

In het tijdperk van AI is er sprake van een complexe wisselwerking tussen technologie en maatschappelijke attitudes.
De toenemende geavanceerdheid van AI-systemen doet de grenzen tussen mens en machine vervagen - staat AI-technologie los van onszelf? In hoeverre erft AI naast vaardigheden en kennis ook menselijke gebreken en tekortkomingen?
Het is misschien verleidelijk om je AI voor te stellen als een empirische technologie, onderstreept door de objectiviteit van wiskunde, code en berekeningen.
We zijn ons echter gaan realiseren dat de beslissingen die AI-systemen nemen zeer subjectief zijn, gebaseerd op de gegevens waaraan ze worden blootgesteld - en mensen beslissen hoe ze deze gegevens selecteren en samenvoegen.
Daarin schuilt een uitdaging, aangezien AI-trainingsgegevens vaak de bias, vooroordelen en discriminatie belichamen die de mensheid bestrijdt.
Zelfs schijnbaar subtiele vormen van onbewuste vooringenomenheid kunnen worden uitvergroot door het trainingsproces van het model en zich uiteindelijk openbaren in de vorm van onder andere onjuiste overeenkomsten tussen gezichten bij wetshandhaving, geweigerde kredieten, verkeerde diagnoses van ziekten en verminderde veiligheidsmechanismen voor zelfrijdende voertuigen.
De pogingen van de mensheid om discriminatie in de hele samenleving te voorkomen zijn nog in volle gang, maar AI stuurt op dit moment cruciale besluitvorming aan.
Kunnen we snel genoeg werken om AI te synchroniseren met moderne waarden en vooringenomen levensveranderende beslissingen en gedrag te voorkomen?
Vooroordelen in AI ontrafelen
In de afgelopen tien jaar is gebleken dat AI-systemen maatschappelijke vooroordelen weerspiegelen.
Deze systemen zijn niet inherent bevooroordeeld - in plaats daarvan absorberen ze de vooroordelen van hun makers en de gegevens waarop ze getraind zijn.
AI-systemen leren, net als mensen, door blootstelling. Het menselijk brein is een schijnbaar eindeloze index van informatie - een bibliotheek met bijna onbeperkte planken waar we ervaringen, kennis en herinneringen opslaan.
Neurowetenschappelijk studies laten zien dat de hersenen niet echt een 'maximale capaciteit' hebben en tot op hoge leeftijd informatie blijven sorteren en opslaan.
Hoewel het verre van perfect is, helpt het progressieve, iteratieve leerproces van de hersenen ons om ons aan te passen aan nieuwe culturele en maatschappelijke waarden, van het toestaan van stemrecht voor vrouwen en het accepteren van verschillende identiteiten tot het beëindigen van slavernij en andere vormen van bewuste vooroordelen.
WWe leven nu in een tijdperk waarin AI-tools worden gebruikt voor kritische besluitvorming in plaats van menselijk oordeel.
Veel machine learning (ML) modellen leren van trainingsgegevens die de basis vormen van hun besluitvorming en kunnen nieuwe informatie niet zo efficiënt invoeren als het menselijk brein. Daardoor slagen ze er vaak niet in om de up-to-date, tot op de minuut nauwkeurige beslissingen te nemen waarvoor we van ze afhankelijk zijn.
AI-modellen worden bijvoorbeeld gebruikt om overeenkomsten in gezichten te identificeren voor wetshandhavingsdoeleinden, cv's analyseren voor sollicitatiesen gezondheidskritische beslissingen nemen in een klinische omgeving.
Naarmate de maatschappij AI verder integreert in ons dagelijks leven, moeten we ervoor zorgen dat het voor iedereen gelijk en accuraat is.
Momenteel is dit niet het geval.
Casestudies in AI-vooringenomenheid
Er zijn talloze voorbeelden van AI-gerelateerde vooroordelen, vooroordelen en discriminatie.
In sommige gevallen zijn de gevolgen van AI-bias levensveranderend, terwijl ze in andere gevallen op de achtergrond blijven hangen en beslissingen subtiel beïnvloeden.
1. Vertekening van de dataset van MIT
Een MIT-trainingsdataset uit 2008 genaamd Kleine afbeeldingen bevatte ongeveer 80.000.000 afbeeldingen in ongeveer 75.000 categorieën.
Het werd oorspronkelijk ontworpen om AI-systemen te leren mensen en objecten in afbeeldingen te herkennen en werd een populaire benchmark dataset voor verschillende toepassingen in computer vision (CV).
A 2020 analyse door The Register ontdekten dat veel Tiny Images bevatte obscene, racistische en seksistische labels.
Antonio Torralba van MIT zei dat het lab niet op de hoogte was van deze aanstootgevende labels en vertelde The Register: "Het is duidelijk dat we ze handmatig hadden moeten screenen." MIT gaf later een verklaring uit waarin stond dat ze de dataset hadden verwijderd.

Dit is niet de enige keer dat een voormalige benchmark dataset vol problemen zit. De Labeled Faces in the Wild (LFW), een dataset van gezichten van beroemdheden die veel wordt gebruikt in gezichtsherkenningstaken, bestaat uit 77,5% mannen en 83,5% blanke individuen.
Veel van deze oude datasets hebben hun weg gevonden naar moderne AI-modellen, maar zijn afkomstig uit een tijdperk van AI-ontwikkeling waarin de focus lag op het bouwen van systemen die gewoon werken in plaats van die welke geschikt zijn voor gebruik in echte scenario's.
Als een AI-systeem eenmaal is getraind op zo'n dataset, heeft het niet noodzakelijkerwijs hetzelfde voorrecht als het menselijk brein om zich aan te passen aan hedendaagse waarden.
Hoewel modellen iteratief kunnen worden bijgewerkt, is dit een langzaam en onvolmaakt proces dat het tempo van de menselijke ontwikkeling niet kan bijhouden.
2: Beeldherkenning: vooroordeel tegen personen met een donkere huidskleur
In 2019 zal de Amerikaanse overheid vond dat de best presterende gezichtsherkenningssystemen zwarte mensen 5 tot 10 keer vaker verkeerd identificeren dan blanke mensen.
Dit is niet zomaar een statistische anomalie - het heeft ernstige gevolgen voor de echte wereld, variërend van Google Foto's die zwarte mensen als gorilla's herkennen tot zelfrijdende auto's die mensen met een donkere huidskleur niet herkennen en tegen ze aan rijden.
Daarnaast was er een golf van onterechte arrestaties en gevangenisstraffen waarbij gezichtsvergelijkingen werden gemaakt. Nijeer Parks die vals beschuldigd werd van winkeldiefstal en verkeersovertredingen, ondanks het feit dat hij 30 mijl van het incident vandaan was. Parks bracht vervolgens 10 dagen door in de gevangenis en moest duizenden aan juridische kosten betalen.

De invloedrijke studie van 2018, Geslacht Tintenonderzocht verder algoritmische bias. Het onderzoek analyseerde algoritmen van IBM en Microsoft en vond een slechte nauwkeurigheid wanneer ze werden blootgesteld aan vrouwen met een donkere huidskleur, met foutpercentages die tot 34% hoger lagen dan bij mannen met een lichtere huidskleur.
Dit patroon bleek consistent te zijn bij 189 verschillende algoritmen.
De onderstaande video van de hoofdonderzoeker van het onderzoek, Joy Buolamwini, geeft een uitstekende uitleg over hoe gezichtsherkenning verschilt per huidskleur.
3: OpenAI's CLIP-project
OpenAI's CLIP-project, uitgebracht in 2021, ontworpen om afbeeldingen te matchen met beschrijvende tekst, illustreerde ook voortdurende problemen met vooroordelen.
In een controleverslag benadrukten de makers van CLIP hun bezorgdheid door te stellen: "CLIP kende sommige labels die beroepen met een hoge status beschreven onevenredig vaak toe aan mannen, zoals 'leidinggevende' en 'dokter'. Dit is vergelijkbaar met de vooroordelen die zijn gevonden in Google Cloud Vision (GCV) en wijst op historische genderverschillen."
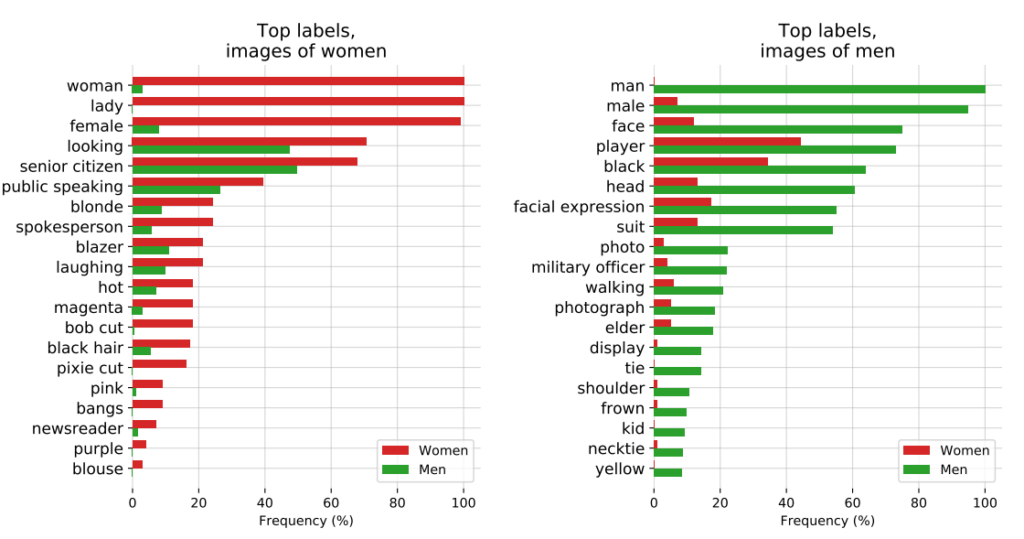
4: Wetshandhaving: de PredPol-controverse
Een ander voorbeeld van algoritmische vooringenomenheid waarbij veel op het spel staat, is PredPol, een algoritme voor voorspellend politiewerk dat door verschillende politieafdelingen in de Verenigde Staten wordt gebruikt.
PredPol werd getraind op historische misdaadgegevens om toekomstige criminaliteitshaarden te voorspellen.
Omdat deze gegevens echter inherent bevooroordeelde politiepraktijken weerspiegelen, is het algoritme bekritiseerd voor het bestendigen van raciale profilering en het onevenredig treffen van minderheidswijken.
5: Vertekening in dermatologie AI
In de gezondheidszorg worden de potentiële risico's van AI nog duidelijker.
Neem het voorbeeld van AI-systemen die zijn ontworpen om huidkanker op te sporen. Veel van deze systemen zijn getraind op datasets die voor het overgrote deel bestaan uit mensen met een lichte huid.
A 2021 onderzoek door de Universiteit van Oxford onderzochten 21 open-access datasets voor afbeeldingen van huidkanker. Ze ontdekten dat van de 14 datasets die hun geografische herkomst onthulden, er 11 uitsluitend bestonden uit afbeeldingen uit Europa, Noord-Amerika en Oceanië.
Slechts 2.436 van de 106.950 afbeeldingen in de 21 databases hadden informatie over het huidtype. De onderzoekers merkten op dat "er slechts 10 afbeeldingen waren van mensen met een bruine huid en één van een persoon met een donkerbruine of zwarte huid".
Wat betreft gegevens over etniciteit, gaven slechts 1.585 afbeeldingen deze informatie. De onderzoekers ontdekten dat "er geen afbeeldingen waren van personen met een Afrikaanse, Afrikaans-Caribische of Zuid-Aziatische achtergrond".
Ze concludeerden: "In combinatie met de geografische herkomst van de datasets was er een enorme ondervertegenwoordiging van huidlaesiebeelden van donkerder gekleurde bevolkingsgroepen."
Als dergelijke AI's worden ingezet in klinische omgevingen, creëren bevooroordeelde datasets een zeer reëel risico op verkeerde diagnoses.
Het ontleden van vooroordelen in AI-trainingsdatasets: een product van hun makers?
Trainingsgegevens - meestal tekst, spraak, afbeeldingen en video - bieden een gesuperviseerd machine learning (ML) model een basis voor het leren van concepten.
AI-systemen zijn in eerste instantie niets meer dan lege doeken. Ze leren en vormen associaties op basis van onze gegevens en schilderen in wezen een beeld van de wereld zoals afgebeeld door hun trainingsdatasets.
Door te leren van trainingsgegevens hoopt men dat het model de geleerde concepten zal toepassen op nieuwe, ongeziene gegevens.
Eenmaal ingezet, kunnen sommige geavanceerde modellen leren van nieuwe gegevens, maar hun trainingsgegevens bepalen nog steeds hun fundamentele prestaties.
De eerste vraag die moet worden beantwoord is: waar komen de gegevens vandaan? Gegevens die verzameld zijn uit niet-representatieve, vaak homogene en historisch onrechtvaardige bronnen zijn problematisch.
Dat geldt waarschijnlijk voor een aanzienlijke hoeveelheid online gegevens, waaronder tekst- en beeldgegevens die uit 'open' of 'openbare' bronnen zijn geschraapt.
Het internet is nog maar tientallen jaren geleden ontworpen, maar het is geen wondermiddel voor menselijke kennis en het is verre van rechtvaardig. De helft van de wereld gebruikt het internet niet, laat staan dat ze eraan bijdragen, wat betekent dat het fundamenteel niet representatief is voor de wereldwijde samenleving en cultuur.
Hoewel AI-ontwikkelaars er voortdurend aan werken om ervoor te zorgen dat de voordelen van de technologie niet beperkt blijven tot de Engelstalige wereld, wordt de meerderheid van de trainingsgegevens (tekst en spraak) in het Engels geproduceerd, wat betekent dat Engelstalige medewerkers de uitvoer van het model bepalen.
Onderzoekers van Anthropic onlangs een artikel uitgebracht over dit onderwerp en concludeerde: "Als een taalmodel bepaalde meningen disproportioneel vertegenwoordigt, dreigt het potentieel ongewenste effecten op te leggen zoals het promoten van hegemonische wereldbeelden en het homogeniseren van de perspectieven en overtuigingen van mensen."
Uiteindelijk werken AI-systemen weliswaar op basis van de 'objectieve' principes van wiskunde en programmeren, maar ze bestaan binnen en worden gevormd door een diep subjectieve menselijke sociale context.
Mogelijke oplossingen voor algoritmische vertekening
Als gegevens het fundamentele probleem zijn, lijkt de oplossing voor het bouwen van rechtvaardige modellen misschien eenvoudig: je hoeft alleen maar datasets evenwichtiger te maken, toch?
Niet helemaal. A Onderzoek 2019 toonde aan dat het in evenwicht brengen van datasets onvoldoende is, omdat algoritmen nog steeds onevenredig reageren op beschermde kenmerken zoals geslacht en ras.
De auteurs schrijven: "Verrassend genoeg laten we zien dat zelfs wanneer datasets gebalanceerd zijn zodat elk label even vaak voorkomt bij elk geslacht, geleerde modellen de associatie tussen labels en geslacht versterken, net zoveel als wanneer de data niet gebalanceerd waren!".
Ze stellen een de-biasingtechniek voor waarbij dergelijke labels helemaal uit de dataset worden verwijderd. Andere technieken zijn het toevoegen van willekeurige verstoringen en vervormingen, die de aandacht van een algoritme voor specifieke beschermde kenmerken verminderen.
Hoewel het aanpassen van trainingsmethoden voor machine learning en optimalisatie inherent zijn aan het produceren van niet-vooringenomen output, zijn geavanceerde modellen bovendien gevoelig voor verandering of 'drift', wat betekent dat hun prestaties niet noodzakelijk consistent blijven op de lange termijn.
Een model kan volledig onbevooroordeeld zijn bij de introductie, maar later bevooroordeeld worden naarmate het meer blootgesteld wordt aan nieuwe gegevens.
De beweging voor algoritmische transparantie
In haar provocerende boek Kunstmatige onintelligentie: Hoe computers de wereld verkeerd begrijpenMeredith Broussard pleit voor meer "algoritmische transparantie" om AI-systemen bloot te stellen aan meerdere niveaus van voortdurende controle.
Dit betekent duidelijke informatie geven over hoe het systeem werkt, hoe het getraind is en op welke gegevens het getraind is.
Terwijl transparantie-initiatieven gemakkelijk worden opgenomen in het open-source AI-landschap, zijn gepatenteerde modellen zoals GPT, Bard en Anthropic's Claude 'zwarte dozen' en alleen hun ontwikkelaars weten precies hoe ze werken - en zelfs dat is een punt van discussie.
Het 'black box' probleem bij AI betekent dat externe waarnemers alleen zien wat er in het model gaat (input) en wat eruit komt (output). De innerlijke mechanismen zijn volledig onbekend, behalve voor de makers - net zoals de Magische Cirkel de geheimen van goochelaars afschermt. AI haalt gewoon het konijn uit de hoed.
De black box-kwestie is onlangs uitgekristalliseerd rond rapporten over GPT-4's potentiële prestatiedaling. GPT-4 gebruikers beweren dat de capaciteiten van het model snel zijn afgenomen en hoewel OpenAI erkent dat dit waar is, zijn ze niet helemaal duidelijk geweest over waarom dit gebeurt. Dat roept de vraag op: weten ze het eigenlijk wel?
AI-onderzoeker Dr. Sasha Luccioni zegt dat het gebrek aan transparantie van OpenAI een probleem is dat ook geldt voor andere propriëtaire of gesloten AI-modelontwikkelaars. "Alle resultaten op closed-source modellen zijn niet reproduceerbaar en niet verifieerbaar, en daarom zijn we vanuit wetenschappelijk perspectief wasberen en eekhoorns aan het vergelijken."
“Het is niet de taak van wetenschappers om ingezette LLM's voortdurend te controleren. Het is aan de makers van modellen om toegang te geven tot de onderliggende modellen, in ieder geval voor auditdoeleinden," zei ze.
Luccioni benadrukte dat AI-modelontwikkelaars ruwe resultaten moeten leveren van standaardbenchmarks zoals SuperGLUE en WikiText en biasbenchmarks zoals BOLD en HONEST.
De strijd tegen AI-gebaseerde vooroordelen en vooroordelen zal waarschijnlijk constant zijn en voortdurende aandacht en onderzoek vereisen om modeloutputs onder controle te houden terwijl AI en de maatschappij samen evolueren.
Hoewel regelgeving vormen van monitoring en rapportage zal verplichten, zijn er weinig harde en snelle oplossingen voor het probleem van algoritmische vooringenomenheid en dit is niet het laatste wat we erover zullen horen.



