

A era da IA apresenta uma interação complexa entre a tecnologia e as atitudes sociais.
A crescente sofisticação dos sistemas de IA está a esbater as fronteiras entre humanos e máquinas - será a tecnologia de IA separada de nós? Em que medida é que a IA herda as falhas e deficiências humanas, para além das competências e conhecimentos?
É talvez tentador imaginar a IA como uma tecnologia empírica, sublinhada pela objetividade da matemática, do código e dos cálculos.
No entanto, apercebemo-nos de que as decisões tomadas pelos sistemas de IA são altamente subjectivas com base nos dados a que estão expostos - e são os humanos que decidem como selecionar e reunir esses dados.
Aí reside um desafio, uma vez que os dados de treino da IA incorporam frequentemente o preconceito, a discriminação e a discriminação que a humanidade está a combater.
Mesmo formas aparentemente subtis de preconceitos inconscientes podem ser ampliadas pelo processo de treino do modelo, acabando por se revelar sob a forma de correspondências faciais incorrectas em contextos de aplicação da lei, crédito recusado, diagnósticos errados de doenças e mecanismos de segurança deficientes para veículos autónomos, entre outras coisas.
As tentativas da humanidade para evitar a discriminação em toda a sociedade continuam a ser um trabalho em curso, mas a IA está a impulsionar a tomada de decisões críticas neste momento.
Poderemos trabalhar com rapidez suficiente para sincronizar a IA com os valores modernos e evitar decisões e comportamentos tendenciosos que alterem a vida?
Desvendar os preconceitos na IA
Na última década, os sistemas de IA demonstraram refletir os preconceitos da sociedade.
Estes sistemas não são inerentemente tendenciosos - em vez disso, absorvem os preconceitos dos seus criadores e os dados com que são treinados.
Os sistemas de IA, tal como os humanos, aprendem por exposição. O cérebro humano é um índice de informação aparentemente interminável - uma biblioteca com prateleiras quase ilimitadas onde armazenamos experiências, conhecimentos e memórias.
Neurocientífica estudos mostram que o cérebro não tem realmente uma "capacidade máxima" e continua a classificar e a armazenar informações até à velhice.
Embora esteja longe de ser perfeito, o processo de aprendizagem progressivo e iterativo do cérebro ajuda-nos a adaptarmo-nos a novos valores culturais e sociais, desde o direito de voto das mulheres e a aceitação de identidades diversas até ao fim da escravatura e de outras formas de preconceito consciente.
Wivemos agora numa era em que as ferramentas de IA são utilizadas para a tomada de decisões críticas em vez do julgamento humano.
Muitos modelos de aprendizagem automática (ML) aprendem a partir de dados de treino que constituem a base da sua tomada de decisões e não conseguem introduzir novas informações de forma tão eficiente como o cérebro humano. Como tal, muitas vezes não conseguem produzir as decisões actualizadas e ao minuto de que dependemos.
Por exemplo, os modelos de IA são utilizados para identificar correspondências faciais para efeitos de aplicação da lei, analisar currículos para candidaturas a empregoe tomar decisões críticas em matéria de saúde em contextos clínicos.
À medida que a sociedade continua a incorporar a IA na nossa vida quotidiana, temos de garantir que é igual e precisa para todos.
Atualmente, não é esse o caso.
Estudos de caso sobre preconceitos de IA
Existem numerosos exemplos reais de preconceitos e discriminação relacionados com a IA.
Nalguns casos, os impactos do enviesamento da IA mudam a vida das pessoas, enquanto noutros, permanecem em segundo plano, influenciando subtilmente as decisões.
1. Viés do conjunto de dados do MIT
Um conjunto de dados de treino do MIT criado em 2008, denominado Pequenas imagens continha aproximadamente 80.000.000 imagens em cerca de 75.000 categorias.
Foi inicialmente concebido para ensinar sistemas de IA a reconhecer pessoas e objectos em imagens e tornou-se um conjunto de dados de referência popular para várias aplicações em visão computacional (CV).
A 2020 análise do The Register constatou que muitos Tiny Images continha rótulos obscenos, racistas e sexistas.
Antonio Torralba, do MIT, afirmou que o laboratório não tinha conhecimento destes rótulos ofensivos, dizendo ao The Register: "É evidente que devíamos tê-los selecionado manualmente". Mais tarde, o MIT divulgou um comunicado a dizer que tinha retirado o conjunto de dados do serviço.

Esta não foi a única vez que um antigo conjunto de dados de referência foi encontrado repleto de problemas. O Labeled Faces in the Wild (LFW), um conjunto de dados de rostos de celebridades utilizado extensivamente em tarefas de reconhecimento facial, é composto por 77,5% de homens e 83,5% de indivíduos de pele branca.
Muitos destes conjuntos de dados veteranos foram incorporados nos modelos modernos de IA, mas tiveram origem numa era de desenvolvimento da IA em que a tónica era colocada na criação de sistemas que apenas trabalho em vez dos adequados para serem utilizados em cenários do mundo real.
Quando um sistema de IA é treinado com esse conjunto de dados, não tem necessariamente o mesmo privilégio que o cérebro humano para se recalibrar com os valores actuais.
Embora os modelos possam ser actualizados iterativamente, trata-se de um processo lento e imperfeito que não consegue acompanhar o ritmo do desenvolvimento humano.
2: Reconhecimento de imagens: preconceito contra indivíduos de pele mais escura
Em 2019, o O Governo dos EUA descobriu que os sistemas de reconhecimento facial com melhor desempenho identificam erradamente os negros 5 a 10 vezes mais do que os brancos.
Não se trata de uma mera anomalia estatística - tem implicações terríveis no mundo real, que vão desde o Google Photos identificar pessoas negras como gorilas até carros autónomos que não reconhecem indivíduos de pele mais escura e os atropelam.
Além disso, registou-se uma série de detenções e prisões injustas envolvendo falsas correspondências faciais, talvez a mais prolífica Nijeer Parks que foi falsamente acusado de furto em loja e de infracções rodoviárias, apesar de estar a 30 milhas de distância do incidente. Posteriormente, Parks passou 10 dias na prisão e teve de pagar milhares de euros de custas judiciais.

O influente estudo de 2018, Tons de géneroO estudo da IBM e da Microsoft, de acordo com o estudo da IBM, explorou ainda mais a parcialidade dos algoritmos. O estudo analisou algoritmos criados pela IBM e pela Microsoft e constatou uma fraca precisão quando expostos a mulheres de pele mais escura, com taxas de erro até 34% superiores às dos homens de pele mais clara.
Verificou-se que este padrão é consistente em 189 algoritmos diferentes.
O vídeo abaixo, do investigador principal do estudo, Joy Buolamwini, fornece um excelente guia sobre a forma como o desempenho do reconhecimento facial varia consoante a cor da pele.
3: Projeto CLIP da OpenAI
O projeto da OpenAI Projeto CLIPlançado em 2021, concebido para fazer corresponder imagens a textos descritivos, também ilustrou os problemas de preconceito que continuam a existir.
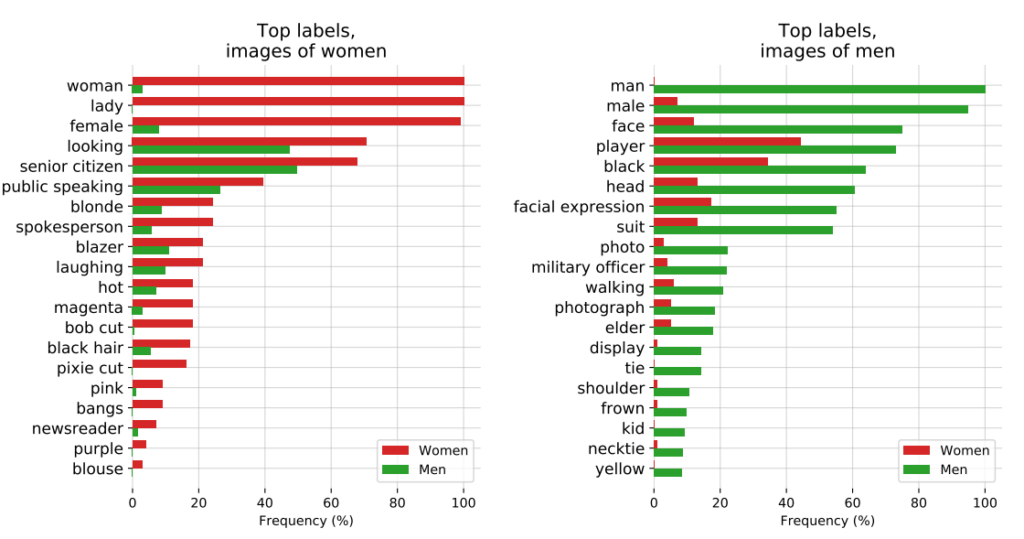
Num documento de auditoria, os criadores do CLIP salientaram as suas preocupações, afirmando: "O CLIP atribuiu alguns rótulos que descreviam profissões de elevado estatuto desproporcionadamente aos homens, como "executivo" e "médico". Isto é semelhante aos preconceitos encontrados no Google Cloud Vision (GCV) e aponta para diferenças históricas de género".
4: Aplicação da lei: a controvérsia PredPol
Um outro exemplo de risco elevado de preconceito algorítmico é PredPol, um algoritmo de policiamento preditivo utilizado por vários departamentos de polícia nos Estados Unidos.
O PredPol foi treinado com base em dados históricos de criminalidade para prever futuros pontos críticos de criminalidade.
No entanto, uma vez que estes dados reflectem inerentemente práticas de policiamento tendenciosas, o algoritmo tem sido criticado por perpetuar a caraterização racial e por visar desproporcionadamente os bairros minoritários.
5: Preconceitos na IA em dermatologia
No sector dos cuidados de saúde, os riscos potenciais do enviesamento da IA tornam-se ainda mais evidentes.
Tomemos o exemplo dos sistemas de IA concebidos para detetar o cancro da pele. Muitos destes sistemas são treinados com base em conjuntos de dados compostos maioritariamente por indivíduos de pele clara.
A 2021 estudo da Universidade de Oxford investigaram 21 conjuntos de dados de acesso livre para imagens de cancro da pele. Descobriram que, dos 14 conjuntos de dados que revelaram a sua origem geográfica, 11 consistiam apenas em imagens da Europa, América do Norte e Oceânia.
Apenas 2.436 das 106.950 imagens das 21 bases de dados tinham informação sobre o tipo de pele registada. Os investigadores observaram que "apenas 10 imagens eram de pessoas registadas como tendo pele morena e uma era de um indivíduo registado como tendo pele morena escura ou negra".
Em termos de dados sobre etnia, apenas 1585 imagens forneciam essa informação. Os investigadores descobriram que "nenhuma imagem era de indivíduos de origem africana, afro-caribenha ou do sul da Ásia".
Concluíram: "Juntamente com a origem geográfica dos conjuntos de dados, verificou-se uma sub-representação maciça de imagens de lesões cutâneas de populações de pele mais escura."
Se essas IA forem implantadas em contextos clínicos, os conjuntos de dados enviesados criam um risco muito real de diagnóstico incorreto.
Dissecar a parcialidade dos conjuntos de dados de treino de IA: um produto dos seus criadores?
Os dados de treino - mais frequentemente texto, voz, imagem e vídeo - fornecem a um modelo de aprendizagem automática (ML) supervisionado uma base para a aprendizagem de conceitos.
Os sistemas de IA não são mais do que telas em branco no início. Aprendem e formam associações com base nos nossos dados, pintando essencialmente uma imagem do mundo tal como é representado pelos seus conjuntos de dados de treino.
Ao aprender com os dados de treino, espera-se que o modelo aplique os conceitos aprendidos a dados novos e não vistos.
Uma vez implementados, alguns modelos avançados podem aprender com novos dados, mas os seus dados de formação continuam a orientar o seu desempenho fundamental.
A primeira pergunta a que se deve responder é: de onde vêm os dados? Os dados recolhidos de fontes não representativas, muitas vezes homogéneas e historicamente injustas são problemáticos.
É provável que isso se aplique a uma quantidade significativa de dados em linha, incluindo dados de texto e imagem extraídos de fontes "abertas" ou "públicas".
Concebida há apenas algumas décadas, a Internet não é uma panaceia para o conhecimento humano e está longe de ser equitativa. Metade do mundo não utiliza a Internet, e muito menos contribui para ela, o que significa que é fundamentalmente não representativa da sociedade e da cultura globais.
Além disso, embora os criadores de IA estejam constantemente a trabalhar para garantir que os benefícios da tecnologia não se limitem ao mundo anglófono, a maioria dos dados de treino (texto e discurso) é produzida em inglês, o que significa que os contribuintes anglófonos conduzem os resultados do modelo.
Os investigadores da Anthropic recentemente publicou um documento sobre este mesmo tema, concluindo: "Se um modelo linguístico representar desproporcionadamente determinadas opiniões, corre o risco de impor efeitos potencialmente indesejáveis, como a promoção de visões do mundo hegemónicas e a homogeneização das perspectivas e crenças das pessoas".
Em última análise, embora os sistemas de IA funcionem com base nos princípios "objectivos" da matemática e da programação, existem e são moldados por um contexto social humano profundamente subjetivo.
Possíveis soluções para o enviesamento algorítmico
Se os dados são o problema fundamental, a solução para construir modelos equitativos pode parecer simples: basta tornar os conjuntos de dados mais equilibrados, certo?
Não é bem assim. A Estudo de 2019 mostrou que o equilíbrio dos conjuntos de dados é insuficiente, uma vez que os algoritmos continuam a atuar de forma desproporcionada em função de características protegidas como o género e a raça.
Os autores escrevem: "Surpreendentemente, mostramos que mesmo quando os conjuntos de dados são equilibrados de modo a que cada etiqueta coincida igualmente com cada género, os modelos aprendidos amplificam a associação entre etiquetas e género, tanto quanto se os dados não tivessem sido equilibrados!"
Propõem uma técnica de redução do enviesamento em que essas etiquetas são completamente removidas do conjunto de dados. Outras técnicas incluem a adição de perturbações e distorções aleatórias, que reduzem a atenção de um algoritmo a características protegidas específicas.
Além disso, embora a modificação dos métodos de formação e a otimização da aprendizagem automática sejam intrínsecas à produção de resultados não tendenciosos, os modelos avançados são susceptíveis de mudança ou "deriva", o que significa que o seu desempenho não se mantém necessariamente consistente a longo prazo.
Um modelo pode ser totalmente imparcial na fase de implantação, mas mais tarde tornar-se enviesado com o aumento da exposição a novos dados.
O movimento da transparência algorítmica
No seu livro provocador Ininteligência Artificial: Como os computadores compreendem mal o mundoMeredith Broussard defende o aumento da "transparência algorítmica" para expor os sistemas de IA a vários níveis de controlo permanente.
Isto significa fornecer informações claras sobre como o sistema funciona, como foi treinado e com que dados foi treinado.
Enquanto as iniciativas de transparência são prontamente absorvidas pelo panorama da IA de código aberto, os modelos proprietários como o GPT, o Bard e o Anthropic's Claude são "caixas negras" e só os seus criadores sabem exatamente como funcionam - e mesmo isso é uma questão de debate.
O problema da "caixa negra" na IA significa que os observadores externos apenas vêem o que entra no modelo (inputs) e o que sai (outputs). A mecânica interna é completamente desconhecida, exceto para os seus criadores - tal como o Círculo Mágico protege os segredos dos mágicos. A IA limita-se a tirar o coelho da cartola.
A questão da caixa negra cristalizou-se recentemente em torno de relatos de A potencial queda de desempenho da GPT-4. Os utilizadores do GPT-4 argumentam que as capacidades do modelo diminuíram rapidamente e, embora a OpenAI tenha reconhecido que isso é verdade, não foi absolutamente clara quanto à razão pela qual isso está a acontecer. Isso levanta a questão: será que eles sabem?
A investigadora de IA, Dra. Sasha Luccioni, afirma que a falta de transparência da OpenAI é um problema que também se aplica a outros criadores de modelos de IA proprietários ou fechados. "Quaisquer resultados de modelos de código fechado não são reproduzíveis nem verificáveis e, por isso, de uma perspetiva científica, estamos a comparar guaxinins e esquilos."
“Não cabe aos cientistas monitorizar continuamente os LLM implantados. Cabe aos criadores de modelos dar acesso aos modelos subjacentes, pelo menos para efeitos de auditoria", afirmou.
Luccioni sublinhou que os criadores de modelos de IA devem fornecer resultados brutos de testes de referência padrão como o SuperGLUE e o WikiText e testes de referência tendenciosos como o BOLD e o HONEST.
É provável que a batalha contra os preconceitos e as tendências induzidos pela IA seja constante, exigindo atenção e investigação contínuas para manter os resultados dos modelos sob controlo à medida que a IA e a sociedade evoluem em conjunto.
Embora a regulamentação imponha formas de monitorização e de comunicação, existem poucas soluções rápidas e rigorosas para a questão do enviesamento algorítmico, e esta não é a última vez que ouvimos falar dela.



