 2023
Meta has released 3 sizes of Code Llama with 7B, 13B, and 34B parameters respectively. The smaller models run faster, with less processing power required, but are less powerful than the 34B model.
The two smaller models have also been trained with fill-in-the-middle (FIM) capability. This allows a programmer to enter existing code and have Code Llama handle code completion tasks.
In addition to the baseline models that support multiple languages, Meta released two versions specifically trained on Python and Instruct.
Is Code Llama any good?
Meta performed its own benchmarking tests and found that Code Llama “performed better than open-source, code-specific LLMs and outperformed Llama 2.”
Here’s the benchmark table showing how Code Llama compares to other models.
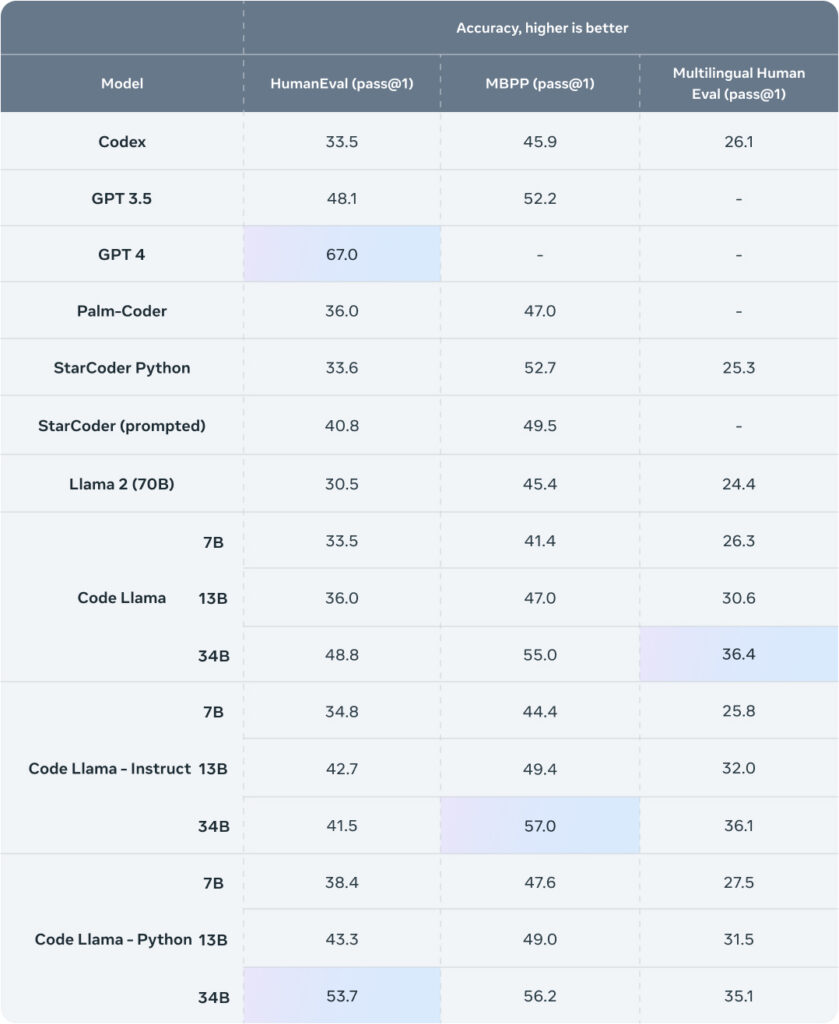
Source: Meta
GPT-4 is still in front by some distance but it’s a huge model, and it isn’t free. Code Llama is free and the 7B version could run on your local machine.
Using GPT-4 requires your code to be sent through OpenAI’s servers and for a lot of companies that represents a huge risk to their intellectual property.
With Code Llama running on local servers, there’s no risk of private company data being leaked or used to train other models.
In addition to the released models, the Code Llama research paper referenced a model called “Unnatural Code Llama”. It scored 62.2% on the HumanEval benchmark, which is really close to GPT-4’s 67%.
There’s no word on when that model will be released, but that kind of performance blows Google’s PaLM Coder out of the water and will even make GPT-4 a tough sell.



