

Onderzoekers van Google DeepMind hebben NATURAL PLAN ontwikkeld, een benchmark voor het evalueren van het vermogen van LLM's om echte taken te plannen op basis van aanwijzingen in natuurlijke taal.
De volgende evolutie van AI is dat het de grenzen van een chatplatform verlaat en een agentrol aanneemt om namens ons taken uit te voeren op verschillende platforms. Maar dat is moeilijker dan het klinkt.
Het plannen van taken zoals het plannen van een vergadering of het samenstellen van een vakantiereisschema lijkt misschien eenvoudig voor ons. Mensen zijn goed in het doorlopen van meerdere stappen en in het voorspellen of een actie het gewenste doel zal bereiken of niet.
U vindt dat misschien makkelijk, maar zelfs de beste AI-modellen hebben moeite met plannen. Kunnen we ze benchmarken om te zien welke LLM het beste kan plannen?
De NATURAL PLAN benchmark test LLM's op 3 planningstaken:
- Reisplanning - Een reisroute plannen met beperkingen wat betreft vlucht en bestemming
- Planning vergadering - Vergaderingen plannen met meerdere vrienden op verschillende locaties
- Agenda plannen - Werkvergaderingen plannen tussen meerdere mensen op basis van bestaande planningen en verschillende beperkingen
Het experiment begon met 'few-shot prompting' waarbij de modellen 5 voorbeelden van prompts en bijbehorende correcte antwoorden te zien kregen. Vervolgens kregen ze planningsvragen van verschillende moeilijkheidsgraad.
Hier is een voorbeeld van een vraag en een oplossing die als voorbeeld wordt gegeven aan de modellen:

Resultaten
De onderzoekers testten GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, en Gemini 1.5 Prodie geen van alle erg goed presteerden op deze tests.
De resultaten moeten echter goed zijn gevallen op het kantoor van DeepMind, want Gemini 1.5 Pro kwam als beste uit de bus.

Zoals verwacht werden de resultaten exponentieel slechter met complexere prompts waarbij het aantal mensen of steden werd verhoogd. Kijk bijvoorbeeld hoe snel de nauwkeurigheid afnam naarmate er meer mensen werden toegevoegd aan de test voor het plannen van een vergadering.
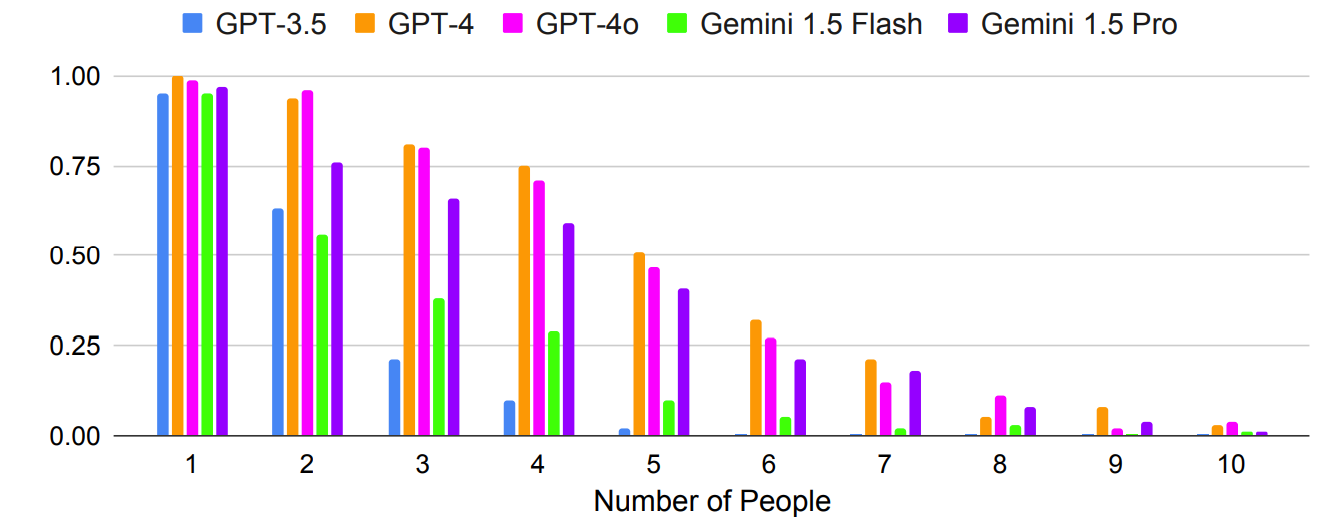
Zou multi-shot prompting kunnen leiden tot verbeterde nauwkeurigheid? De resultaten van het onderzoek geven aan dat dit kan, maar alleen als het model een contextvenster heeft dat groot genoeg is.
Het grotere contextvenster van Gemini 1.5 Pro maakt het mogelijk om meer in-contextvoorbeelden te gebruiken dan de GPT-modellen.
De onderzoekers ontdekten dat bij Reisplanning het verhogen van het aantal opnamen van 1 naar 800 de nauwkeurigheid van Gemini Pro 1.5 verbetert van 2,7% naar 39,9%.
Het papier merkten op: "Deze resultaten laten de belofte zien van in-context planning waarbij de lange-context mogelijkheden LLM's in staat stellen om verdere context te gebruiken om de planning te verbeteren."
Een vreemd resultaat was dat GPT-4o echt slecht was in Reisplanning. De onderzoekers ontdekten dat het "moeite had om de beperkingen van de vluchtconnectiviteit en reisdatum te begrijpen en te respecteren".
Een andere vreemde uitkomst was dat zelfcorrectie bij alle modellen leidde tot een significante daling van de modelprestaties. Wanneer de modellen werden gevraagd om hun werk te controleren en correcties aan te brengen, maakten ze meer fouten.
Interessant is dat de sterkere modellen, zoals GPT-4 en Gemini 1.5 Pro, grotere verliezen leden dan GPT-3.5 bij zelfcorrectie.
Agentic AI is een opwindend vooruitzicht en we zien al enkele praktische toepassingen in Microsoft Copilot agenten.
Maar de resultaten van de NATURAL PLAN benchmarktests laten zien dat we nog een lange weg te gaan hebben voordat AI complexere planningen aankan.
De DeepMind-onderzoekers concludeerden dat "NATURAL PLAN zeer moeilijk is voor geavanceerde modellen om op te lossen".
Het lijkt erop dat AI reisagenten en persoonlijke assistenten nog niet zal vervangen.



