

Stanford University publiceerde zijn AI Index Report 2024 waarin wordt opgemerkt dat de snelle vooruitgang van AI benchmarkvergelijkingen met mensen steeds minder relevant maakt.
De jaarverslag geeft een uitgebreid inzicht in de trends en de stand van de AI-ontwikkelingen. Het rapport zegt dat AI-modellen nu zo snel verbeteren dat de benchmarks die we gebruiken om ze te meten steeds minder relevant worden.
Veel industriële benchmarks vergelijken AI-modellen met hoe goed mensen zijn in het uitvoeren van taken. De MMLU-benchmark (Massive Multitask Language Understanding) is daar een goed voorbeeld van.
Het gebruikt meerkeuzevragen om LLM's te evalueren in 57 vakken, waaronder wiskunde, geschiedenis, rechten en ethiek. Sinds 2019 is de MMLU de AI-benchmark bij uitstek.
De menselijke basisscore op het MMLU is 89,8% en in 2019 scoorde het gemiddelde AI-model iets meer dan 30%. Slechts 5 jaar later werd Gemini Ultra het eerste model dat de menselijke baseline versloeg met een score van 90,04%.
Het rapport merkt op dat de huidige "AI-systemen routinematig de menselijke prestaties op standaard benchmarks overtreffen". De trends in de onderstaande grafiek lijken erop te wijzen dat het MMLU en andere benchmarks aan vervanging toe zijn.
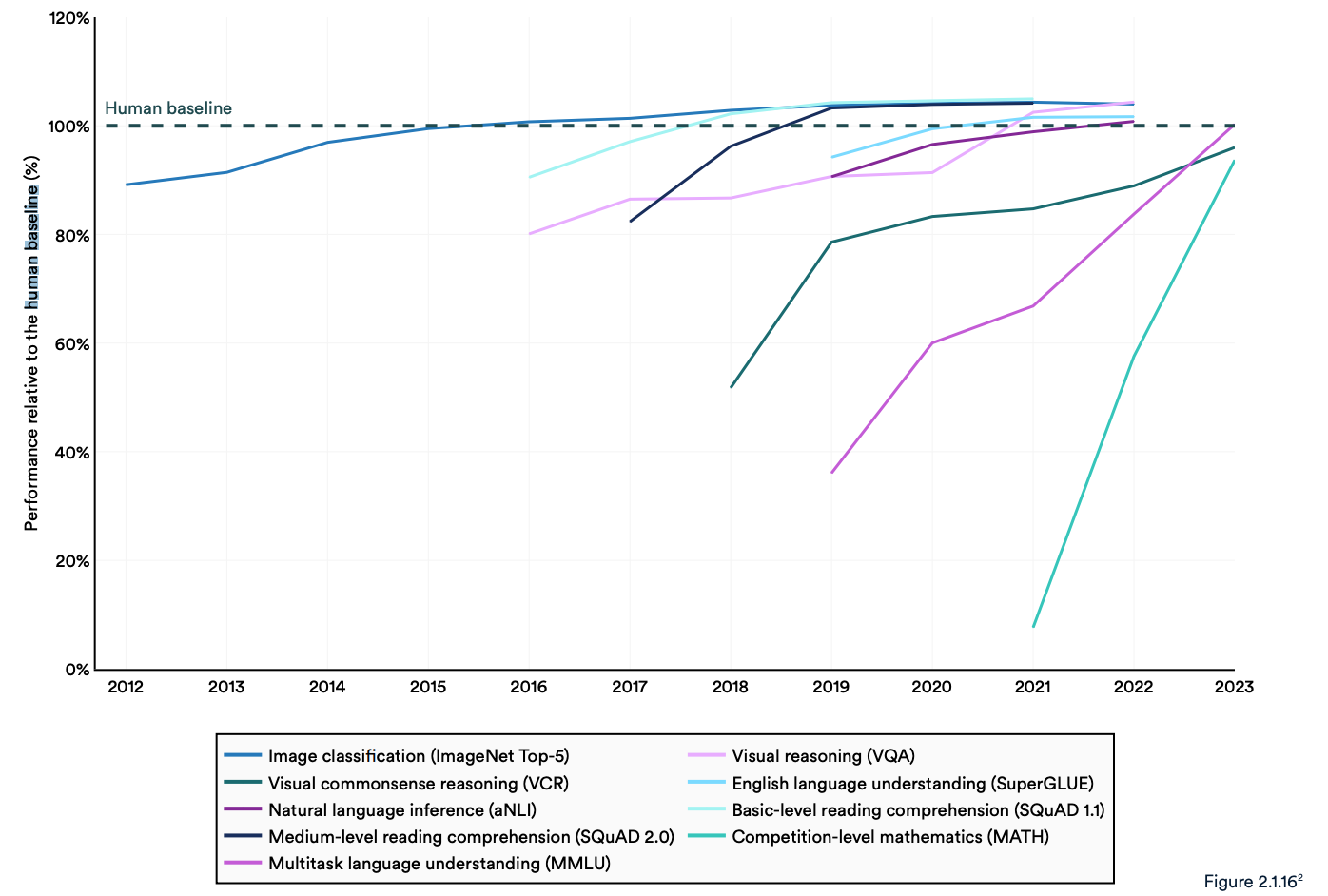
AI-modellen hebben prestatieverzadiging bereikt op gevestigde benchmarks zoals ImageNet, SQuAD en SuperGLUE, dus onderzoekers ontwikkelen meer uitdagende tests.
Een voorbeeld is de Graduate-Level Google-Proof Q&A Benchmark (GPQA), waarmee AI-modellen kunnen worden vergeleken met echt slimme mensen in plaats van met de gemiddelde menselijke intelligentie.
De GPQA test bestaat uit 400 moeilijke meerkeuzevragen op doctoraatsniveau. Experts die gepromoveerd zijn of nog promoveren beantwoorden de vragen 65% van de tijd correct.
Het GPQA-paper zegt dat wanneer vragen buiten hun vakgebied worden gesteld, "hoogopgeleide, niet-deskundige validators slechts een nauwkeurigheid van 34% bereiken, ondanks het feit dat ze gemiddeld meer dan 30 minuten onbeperkte toegang tot het web hebben".
Vorige maand kondigde Anthropic aan dat Claude 3 scoorde net onder de 60% met 5-schots CoT prompting. We hebben een grotere benchmark nodig.
Claude 3 haalt ~60% nauwkeurigheid op GPQA. Ik kan moeilijk onderschatten hoe moeilijk deze vragen zijn - letterlijke PhD's (in andere domeinen dan de vragen) met toegang tot het internet halen 34%.
PhD's *in hetzelfde domein* (ook met internettoegang!) krijgen 65% - 75% nauwkeurigheid. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4 maart 2024
Menselijke evaluaties en veiligheid
In het rapport wordt opgemerkt dat AI nog steeds met grote problemen kampt: "Het kan niet betrouwbaar omgaan met feiten, complexe redeneringen uitvoeren of zijn conclusies uitleggen."
Deze beperkingen dragen bij aan een ander kenmerk van het AI-systeem dat volgens het rapport slecht wordt gemeten; AI-veiligheid. We hebben geen effectieve benchmarks waarmee we kunnen zeggen: "Dit model is veiliger dan dat".
Dat komt deels omdat het moeilijk te meten is en deels omdat "AI-ontwikkelaars niet transparant zijn, met name wat betreft de openbaarmaking van trainingsgegevens en methodologieën".
In het rapport wordt opgemerkt dat een interessante trend in de industrie is om menselijke evaluaties van AI-prestaties te crowd-sourcen, in plaats van benchmarktests.
Het beoordelen van de beeldesthetiek of het proza van een model is moeilijk te doen met een test. Als gevolg hiervan zegt het rapport dat "benchmarking langzaam verschuift naar het opnemen van menselijke evaluaties zoals het Chatbot Arena Leaderboard in plaats van geautomatiseerde ranglijsten zoals ImageNet of SQuAD."
Terwijl AI-modellen de menselijke basislijn in de achteruitkijkspiegel zien verdwijnen, kan het sentiment uiteindelijk bepalen welk model we kiezen te gebruiken.
De trends geven aan dat AI-modellen uiteindelijk slimmer zullen zijn dan wij en moeilijker te meten. Misschien zullen we binnenkort zeggen: "Ik weet niet waarom, maar ik vind deze gewoon beter."



