

A Nvidia anunciou um novo software de código aberto que, segundo a empresa, irá melhorar o desempenho da inferência nas suas GPUs H100.
Grande parte da procura atual de GPUs da Nvidia é para criar capacidade de computação para treinar novos modelos. Mas, uma vez treinados, esses modelos precisam de ser utilizados. A inferência em IA refere-se à capacidade de um LLM como o ChatGPT para tirar conclusões ou fazer previsões a partir dos dados em que foi treinado e gerar resultados.
Quando se tenta utilizar o ChatGPT e aparece uma mensagem a dizer que os servidores estão a ficar sobrecarregados, é porque o hardware de computação está a ter dificuldades em acompanhar a procura de inferência.
A Nvidia afirma que o seu novo software, TensorRT-LLM, pode fazer com que o seu hardware atual funcione muito mais rapidamente e seja também mais eficiente em termos energéticos.
O software inclui versões optimizadas dos modelos mais populares, incluindo Meta Llama 2, OpenAI GPT-2 e GPT-3, Falcon, Mosaic MPT e BLOOM.
Utiliza algumas técnicas inteligentes, como o agrupamento mais eficiente de tarefas de inferência e técnicas de quantização, para conseguir o aumento do desempenho.
As LLM utilizam geralmente valores de vírgula flutuante de 16 bits para representar os pesos e as activações. A quantização pega nesses valores e reduz-os para valores de ponto flutuante de 8 bits durante a inferência. A maioria dos modelos consegue manter a sua exatidão com esta precisão reduzida.
As empresas que possuem infra-estruturas de computação baseadas nas GPUs H100 da Nvidia podem esperar uma enorme melhoria no desempenho da inferência sem terem de gastar um cêntimo ao utilizarem o TensorRT-LLM.
A Nvidia usou um exemplo de execução de um pequeno modelo de código aberto, GPT-J 6, para resumir artigos no conjunto de dados CNN/Daily Mail. O seu chip A100 mais antigo é utilizado como velocidade de base e depois comparado com o H100 sem e depois com o TensorRT-LLM.
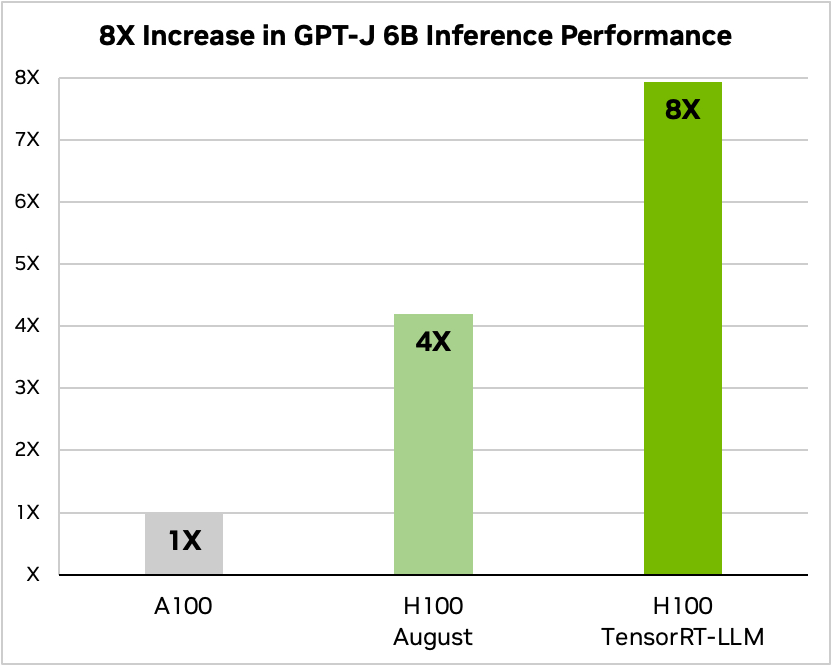
Fonte: Nvidia
E aqui está uma comparação com o Meta's Llama 2
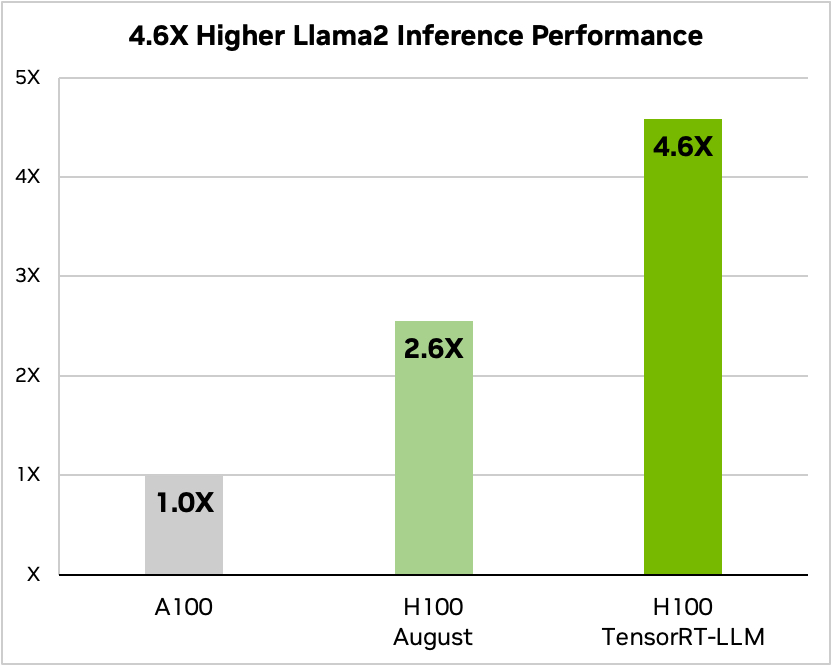
Fonte: Nvidia
A Nvidia afirmou que os seus testes mostraram que, dependendo do modelo, um H100 com TensorRT-LLM utiliza entre 3,2 e 5,6 vezes menos energia do que um A100 durante a inferência.
Se estiver a executar modelos de IA em hardware H100, isto significa que não só o seu desempenho de inferência vai quase duplicar, como também a sua fatura energética vai ser muito menor depois de instalar este software.
O TensorRT-LLM também será disponibilizado para o Grace Hopper Superchips mas a empresa ainda não divulgou os valores de desempenho do GH200 com o seu novo software.
O novo software ainda não estava pronto quando a Nvidia submeteu o seu superchip GH200 aos testes de benchmarking de desempenho MLPerf AI padrão da indústria. Os resultados mostraram que o GH200 teve um desempenho até 17% melhor do que um H100 SXM de chip único.
Se a Nvidia conseguir mesmo um modesto aumento de desempenho de inferência utilizando o TensorRT-LLM com o GH200, isso colocará a empresa muito à frente dos seus rivais mais próximos. Ser um representante de vendas da Nvidia deve ser o trabalho mais fácil do mundo neste momento.



