

Apple engineers developed an AI system that resolves complex references to on-screen entities and user conversations. The lightweight model could be an ideal solution for on-device virtual assistants.
Humans are good at resolving references in conversations with each other. When we use terms like “the bottom one” or “him” we understand what the person is referring to based on the context of the conversation and things we can see.
It’s a lot more difficult for an AI model to do this. Multimodal LLMs like GPT-4 are good at answering questions about images but are expensive to train and require a lot of computing overhead to process each query about an image.
Apple’s engineers took a different approach with their system, called ReALM (Reference Resolution As Language Modeling). The paper is worth a read for more detail on their development and testing process.
ReALM uses an LLM to process conversational, on-screen, and background entities (alarms, background music) that make up a user’s interactions with a virtual AI agent.
Here’s an example of the kind of interaction a user could have with an AI agent.
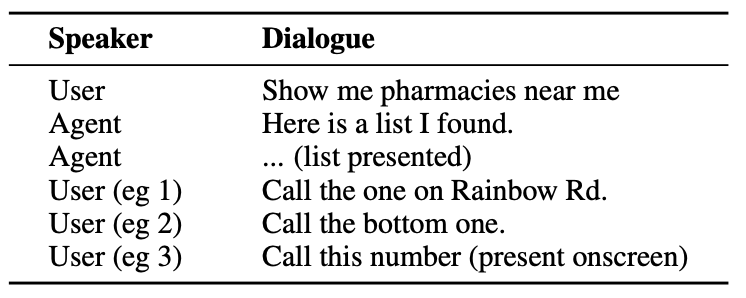
The agent needs to understand conversational entities like the fact that when the user says “the one” they are referring to the telephone number for the pharmacy.
It also needs to understand visual context when the user says “the bottom one”, and this is where ReALM’s approach differs from models like GPT-4.
ReALM relies on upstream encoders to first parse the on-screen elements and their positions. ReALM then reconstructs the screen in purely textual representations in a left-to-right, top-to-bottom fashion.
In simple terms, it uses natural language to summarize the user’s screen.
Now, when a user asks a question about something on the screen, the language model processes the text description of the screen rather than needing to use a vision model to process the on-screen image.
The researchers created synthetic datasets of conversational, on-screen, and background entities and tested ReALM and other models to test their effectiveness in resolving references in conversational systems.
ReALM’s smaller version (80M parameters) performed comparably with GPT-4 and its larger version (3B parameters) substantially outperforms GPT-4.
ReALM is a tiny model compared to GPT-4. Its superior reference resolution makes it an ideal choice for a virtual assistant that can exist on-device without compromising performance.
ReALM doesn’t perform as well with more complex images or nuanced user requests but it could work well as an in-car or on-device virtual assistant. Imagine if Siri could “see” your iPhone screen and respond to references to on-screen elements.
Apple has been a little slow out of the blocks, but recent developments like their MM1 model and ReALM show a lot is happening behind closed doors.



