

Benchmarks hebben moeite om de toenemende mogelijkheden van AI-modellen bij te houden en het Humanity's Last Exam project wil jouw hulp om dit op te lossen.
Het project is een samenwerking tussen het Center for AI Safety (CAIS) en AI-databedrijf Scale AI. Het project heeft als doel om te meten hoe dicht we bij het bereiken van AI-systemen op expertniveau zijn, iets wat bestaande benchmarks niet in staat zijn.
OpenAI en CAIS ontwikkelden de populaire MMLU (Massive Multitask Language Understanding) benchmark in 2021. In die tijd, zegt CAIS, "presteerden AI-systemen niet beter dan willekeurig."
De indrukwekkende prestaties van OpenAI's o1-model hebben "de populairste benchmarks voor redeneren vernietigd", volgens Dan Hendrycks, uitvoerend directeur van CAIS.
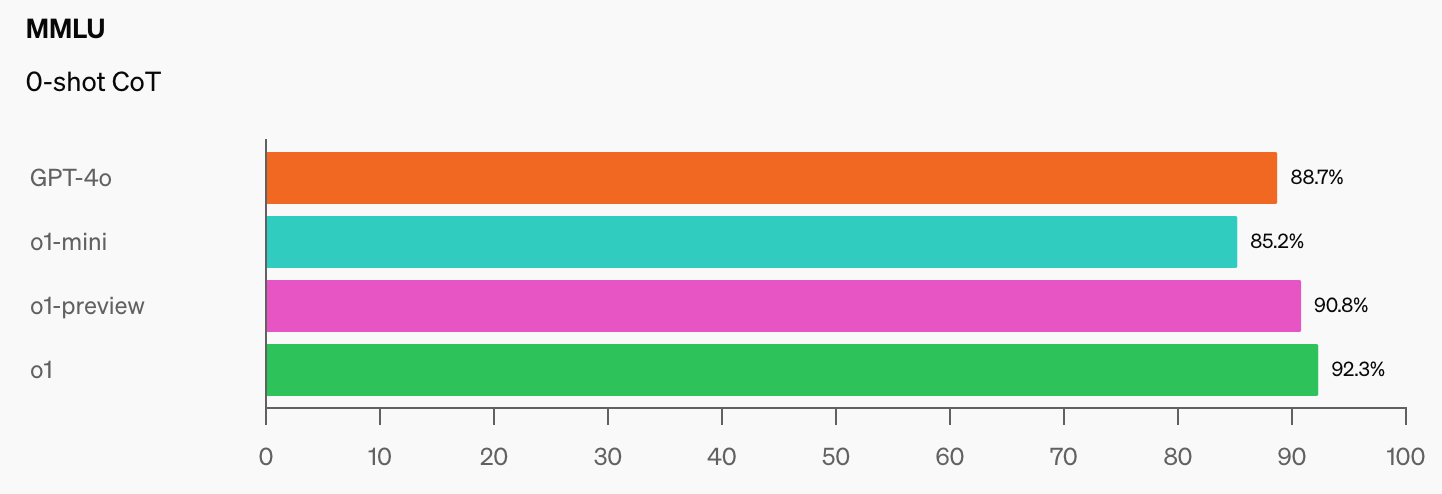
Als AI-modellen eenmaal 100% halen op het MMLU, hoe gaan we ze dan meten? CAIS zegt: "Bestaande tests zijn nu te makkelijk geworden en we kunnen de ontwikkelingen van AI niet meer goed volgen, of hoe ver ze verwijderd zijn van expert-niveau."
Als je de sprong in benchmarkscores ziet die o1 heeft toegevoegd aan de al indrukwekkende GPT-4o-cijfers, zal het niet lang meer duren voordat een AI-model de MMLU verslaat.
Dit is objectief waar. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17 september 2024
Humanity's Last Exam vraagt mensen om vragen in te sturen die je echt zouden verbazen als een AI-model het juiste antwoord zou geven. Ze willen examenvragen op PhD-niveau, niet het 'hoeveel R's in Aardbei'-type waar sommige modellen over struikelen.
Scale legde uit: "Naarmate bestaande testen te makkelijk worden, verliezen we het vermogen om onderscheid te maken tussen AI-systemen die kunnen uitblinken in examens en systemen die echt kunnen bijdragen aan grensverleggend onderzoek en het oplossen van problemen."
Als je een originele vraag hebt die een geavanceerd AI-model zou kunnen verbijsteren, kun je je naam laten toevoegen als co-auteur van de paper van het project en delen in een pool van $500.000 die zal worden toegekend aan de beste vragen.
Om je een idee te geven van het niveau waarop het project is gericht, legde Scale uit dat "als een willekeurig gekozen student kan begrijpen wat er wordt gevraagd, het waarschijnlijk te gemakkelijk is voor de grensverleggende LLM's van vandaag en morgen".
Er zijn een paar interessante beperkingen op het soort vragen dat kan worden ingediend. Ze willen niets gerelateerd aan chemische, biologische, radiologische, nucleaire wapens of cyberwapens die gebruikt worden om kritieke infrastructuur aan te vallen.
Als je denkt dat je een vraag hebt die aan de voorwaarden voldoet, kun je deze indienen hier.



