

Google's DeepMind Gecko uitgebracht, een nieuwe benchmark voor het uitgebreid evalueren van AI tekst-naar-beeld (T2I) modellen.
De afgelopen twee jaar hebben we AI-afbeeldingsgeneratoren gezien zoals DALL-E en Reis halverwege worden met elke nieuwe versie steeds beter.
Het bepalen welke van de onderliggende modellen die deze platforms gebruiken het beste is, is echter grotendeels subjectief en moeilijk te benchmarken.
Het is niet zo eenvoudig om te beweren dat het ene model "beter" is dan het andere. Verschillende modellen blinken uit in verschillende aspecten van het genereren van afbeeldingen. Het ene model kan goed zijn in het renderen van tekst, terwijl het andere beter is in objectinteractie.
Een belangrijke uitdaging voor T2I-modellen is om elk detail in de prompt te volgen en deze nauwkeurig weer te geven in het gegenereerde beeld.
Met Gecko is de DeepMind onderzoekers hebben een benchmark dat de capaciteiten van T2I-modellen evalueert zoals mensen dat doen.
Vaardigheden
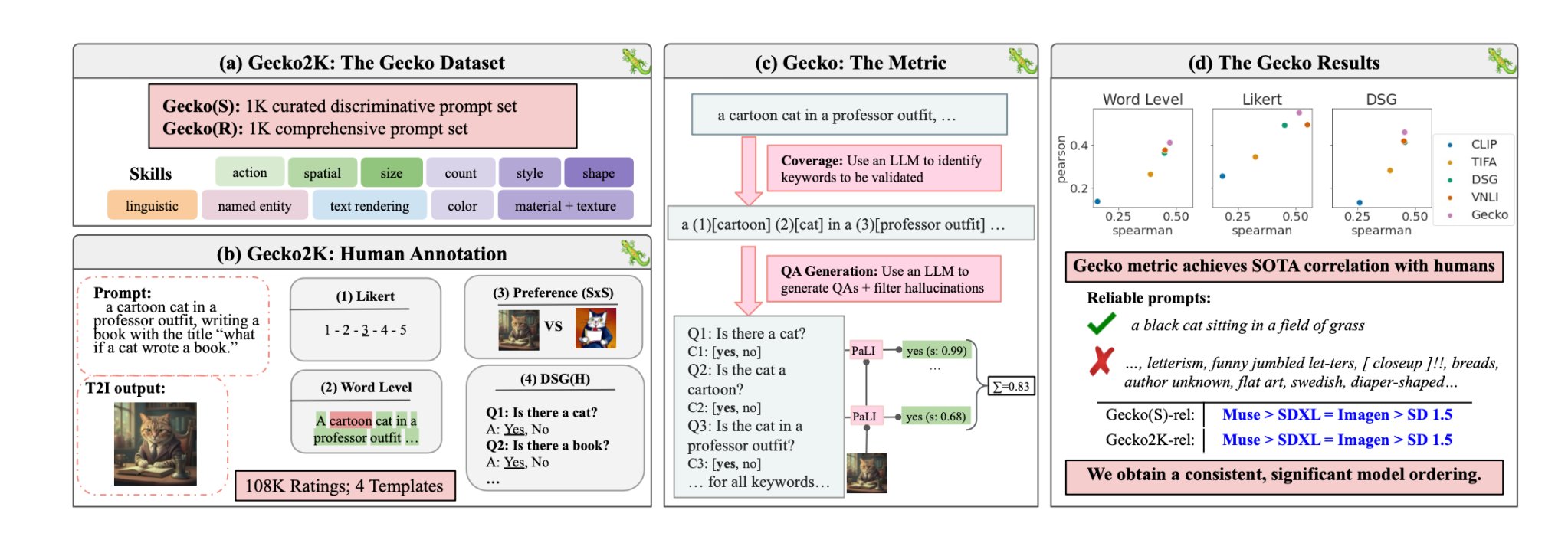
De onderzoekers definieerden eerst een uitgebreide dataset van vaardigheden die relevant zijn voor het genereren van T2I. Deze omvatten ruimtelijk inzicht, actieherkenning, tekstweergave en andere. Ze splitsten deze verder op in meer specifieke subvaardigheden.
Onder tekstweergave kunnen bijvoorbeeld subvaardigheden staan voor het renderen van verschillende lettertypes, kleuren of tekstgroottes.
Een LLM werd vervolgens gebruikt om aanwijzingen te genereren om de mogelijkheden van het T2I-model te testen op een specifieke vaardigheid of subvaardigheid.
Hierdoor kunnen de makers van een T2I-model niet alleen bepalen welke vaardigheden een uitdaging vormen, maar ook op welk niveau van complexiteit een vaardigheid een uitdaging wordt voor hun model.
Mens vs auto-eval
Gecko meet ook hoe nauwkeurig een T2I-model alle details in een prompt volgt. Ook hier werd een LLM gebruikt om de belangrijkste details in elke invoeraanwijzing te isoleren en vervolgens een reeks vragen te genereren die betrekking hadden op die details.
Deze vragen kunnen zowel eenvoudige, directe vragen zijn over zichtbare elementen in de afbeelding (bv. "Is er een kat in de afbeelding?") als complexere vragen die het begrip van de scène of de relaties tussen objecten testen (bv. "Zit de kat boven het boek?").
Een Visual Question Answering (VQA) model analyseert vervolgens de gegenereerde afbeelding en beantwoordt de vragen om te zien hoe nauwkeurig het T2I-model zijn uitvoerbeeld afstemt op een invoervraag.
De onderzoekers verzamelden meer dan 100.000 menselijke annotaties waarbij de deelnemers een gegenereerde afbeelding scoorden op basis van hoe goed de afbeelding was uitgelijnd met specifieke criteria.
De mensen werd gevraagd om een specifiek aspect van de invoeropdracht te overwegen en de afbeelding te scoren op een schaal van 1 tot 5 op basis van hoe goed deze overeenkwam met de opdracht.
Met behulp van de menselijke beoordelingen als gouden standaard konden de onderzoekers bevestigen dat hun auto-eval metriek "beter gecorreleerd is met menselijke beoordelingen dan bestaande metrieken voor onze nieuwe dataset."
Het resultaat is een benchmarksysteem dat in staat is om specifieke factoren die een gegenereerde afbeelding goed of slecht maken, te kwantificeren.
Gecko scoort in wezen de uitvoerafbeelding op een manier die nauw aansluit bij hoe we intuïtief beslissen of we al dan niet tevreden zijn met de gegenereerde afbeelding.
Wat is dan het beste tekst-naar-beeld model?
In hun papierconcludeerden de onderzoekers dat Google's Muse-model Stable Diffusion 1.5 en SDXL verslaat met de Gecko-benchmark. Ze zijn misschien bevooroordeeld, maar de cijfers liegen niet.



