

No início deste mês, a Google anunciou orgulhosamente que o seu modelo Gemini mais potente venceu o GPT-4 nos testes de referência MMLU (Massive Multitask Language Understanding). Com a nova técnica de solicitação da Microsoft, o GPT-4 recuperou o primeiro lugar, embora por uma fração de um por cento.
Para além do drama em torno do seu vídeo de marketing, o Gemini da Google é um grande negócio para a empresa e os seus resultados de referência MMLU são impressionantes. Mas a Microsoft, o maior investidor da OpenAI, não esperou muito tempo para criticar os esforços da Google.
A manchete é que a Microsoft conseguiu que o GPT-4 superasse os resultados do MMLU do Gemini Ultra. A realidade é que superou o resultado do Gemini de 90,04% por apenas 0,06%.
A história dos bastidores que tornaram isto possível é mais empolgante do que a competição incremental que vemos nestas tabelas de classificação. As novas técnicas de estímulo da Microsoft podem melhorar o desempenho de modelos de IA mais antigos.
Lembra-se de como o Gemini Ultra, ainda não lançado, da Google acabou de bater o GPT-4 para se tornar a IA de topo?
Bem, a Microsoft acabou de demonstrar que, com a devida solicitação, o GPT-4 realmente vence o Gemini nos benchmarks.
Há muito espaço para ganhos, mesmo com modelos mais antigos. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 de dezembro de 2023
Medprompt
Quando se ouve falar em "orientar" um modelo, quer-se apenas dizer que, com uma orientação cuidadosa, é possível guiar um modelo para obter um resultado que esteja melhor alinhado com o que se pretendia.
A Microsoft desenvolveu uma combinação de técnicas de solicitação que provaram ser realmente boas neste domínio. Medprompt começou como um projeto para fazer com que o GPT-4 desse melhores respostas em testes de referência de desafios médicos, como o conjunto de testes MultiMedQA.
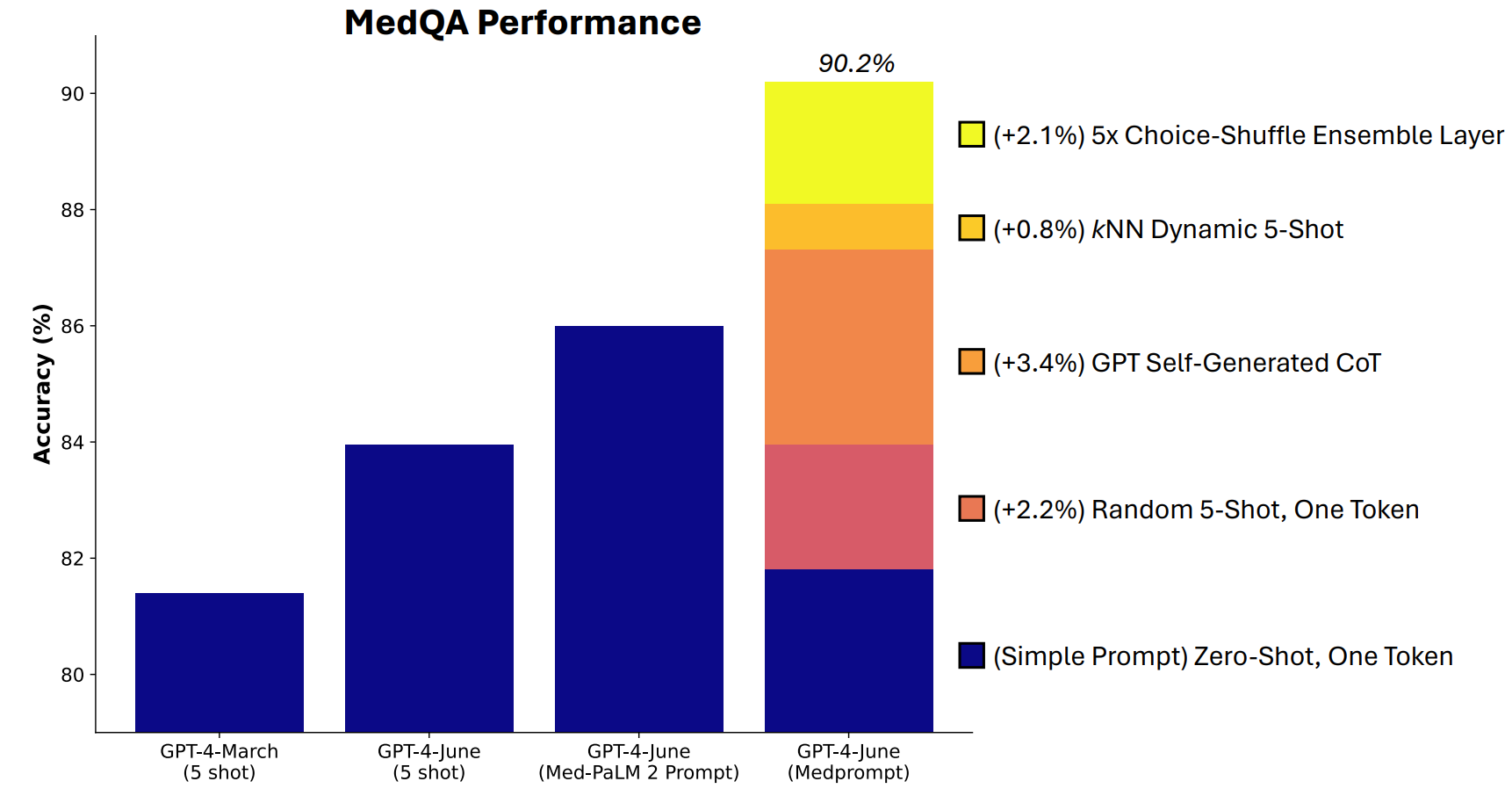
Os investigadores da Microsoft pensaram que, se o Medprompt funcionasse bem em testes médicos especializados, também poderia melhorar o desempenho generalista do GPT-4. E, assim, a Microsoft e a OpenAI recuperaram o direito de se gabarem com o GPT-4 em relação ao Gemini Ultra.
Como é que o Medprompt funciona?
O Medprompt é uma combinação de técnicas inteligentes de solicitação, todas reunidas numa só. Baseia-se em três técnicas principais.
Aprendizagem dinâmica de poucos disparos (DFSL)
A "aprendizagem com poucas tentativas" refere-se ao facto de dar ao GPT-4 alguns exemplos antes de lhe pedir para resolver um problema semelhante. Quando se vê uma referência como "5-shot", significa que foram dados 5 exemplos ao modelo. "Zero-shot" significa que teve de responder sem quaisquer exemplos.
O documento do Medprompt explica que "por uma questão de simplicidade e eficiência, os exemplos de poucos disparos aplicados na solicitação de uma determinada tarefa são normalmente fixos; mantêm-se inalterados em todos os exemplos de teste".
O resultado é que os exemplos que são apresentados aos modelos são muitas vezes apenas relevantes ou representativos em termos gerais.
Se o seu conjunto de treino for suficientemente grande, pode fazer com que o modelo analise todos os exemplos e escolha aqueles que são semanticamente semelhantes ao problema que tem de resolver. O resultado é que os exemplos de aprendizagem de poucos disparos estão mais especificamente alinhados com um determinado problema.
Cadeia de pensamento auto-gerada (CoT)
A sugestão da Cadeia de Pensamento (CoT) é uma óptima forma de orientar um LLM. Quando se diz "pense bem" ou "resolva o problema passo a passo", os resultados são muito melhores.
É possível ser muito mais específico na forma como se orienta a cadeia de pensamento que o modelo deve seguir, mas isso implica uma engenharia manual rápida.
Os investigadores descobriram que "podiam simplesmente pedir ao GPT-4 para gerar cadeias de pensamento para os exemplos de treino". A abordagem deles basicamente diz ao GPT-4: 'Aqui está uma pergunta, as opções de resposta e a resposta correcta. Que CoT deveríamos incluir num prompt que chegasse a esta resposta?
Seleção de conjuntos aleatórios
A maioria dos testes de referência do MMLU são perguntas de escolha múltipla. Quando um modelo de IA responde a estas perguntas, pode ser vítima de uma tendência posicional. Por outras palavras, pode favorecer a opção B ao longo do tempo, apesar de nem sempre ser a resposta correcta.
O Agrupamento Baralhado de Opções baralha as posições das opções de resposta e faz com que o GPT-4 responda novamente à pergunta. Faz isto várias vezes e depois a resposta mais consistentemente escolhida é selecionada como a resposta final.
A combinação destas três técnicas de prompt foi o que deu à Microsoft a oportunidade de lançar um pouco de sombra sobre os resultados do Gemini. Será interessante ver quais os resultados que o Gemini Ultra alcançaria se utilizasse uma abordagem semelhante.
O Medprompt é empolgante porque mostra que os modelos mais antigos podem ter um desempenho ainda melhor do que pensávamos, se os avisarmos de formas inteligentes. No entanto, o poder de processamento adicional necessário para estes passos extra pode não tornar esta abordagem viável na maioria dos cenários.



