

In einer Studie der Universität Oxford wurde ein Verfahren entwickelt, mit dem getestet werden kann, wann Sprachmodelle "unsicher" in Bezug auf ihre Ausgabe sind und Gefahr laufen, zu halluzinieren.
KI-Halluzinationen" beziehen sich auf ein Phänomen, bei dem große Sprachmodelle (LLMs) fließende und plausible Antworten erzeugen, die nicht wahrheitsgemäß oder konsistent sind.
Halluzinationen sind schwer - wenn nicht gar unmöglich - von KI-Modellen zu trennen. KI-Entwickler wie OpenAI, Google und Anthropic haben alle zugegeben, dass Halluzinationen wahrscheinlich ein Nebenprodukt der Interaktion mit KI bleiben werden.
So Dr. Sebastian Farquhar, einer der Autoren der Studie, erklärt in einem BlogeintragLLMs sind sehr fähig, ein und dieselbe Sache auf viele verschiedene Arten zu sagen, was es schwierig machen kann, zu erkennen, wann sie sich einer Antwort sicher sind und wann sie sich buchstäblich etwas ausdenken.
Das Cambridge Dictionary hat sogar eine AI-bezogene Definition des Wortes im Jahr 2023 und ernannte es zum "Wort des Jahres".
Diese Universität von Oxford Studie, veröffentlicht in Nature, versucht zu beantworten, wie wir erkennen können, wann diese Halluzinationen am wahrscheinlichsten auftreten.
Sie führt ein Konzept ein, das als "semantische Entropie" bezeichnet wird und die Unsicherheit der Ergebnisse eines LLM auf der Ebene der Bedeutung und nicht nur der verwendeten spezifischen Wörter oder Sätze misst.
Durch die Berechnung der semantischen Entropie der Antworten eines LLM können die Forscher das Vertrauen des Modells in seine Ergebnisse abschätzen und feststellen, in welchen Fällen es wahrscheinlich halluziniert.
Semantische Entropie in LLMs erklärt
Die semantische Entropie, wie sie in der Studie definiert wird, misst die Unsicherheit oder Inkonsistenz in der Bedeutung der Antworten eines LLM. Es hilft zu erkennen, wenn ein LLM möglicherweise halluziniert oder unzuverlässige Informationen generiert.
Vereinfacht ausgedrückt, misst die semantische Entropie, wie "verworren" die Ausgabe eines LLM ist.
Das LLM wird wahrscheinlich zuverlässige Informationen liefern, wenn die Bedeutung seiner Ergebnisse eng miteinander verbunden und konsistent ist. Aber wenn die Bedeutungen verstreut und widersprüchlich sind, ist das ein rotes Fähnchen, dass der LLM möglicherweise halluziniert oder ungenaue Informationen erzeugt.
Und so funktioniert es:
- Die Forscher haben den LLM aktiv dazu veranlasst, mehrere mögliche Antworten auf dieselbe Frage zu geben. Dies wird erreicht, indem die Frage mehrmals an das LLM gesendet wird, jedes Mal mit einem anderen Zufallswert oder einer leichten Variation der Eingabe.
- Die semantische Entropie untersucht die Antworten und gruppiert diejenigen, die dieselbe Bedeutung haben, auch wenn sie unterschiedliche Wörter oder Formulierungen verwenden.
- Wenn das LLM von der Antwort überzeugt ist, sollten seine Antworten ähnliche Bedeutungen haben, was zu einer niedrigen semantischen Entropie führt. Dies deutet darauf hin, dass der LLM die Informationen klar und konsistent versteht.
- Wenn das LLM jedoch unsicher oder verwirrt ist, werden seine Antworten eine größere Vielfalt an Bedeutungen haben, von denen einige widersprüchlich sein oder in keinem Zusammenhang mit der Frage stehen könnten. Dies führt zu einer hohen semantischen Entropie, was darauf hinweist, dass das LLM halluzinieren oder unzuverlässige Informationen generieren könnte.
Um ihre Wirksamkeit zu bewerten, haben die Forscher die semantische Entropie auf eine Reihe von Aufgaben zur Beantwortung von Fragen angewendet. Dazu gehörten Benchmarks wie Trivia-Fragen, Leseverständnis, Textaufgaben und Biografien.
Die semantische Entropie übertraf in allen Bereichen die bestehenden Methoden, um zu erkennen, wann eine LLM wahrscheinlich eine falsche oder inkonsistente Antwort erzeugen würde.
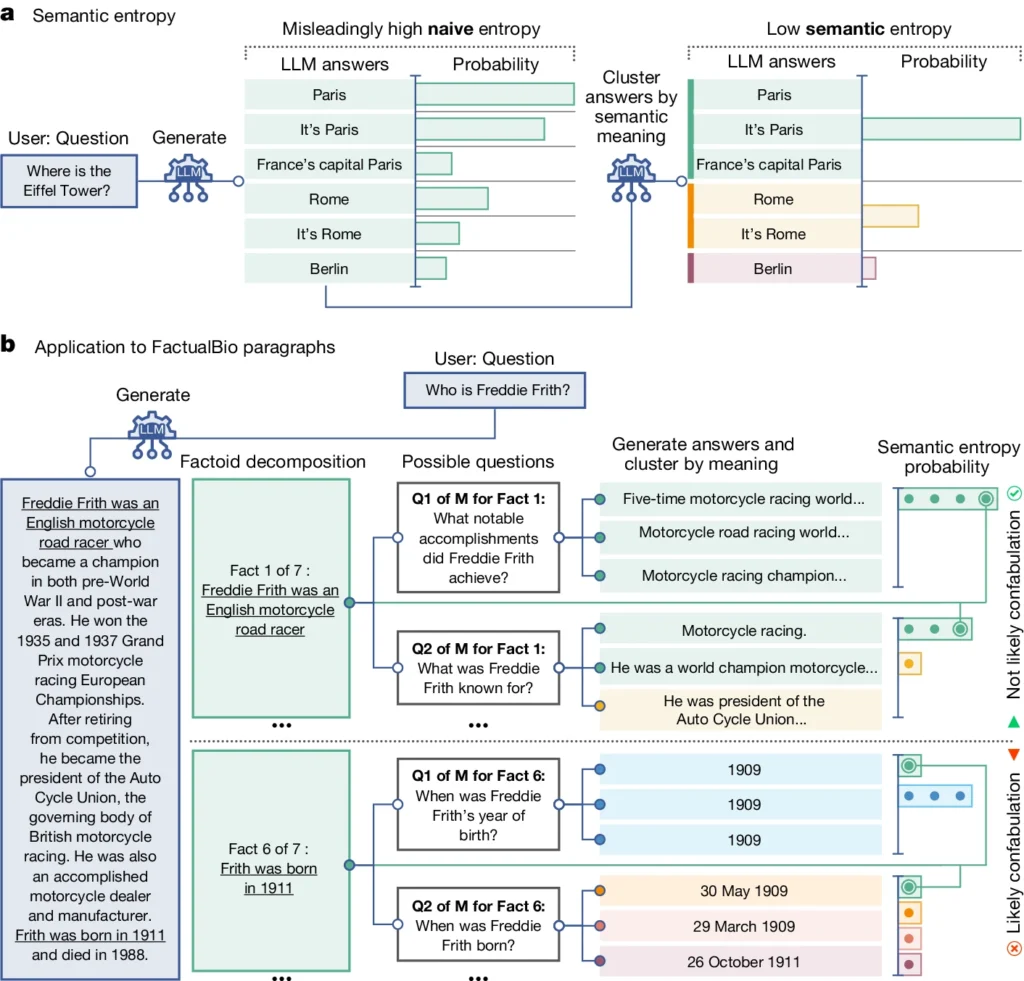
Im obigen Diagramm können Sie sehen, wie einige Aufforderungen den LLM dazu bringen, eine konfabulierte (ungenaue, halluzinatorische) Antwort zu geben. So werden beispielsweise bei den Fragen im unteren Teil des Diagramms der Tag und der Monat der Geburt angegeben, wenn die zur Beantwortung erforderlichen Informationen nicht in den ursprünglichen Angaben enthalten waren.
Auswirkungen der Erkennung von Halluzinationen
Diese Arbeit kann dazu beitragen, Halluzinationen zu erklären und LLMs zuverlässiger und vertrauenswürdiger zu machen.
Die semantische Entropie ermöglicht es, zu erkennen, ob ein LLM unsicher ist oder zu Halluzinationen neigt, und ebnet so den Weg für den Einsatz dieser KI-Tools in wichtigen Bereichen, in denen Faktengenauigkeit von entscheidender Bedeutung ist, wie z. B. im Gesundheits-, Rechts- und Finanzwesen.
Falsche Ergebnisse können potenziell katastrophale Auswirkungen haben, wenn sie sich auf Situationen auswirken, in denen es um viel geht, wie einige Beispiele zeigen gescheiterte vorausschauende Polizeiarbeit und Gesundheitssysteme.
Es ist jedoch auch wichtig, daran zu denken, dass Halluzinationen nur eine Art von Fehlern sind, die LLMs machen können.
Dr. Farquhar erklärt: "Wenn ein LLM ständig Fehler macht, wird diese neue Methode das nicht aufdecken. Die gefährlichsten Fehler der KI treten auf, wenn ein System etwas Schlechtes tut, aber sicher und systematisch ist. Da gibt es noch viel zu tun".
Nichtsdestotrotz stellt die semantische Entropie-Methode des Oxford-Teams einen großen Fortschritt in unserer Fähigkeit dar, die Grenzen von KI-Sprachmodellen zu verstehen und abzumildern.
Die Bereitstellung eines objektiven Mittels zu ihrer Erkennung bringt uns einer Zukunft näher, in der wir das Potenzial der KI nutzen und gleichzeitig sicherstellen können, dass sie ein zuverlässiges und vertrauenswürdiges Instrument im Dienste der Menschheit bleibt.



