

Een team onderzoekers van de New York University heeft vooruitgang geboekt op het gebied van neurale spraakdecodering, wat ons dichter bij een toekomst brengt waarin mensen die hun spraakvermogen hebben verloren hun stem kunnen terugkrijgen.
De onderzoek, gepubliceerd in Natuur Machine Intelligentiepresenteert een nieuw deep learning raamwerk dat hersensignalen nauwkeurig vertaalt naar verstaanbare spraak.
Mensen met hersenletsel door beroertes, degeneratieve aandoeningen of fysieke trauma's kunnen deze systemen gebruiken om te communiceren door hun gedachten of bedoelde spraak te decoderen uit neurale signalen.
Het systeem van het NYU-team bestaat uit een deep learning-model dat de elektrocorticografische (ECoG) signalen van de hersenen koppelt aan spraakkenmerken, zoals toonhoogte, luidheid en andere spectrale inhoud.
De tweede fase omvat een neurale spraaksynthesizer die de geëxtraheerde spraakkenmerken omzet in een hoorbaar spectrogram, dat vervolgens kan worden omgezet in een spraakgolfvorm.
Die golfvorm kan uiteindelijk worden omgezet in natuurlijk klinkende gesynthetiseerde spraak.
Nieuw artikel vandaag in @NatMachIntellwaarin we robuuste neurale spraakdecodering laten zien bij 48 patiënten. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Adeen Flinker 🇮🇱🇺🇦🎗️ (@adeenflinker) 9 april 2024
Hoe het onderzoek werkt
In dit onderzoek wordt een AI-model getraind dat een spraaksynthesetoestel kan aandrijven, zodat mensen met spraakverlies kunnen praten met behulp van elektrische impulsen uit hun hersenen.
Hier wordt uitgelegd hoe het werkt:
1. Gegevens over de hersenen verzamelen
De eerste stap bestaat uit het verzamelen van de ruwe gegevens die nodig zijn om het spraak-decoderingsmodel te trainen. De onderzoekers werkten met 48 deelnemers die neurochirurgie voor epilepsie ondergingen.
Tijdens het onderzoek werd deze deelnemers gevraagd om honderden zinnen hardop te lezen terwijl hun hersenactiviteit werd geregistreerd met behulp van ECoG-roosters.
Deze roosters worden direct op het hersenoppervlak geplaatst en vangen elektrische signalen op van de hersengebieden die betrokken zijn bij de spraakproductie.
2. Hersensignalen in kaart brengen voor spraak
Met behulp van spraakgegevens ontwikkelden de onderzoekers een geavanceerd AI-model dat de opgenomen hersensignalen in kaart brengt voor specifieke spraakkenmerken, zoals toonhoogte, luidheid en de unieke frequenties waaruit verschillende spraakklanken bestaan.
3. Spraak synthetiseren op basis van kenmerken
In de derde stap worden de spraakkenmerken uit de hersensignalen omgezet in hoorbare spraak.
De onderzoekers gebruikten een speciale spraaksynthesizer die de geëxtraheerde kenmerken opneemt en een spectrogram genereert - een visuele weergave van de spraakklanken.
4. De resultaten evalueren
De onderzoekers vergeleken de spraak die door hun model werd gegenereerd met de originele spraak van de deelnemers.
Ze gebruikten objectieve meetmethoden om de gelijkenis tussen de twee te meten en ontdekten dat de gegenereerde spraak nauw aansloot bij de inhoud en het ritme van het origineel.
5. Testen op nieuwe woorden
Om ervoor te zorgen dat het model nieuwe woorden kan verwerken die het nog niet eerder heeft gezien, werden bepaalde woorden opzettelijk weggelaten tijdens de trainingsfase van het model, waarna de prestaties van het model op deze ongeziene woorden werden getest.
Het vermogen van het model om zelfs nieuwe woorden nauwkeurig te decoderen toont aan dat het model kan generaliseren en verschillende spraakpatronen kan verwerken.
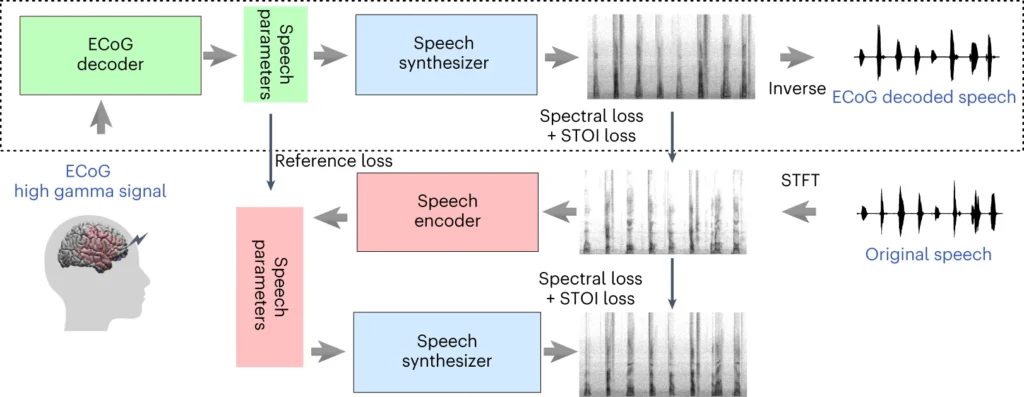
Het bovenste deel van het bovenstaande diagram beschrijft een proces voor het omzetten van hersensignalen naar spraak. Eerst zet een decoder deze signalen in de loop van de tijd om in spraakparameters. Vervolgens maakt een synthesizer geluidsbeelden (spectrogrammen) van deze parameters. Een ander hulpmiddel verandert deze beelden weer in geluidsgolven.
Het onderste gedeelte bespreekt een systeem dat de hersensignaaldecoder helpt trainen door spraak na te bootsen. Het neemt een geluidsbeeld, zet het om in spraakparameters en gebruikt die vervolgens om een nieuw geluidsbeeld te maken. Dit deel van het systeem leert van echte spraakgeluiden te verbeteren.
Na de training is alleen het bovenste proces nodig om hersensignalen om te zetten in spraak.
Een belangrijk voordeel van het systeem van NYU is de mogelijkheid om spraakdecodering van hoge kwaliteit te bereiken zonder de noodzaak van elektrode-arrays met ultrahoge dichtheid, die onpraktisch zijn voor langdurig gebruik.
In wezen biedt het een meer lichtgewicht, draagbare oplossing.
Een andere prestatie is het succesvol decoderen van spraak van zowel de linker- als de rechterhersenhelft, wat belangrijk is voor patiënten met hersenbeschadiging aan één kant van de hersenen.
Gedachten omzetten in spraak met behulp van AI
Het onderzoek van NYU bouwt voort op eerder onderzoek naar neurale spraakdecodering en brein-computer interfaces (BCI's).
In 2023 stelde een team van de Universiteit van Californië in San Francisco een verlamde overlevende van een beroerte in staat om zinnen genereren met een snelheid van 78 woorden per minuut met behulp van een BCI die zowel vocalisaties als gezichtsuitdrukkingen synthetiseerde uit hersensignalen.
Andere recente studies hebben het gebruik van AI onderzocht om verschillende aspecten van het menselijk denken uit hersenactiviteit te interpreteren. Onderzoekers hebben aangetoond dat ze beelden, tekst en zelfs muziek kunnen genereren uit MRI- en EEG-gegevens van de hersenen.
Bijvoorbeeld een onderzoek van de universiteit van Helsinki gebruikten EEG-signalen om een generative adversarial network (GAN) te leiden bij het produceren van gezichtsbeelden die overeenkwamen met de gedachten van de deelnemers.
Meta AI ook een techniek ontwikkeld om gedeeltelijk te decoderen waar iemand naar luisterde met behulp van hersengolven die niet-invasief werden verzameld.
Kansen en uitdagingen
De methode van NYU maakt gebruik van meer algemeen beschikbare en klinisch levensvatbare elektroden dan eerdere methoden, waardoor het toegankelijker is.
Hoewel dit opwindend is, zijn er nog grote obstakels te overwinnen als we wijdverspreid gebruik willen meemaken.
Ten eerste is het verzamelen van hersengegevens van hoge kwaliteit een complexe en tijdrovende bezigheid. Individuele verschillen in hersenactiviteit maken generalisatie moeilijk, wat betekent dat een model dat is getraind voor de ene groep deelnemers mogelijk niet goed werkt voor een andere groep.
Desalniettemin is het NYU-onderzoek een stap in deze richting door het aantonen van zeer nauwkeurige spraakdecodering met behulp van lichtere elektrode-arrays.
In de toekomst wil het NYU-team hun modellen voor realtime spraakdecodering verfijnen, zodat we dichter bij het uiteindelijke doel komen: natuurlijke, vloeiende gesprekken mogelijk maken voor mensen met spraakproblemen.
Ze zijn ook van plan om het systeem aan te passen aan implanteerbare draadloze apparaten die in het dagelijks leven gebruikt kunnen worden.



