

Mistral AI is een Franse AI startup die de krantenkoppen haalt met zijn lichtgewicht open-source modellen. Samen met de aandacht kwam er een nieuwe financieringsbatch, aangezien het deze week een investering van €385m, of $414m, veiligstelde.
De tweede financieringsronde van het bedrijf werd geleid door durfkapitaalbedrijven Andreessen Horowitz en Lightspeed Venture Partners.
De discussie over open-source modellen versus propriëtaire modellen is aan de gang en Mistral AI staat resoluut aan de open-source kant.
Bedrijven als OpenAI zijn bekritiseerd voor hun angstzaaierij over de veiligheid van open-source modellen, waarbij velen zeggen dat het een geval is van Big Tech die zijn hegemonie probeert te behouden.
Mistral AI zegt dat door het trainen van zijn eigen modellen "deze openlijk vrij te geven en bijdragen vanuit de gemeenschap te stimuleren, we een geloofwaardig alternatief kunnen bouwen voor de opkomende AI-oligopolie. Open-gewicht generatieve modellen zullen een cruciale rol spelen in de komende AI-revolutie."
Verschillende grote investeerders hebben hun vertrouwen in deze strategie bevestigd. Met de financiering die Mistral AI deze week binnenhaalde, wordt het bedrijf gewaardeerd op $2 miljard. Dat is een 7x hogere waardering in de zes maanden sinds de lancering van het bedrijf.
Mixtral 8x7B
In september verscheen Mistral 7B, Mistral AI's kleine maar krachtige LLM die grotere open-source modellen zoals Meta's lama 2 34B.
De eigen GPT-modellen van OpenAI worden terecht beschouwd als de gouden standaard bij het vergelijken van modelprestaties. Met het nieuwe model van Mistral AI, Mixtral 8x7BHet bedrijf heeft zich in dit opzicht verzekerd van aanzienlijke opscheppingsrechten.
Mixtral 8x7B is een dun mengsel van deskundigen model met een 32k contextvenster. Hier is te zien hoe het presteerde in benchmarktests vergeleken met Llama 2 en GPT-3.5.
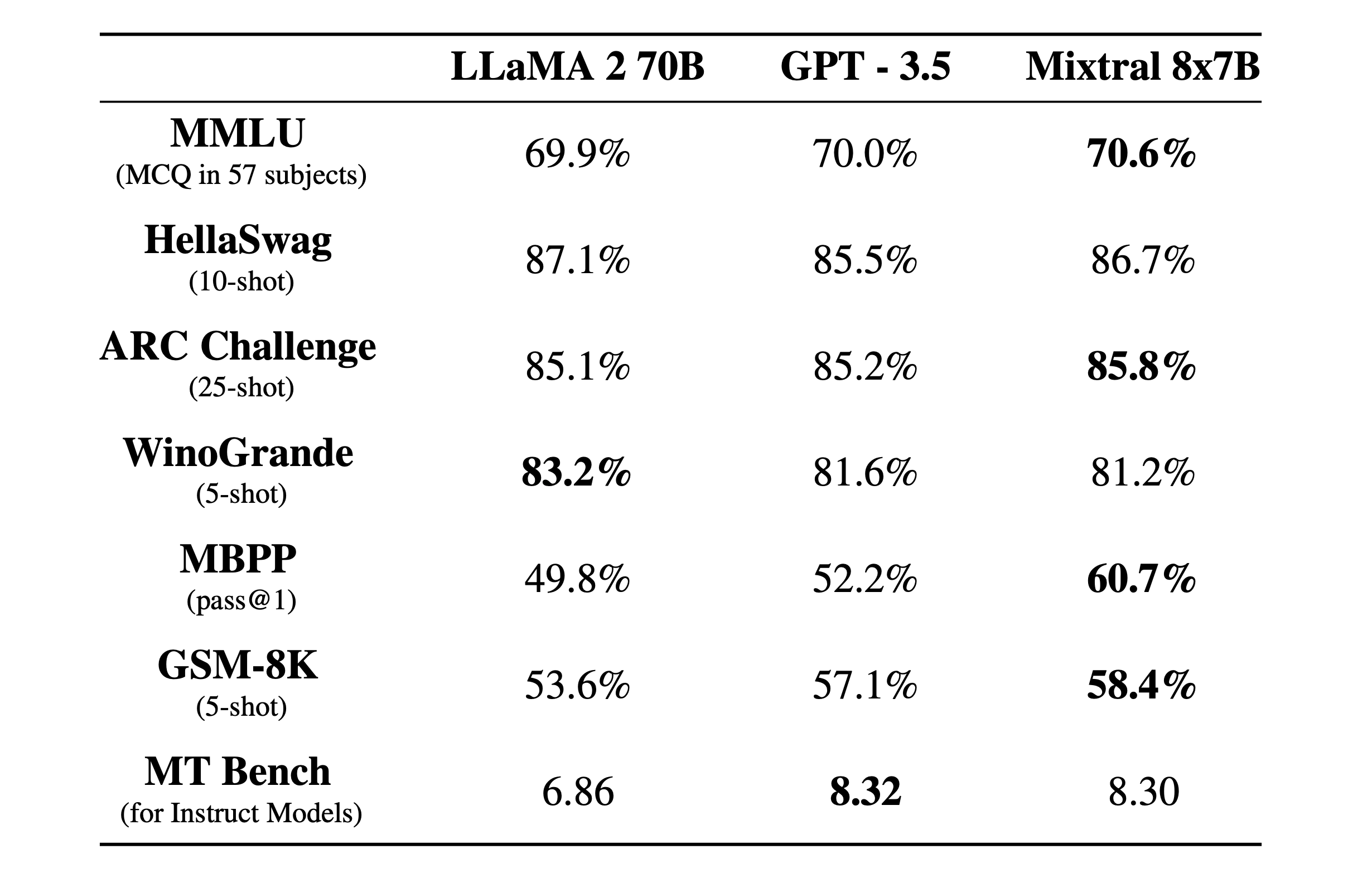
De benchmarktests zijn een goede manier om een idee te krijgen van hoe goed een model is in het uitvoeren van verschillende functies. De tests hierboven waren:
- MMLU (MCQ in 57 vakken): Staat voor Meerkeuzevragen in 57 vakken.
- HellaSwag (10-schots): Evalueert het vermogen van de AI om het einde van een scenario te voorspellen nadat 10 voorbeelden zijn gegeven.
- ARC-uitdaging (25 shots): Test of de AI wetenschappelijke concepten en redeneringen begrijpt nadat hij 25 voorbeelden heeft gekregen om van te leren voordat hij wordt getest.
- WinoGrande (5-schots): Test gezond verstand redeneren gebaseerd op het oplossen van dubbelzinnigheden in zinnen, met 5 voorbeelden voor de AI om van te leren.
- MBPP (pass@1): Hiermee wordt getest of een AI-model in staat is om correcte Python-codefragmenten te genereren. De pass@1-metriek meet het percentage problemen waarbij de eerste voltooiing van het model correct was.
- GSM-8K (5-schots): De Grade School Math 8K-benchmark test het vermogen van een AI om wiskundige woordproblemen op te lossen op het niveau dat verwacht wordt op de basisschool nadat hij 5 voorbeelden heeft gekregen.
- MT Benchmark (voor instructiemodellen): Machine Translation Benchmark voor instructiemodellen meet hoe goed een AI instructies kan opvolgen in de context van vertaaltaken.
Wat nog indrukwekkender is dan de benchmarktestresultaten, is hoe klein en efficiënt de Mixtral 8x7B is. Je zou dit model lokaal kunnen draaien op een fatsoenlijke laptop met ongeveer 32 GB RAM.
Met veel meer geld tot zijn beschikking, kunnen we een aantal spannende ontwikkelingen verwachten van Mistral AI.



