

Группа исследователей из Нью-Йоркского университета добилась успехов в нейронном декодировании речи, приближая нас к будущему, в котором люди, потерявшие способность говорить, смогут вернуть свой голос.
Сайт исследованиеОпубликовано в Природный машинный интеллектпредставляет новую систему глубокого обучения, которая точно переводит сигналы мозга в разборчивую речь.
Люди с повреждениями мозга в результате инсульта, дегенеративных заболеваний или физических травм могут использовать эти системы для общения, расшифровывая свои мысли или предполагаемую речь на основе нейронных сигналов.
Система команды Нью-Йоркского университета включает модель глубокого обучения, которая сопоставляет сигналы электрокортикографии (ЭКоГ) мозга с характеристиками речи, такими как высота тона, громкость и другое спектральное содержание.
На втором этапе нейронный синтезатор речи преобразует извлеченные особенности речи в звуковую спектрограмму, которая затем может быть преобразована в форму речевого сигнала.
Эта форма волны может быть преобразована в синтезированную речь с естественным звучанием.
Сегодня вышла новая статья в @NatMachIntellВ этой работе мы продемонстрировали надежное декодирование речи с помощью нейронов у 48 пациентов. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Адин Флинкер 🇮🇱🇺🇦🎗️ (@adeenflinker) 9 апреля 2024 года
Как проходит исследование
Это исследование включает в себя обучение модели искусственного интеллекта, которая может работать с устройством синтеза речи, позволяя людям с потерей речи говорить с помощью электрических импульсов мозга.
Вот как это работает более подробно:
1. Сбор данных о мозге
Первый шаг - сбор исходных данных, необходимых для обучения модели декодирования речи. Исследователи работали с 48 участниками, которым была проведена нейрохирургическая операция по поводу эпилепсии.
В ходе исследования участников просили читать сотни предложений вслух, а их мозговая активность регистрировалась с помощью ЭКоГ-сеток.
Эти решетки размещаются непосредственно на поверхности мозга и улавливают электрические сигналы от участков мозга, участвующих в производстве речи.
2. Сопоставление сигналов мозга с речью
Используя данные о речи, исследователи разработали сложную модель искусственного интеллекта, которая сопоставляет записанные сигналы мозга с определенными особенностями речи, такими как высота тона, громкость и уникальные частоты, составляющие различные звуки речи.
3. Синтез речи по признакам
Третий этап направлен на преобразование речевых характеристик, извлеченных из сигналов мозга, в звуковую речь.
Исследователи использовали специальный синтезатор речи, который использует извлеченные особенности и генерирует спектрограмму - визуальное представление звуков речи.
4. Оценка результатов
Исследователи сравнили речь, сгенерированную их моделью, с оригинальной речью, которую произносили участники.
Они использовали объективные показатели для измерения сходства между ними и обнаружили, что сгенерированная речь точно соответствует содержанию и ритму оригинала.
5. Проверка новых слов
Чтобы убедиться в том, что модель может обрабатывать новые слова, которые она не видела раньше, некоторые слова были намеренно пропущены на этапе обучения модели, а затем была проверена работа модели с этими невидимыми словами.
Способность модели точно декодировать даже новые слова демонстрирует ее потенциал к обобщению и обработке различных речевых моделей.
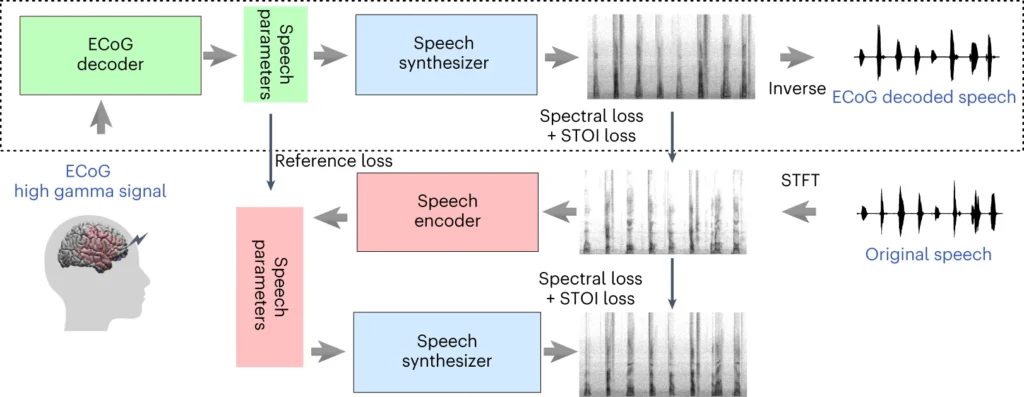
Верхняя часть приведенной выше схемы описывает процесс преобразования сигналов мозга в речь. Сначала декодер превращает эти сигналы в параметры речи с течением времени. Затем синтезатор создает из этих параметров звуковые картины (спектрограммы). Другой инструмент преобразует эти картины обратно в звуковые волны.
В нижнем разделе рассматривается система, которая помогает тренировать декодер сигналов мозга, имитируя речь. Она берет звуковую картину, преобразует ее в параметры речи, а затем использует их для создания новой звуковой картины. Эта часть системы учится на реальных звуках речи, чтобы улучшить их.
После обучения для преобразования сигналов мозга в речь требуется только верхняя часть процесса.
Одним из ключевых преимуществ системы Нью-Йоркского университета является ее способность достигать высококачественного декодирования речи без необходимости использования электродных массивов сверхвысокой плотности, которые непрактичны для длительного использования.
По сути, это более легкое и портативное решение.
Еще одно достижение - успешное декодирование речи как из левого, так и из правого полушария мозга, что важно для пациентов с повреждением одной стороны мозга.
Преобразование мыслей в речь с помощью искусственного интеллекта
Исследование Нью-Йоркского университета опирается на предыдущие исследования в области нейронного декодирования речи и интерфейсов мозг-компьютер (BCI).
В 2023 году команда Калифорнийского университета в Сан-Франциско позволит парализованному человеку, пережившему инсульт. создавать предложения со скоростью 78 слов в минуту, используя BCI, который синтезировал вокализацию и мимику из сигналов мозга.
В других недавних исследованиях изучалось использование ИИ для интерпретации различных аспектов человеческого мышления на основе активности мозга. Исследователи продемонстрировали способность генерировать изображения, текст и даже музыку на основе данных МРТ и электроэнцефалограммы (ЭЭГ), полученных из мозга.
Например. исследование, проведенное в Хельсинкском университете Авторы использовали сигналы ЭЭГ для управления генеративной состязательной сетью (GAN) при создании изображений лица, соответствующих мыслям участников.
Мета ИИ также разработал методику для частичной расшифровки того, что слушает человек, с помощью мозговых волн, собранных неинвазивно.
Возможности и проблемы
Метод Нью-Йоркского университета использует более доступные и клинически жизнеспособные электроды, чем предыдущие методы, что делает его более доступным.
Несмотря на то, что это очень интересно, для того чтобы получить широкое распространение, необходимо преодолеть серьезные препятствия.
Во-первых, сбор высококачественных данных о мозге - сложное и трудоемкое занятие. Индивидуальные различия в активности мозга затрудняют обобщение, а значит, модель, обученная для одной группы участников, может оказаться неэффективной для другой.
Тем не менее, исследование NYU представляет собой шаг в этом направлении, демонстрируя высокую точность декодирования речи с помощью более легких электродных массивов.
В будущем команда Нью-Йоркского университета намерена усовершенствовать свои модели для декодирования речи в реальном времени, приближая нас к конечной цели - созданию естественных, беглых разговоров для людей с нарушениями речи.
Они также намерены адаптировать систему к имплантируемым беспроводным устройствам, которые можно будет использовать в повседневной жизни.



