

Anthropic Les chercheurs ont réussi à identifier des millions de concepts au sein des Claude Sonnet, l'un de leurs diplômés en droit.
Les modèles d'IA sont souvent considérés comme des boîtes noires, ce qui signifie que vous ne pouvez pas "voir" à l'intérieur pour comprendre exactement comment ils fonctionnent.
Lorsque vous fournissez une entrée à un LLM, il génère une réponse, mais le raisonnement qui sous-tend ses choix n'est pas clair.
Vous entrez des données et vous obtenez des résultats, et même les développeurs d'IA ne comprennent pas vraiment ce qui se passe à l'intérieur de cette "boîte".
Les réseaux neuronaux créent leurs propres représentations internes de l'information lorsqu'ils mettent en correspondance les entrées et les sorties au cours de l'apprentissage des données. Les éléments constitutifs de ce processus, appelés "activations des neurones", sont représentés par des valeurs numériques.
Chaque concept est réparti entre plusieurs neurones, et chaque neurone contribue à représenter plusieurs concepts, ce qui rend difficile la mise en correspondance directe des concepts avec les neurones individuels.
Cette situation est largement analogue à celle de notre cerveau humain. Tout comme notre cerveau traite les données sensorielles et génère des pensées, des comportements et des souvenirs, les milliards, voire les trillions, de processus à l'origine de ces fonctions restent principalement inconnus de la science.
AnthropicL'étude de tente de voir à l'intérieur de la boîte noire de l'IA grâce à une technique appelée "apprentissage par dictionnaire".
Il s'agit de décomposer les schémas complexes d'un modèle d'IA en blocs linéaires ou "atomes" qui ont un sens intuitif pour les humains.
Mapping LLMs with Dictionary Learning (cartographie des LLMs avec apprentissage par dictionnaire)
En octobre 2023, Anthropic a appliqué cette méthode à un minuscule modèle linguistique "jouet" et a trouvé des caractéristiques cohérentes correspondant à des concepts tels que le texte en majuscules, les séquences d'ADN, les noms de famille dans les citations, les noms mathématiques ou les arguments de fonctions dans le code Python.
Cette dernière étude a permis d'adapter la technique aux modèles de langage d'IA les plus importants d'aujourd'hui, en l'occurrence, Anthropic's Claude 3 Sonnet.
Voici, étape par étape, comment s'est déroulée l'étude :
Identifier des modèles grâce à l'apprentissage par dictionnaire
Anthropic a utilisé l'apprentissage par dictionnaire pour analyser les activations des neurones dans différents contextes et identifier des modèles communs.
L'apprentissage par dictionnaire regroupe ces activations en un ensemble plus restreint de "caractéristiques" significatives, représentant des concepts de plus haut niveau appris par le modèle.
En identifiant ces caractéristiques, les chercheurs peuvent mieux comprendre comment le modèle traite et représente l'information.
Extraction des caractéristiques de la couche intermédiaire
Les chercheurs se sont concentrés sur la couche médiane de la Claude 3.0 Sonnet, qui constitue un point critique dans la chaîne de traitement du modèle.
L'application de l'apprentissage par dictionnaire à cette couche permet d'extraire des millions de caractéristiques qui capturent les représentations internes du modèle et les concepts appris à ce stade.
L'extraction de caractéristiques de la couche intermédiaire permet aux chercheurs d'examiner la compréhension de l'information par le modèle. après il a traité l'entrée avant la production du résultat final.
Découvrir des concepts divers et abstraits
Les caractéristiques extraites révèlent un large éventail de concepts appris par l'équipe d'évaluation. ClaudeL'Europe est un espace de liberté, de liberté et de sécurité, allant d'entités concrètes comme les villes et les personnes à des notions abstraites liées à des domaines scientifiques et à la syntaxe de la programmation.
Il est intéressant de noter que les caractéristiques se sont révélées multimodales, répondant à la fois aux entrées textuelles et visuelles, ce qui indique que le modèle peut apprendre et représenter des concepts à travers différentes modalités.
En outre, les caractéristiques multilingues suggèrent que le modèle peut saisir des concepts exprimés dans différentes langues.

Analyser l'organisation des concepts
Pour comprendre comment le modèle organise et relie différents concepts, les chercheurs ont analysé la similarité entre les caractéristiques sur la base de leurs schémas d'activation.
Ils ont découvert que les caractéristiques représentant des concepts apparentés avaient tendance à se regrouper. Par exemple, les caractéristiques associées aux villes ou aux disciplines scientifiques présentaient une plus grande similitude entre elles qu'avec les caractéristiques représentant des concepts sans rapport.
Cela suggère que l'organisation interne des concepts du modèle s'aligne, dans une certaine mesure, sur les intuitions humaines en matière de relations conceptuelles.
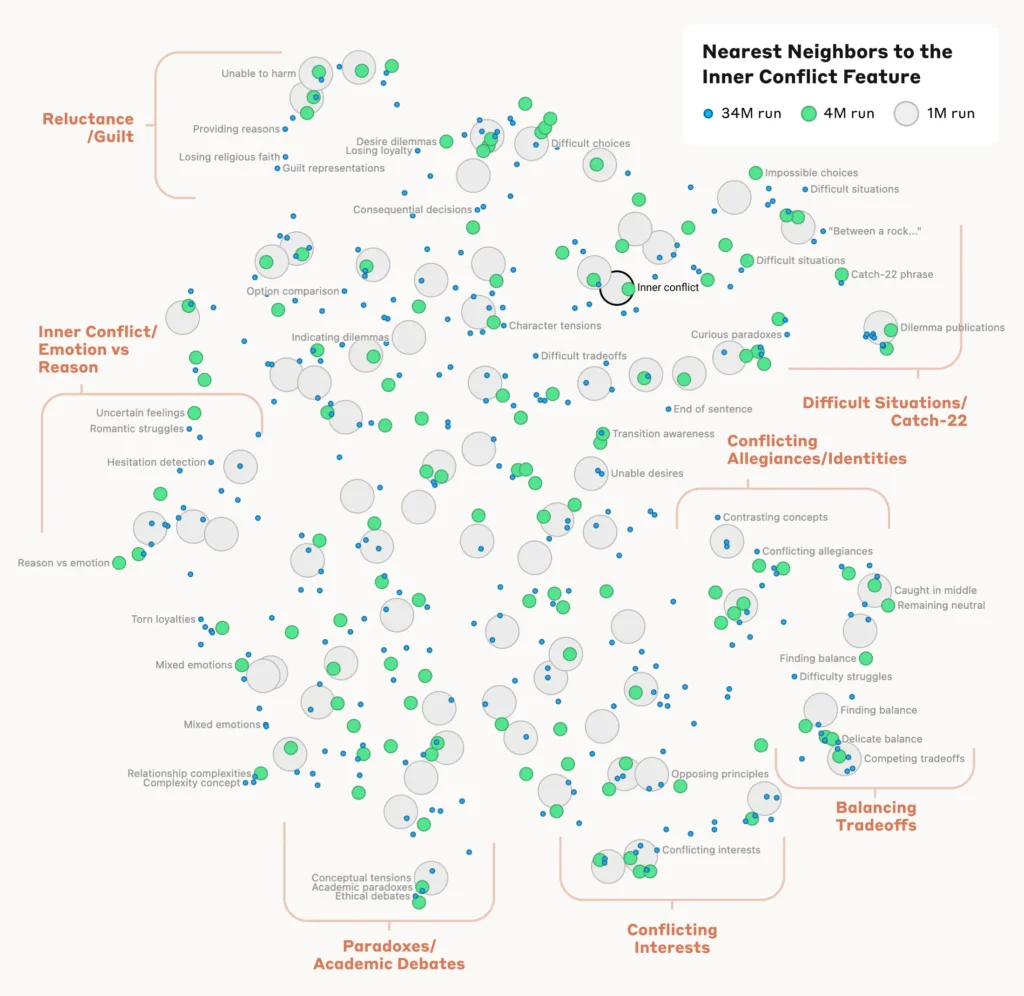
Vérification des caractéristiques
Pour confirmer que les caractéristiques identifiées influencent directement le comportement et les résultats du modèle, les chercheurs ont mené des expériences de "pilotage des caractéristiques".
Il s'agissait d'amplifier ou de supprimer sélectivement l'activation de caractéristiques spécifiques pendant le traitement du modèle et d'observer l'impact sur ses réponses.
En manipulant les caractéristiques individuelles, les chercheurs ont pu établir un lien direct entre les caractéristiques individuelles et le comportement du modèle. Par exemple, l'amplification d'une caractéristique liée à une ville spécifique a conduit le modèle à générer des résultats privilégiant la ville, même dans des contextes non pertinents.
Lire l'étude complète ici.
Pourquoi l'interprétabilité est essentielle pour la sécurité de l'IA
AnthropicLes travaux de recherche de M. K. K. sont d'une importance fondamentale pour l'interprétabilité de l'IA et, par extension, pour la sécurité.
Comprendre comment les MFR traitent et représentent l'information permet aux chercheurs de comprendre et d'atténuer les risques. Il s'agit de jette les bases d'un développement de systèmes d'IA plus transparents et explicables.
En tant que Anthropic explique : "Nous espérons que nous et d'autres pourrons utiliser ces découvertes pour rendre les modèles plus sûrs. Par exemple, il pourrait être possible d'utiliser les techniques décrites ici pour surveiller les systèmes d'IA afin de détecter certains comportements dangereux (comme tromper l'utilisateur), pour les orienter vers des résultats souhaitables (débiaisage), ou pour supprimer complètement certains sujets dangereux."
Il est essentiel de mieux comprendre le comportement de l'IA à mesure qu'elle devient omniprésente dans les processus décisionnels critiques dans des domaines tels que les soins de santé, la finance et la justice pénale. Cela permet également de découvrir les causes profondes des biaisLes personnes souffrant de troubles de l'humeur, d'hallucinations et d'autres comportements non désirés ou imprévisibles.
Par exemple, un étude récente de l'université de Bonn a découvert que les réseaux neuronaux graphiques (GNN) utilisés pour la découverte de médicaments reposent largement sur le rappel de similitudes à partir de données d'entraînement plutôt que sur un véritable apprentissage de nouvelles interactions chimiques complexes.
Il est donc difficile de comprendre comment ces modèles déterminent exactement les nouveaux composés d'intérêt.
L'année dernière, la Le gouvernement britannique a négocié avec des géants de la technologie comme OpenAI et DeepMindqui souhaitent avoir accès aux processus décisionnels internes de leurs systèmes d'intelligence artificielle.
Un règlement comme le Loi sur l'IA de l'UE fera pression sur les entreprises d'IA pour qu'elles soient plus transparentes, même si les secrets commerciaux semblent sûrs de rester sous clé.
AnthropicLa recherche de la Commission européenne offre un aperçu de ce qui se trouve à l'intérieur de la boîte en "cartographiant" l'information à travers le modèle.
Cependant, la vérité est que ces modèles sont si vastes que, en AnthropicNous pensons qu'il est très probable que nous soyons à court de plusieurs ordres de grandeur et que si nous voulions obtenir toutes les caractéristiques, dans toutes les couches, nous devrions utiliser beaucoup plus de calculs que le total des calculs nécessaires pour former les modèles sous-jacents. - nous devrions utiliser beaucoup plus de ressources informatiques que le total des ressources informatiques nécessaires pour former les modèles sous-jacents.
C'est un point intéressant : la rétro-ingénierie d'un modèle est plus complexe sur le plan informatique que l'ingénierie du modèle en premier lieu.
Cela rappelle les projets neuroscientifiques extrêmement coûteux tels que l'étude de l'ADN. Projet sur le cerveau humain (HBP)qui a investi des milliards dans la cartographie de notre propre cerveau humain, pour finalement échouer.
Ne sous-estimez jamais tout ce qui se cache dans la boîte noire.



