

Vi hører mye om AI-sikkerhet, men betyr det at det er mye omtalt i forskningen?
En ny studie fra Georgetown University's Emerging Technology Observatory tyder på at forskning på AI-sikkerhet, til tross for støyen, bare utgjør en liten minoritet av bransjens forskningsfokus.
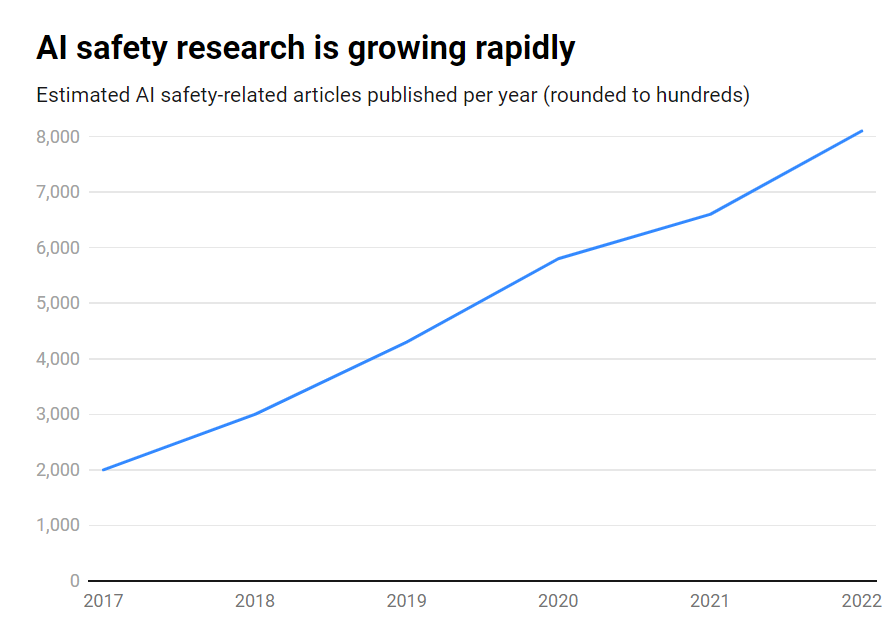
Forskerne analyserte over 260 millioner vitenskapelige publikasjoner og fant ut at bare 2% av AI-relaterte artikler som ble publisert mellom 2017 og 2022, tok direkte opp temaer knyttet til AI-sikkerhet, etikk, robusthet eller styring.
Selv om antallet publikasjoner om AI-sikkerhet økte med imponerende 315% i løpet av denne perioden, fra rundt 1800 til over 7000 per år, er dette fortsatt et perifert tema.
Her er de viktigste funnene:
- Kun 2% av AI-forskningen fra 2017-2022 fokuserte på AI-sikkerhet
- AI-sikkerhetsforskningen vokste med 315% i denne perioden, men er mindre enn den samlede AI-forskningen
- USA leder an i forskningen på KI-sikkerhet, mens Kina henger etter
- Viktige utfordringer er robusthet, rettferdighet, åpenhet og opprettholdelse av menneskelig kontroll
Mange ledende KI-forskere og etikere har advart mot eksistensielle risikoer dersom kunstig generell intelligens (AGI) utvikles uten tilstrekkelige sikkerhetstiltak og forholdsregler.
Se for deg et AGI-system som er i stand til å forbedre seg selv rekursivt og raskt overgå menneskelig intelligens, samtidig som det forfølger mål som ikke er i tråd med våre verdier. Det er et scenario som noen hevder kan komme ut av vår kontroll.
Det er imidlertid ikke enveistrafikk. Faktisk mener et stort antall AI-forskere at AI-sikkerhet er overhypet.
Noen mener til og med at hypen er produsert for å hjelpe Big Tech med å håndheve reguleringer og eliminere grasrot- og konkurrenter med åpen kildekode.
Men selv dagens smale AI-systemer, som er opplært på tidligere data, kan ha skjevheter, produsere skadelig innhold, krenke personvernet og bli brukt i ondsinnet øyemed.
Så selv om AI-sikkerhet må se inn i fremtiden, må den også håndtere risikoer her og nå, noe som uten tvil er utilstrekkelig ettersom forfalskninger, skjevheter og andre problemer fortsetter å være store.
Effektiv forskning på KI-sikkerhet må ta for seg både utfordringer på kort sikt og spekulative risikoer på lengre sikt.
USA leder an innen forskning på KI-sikkerhet
Når vi går nærmere inn på dataene, ser vi at USA er klart ledende innen forskning på KI-sikkerhet, med 40% av relaterte publikasjoner sammenlignet med 12% fra Kina.
Kinas sikkerhetsproduksjon ligger imidlertid langt bak den generelle AI-forskningen - mens 5% av den amerikanske AI-forskningen berørte sikkerhet, gjorde bare 1% av Kinas det.
Man kan spekulere i om det er vanskelig å undersøke kinesisk forskning. I tillegg har Kina vært proaktiv om regulering - uten tvil mer enn i USA - så disse dataene gir kanskje ikke landets AI-industri en rettferdig vurdering.
På institusjonsnivå er det Carnegie Mellon University, Google, MIT og Stanford som leder an.
Men globalt sett produserte ingen organisasjon mer enn 2% av det totale antallet sikkerhetsrelaterte publikasjoner, noe som understreker behovet for en større og mer samordnet innsats.
Ubalanse i sikkerheten
Så hva kan gjøres for å rette opp denne ubalansen?
Det kommer an på om man mener at AI-sikkerhet er en presserende risiko på linje med atomkrig, pandemier osv. Det finnes ikke noe entydig svar på dette spørsmålet, noe som gjør AI-sikkerhet til et svært spekulativt tema med lite gjensidig enighet mellom forskere.
Sikkerhetsforskning og etikk er også et område som grenser opp mot maskinlæring, og som krever andre typer kompetanse, akademisk bakgrunn osv.
For å tette sikkerhetsgapet vil det også være nødvendig å ta stilling til spørsmål om åpenhet og hemmelighold i utviklingen av kunstig intelligens.
De største teknologiselskapene gjennomfører omfattende interne sikkerhetsundersøkelser som aldri har blitt publisert. Etter hvert som kommersialiseringen av kunstig intelligens skyter fart, blir selskapene stadig mer forsiktige med sine AI-gjennombrudd.
OpenAI var for eksempel et kraftsenter for forskning i sine tidlige dager.
Selskapet pleide å foreta grundige, uavhengige revisjoner av produktene sine, merkeforstyrrelser og risikoer - som for eksempel kjønnsdiskriminerende skjevheter i CLIP-prosjektet.
Anthropic er fortsatt aktivt engasjert i forskning på offentlig AI-sikkerhet, og publiserer ofte studier om skjevhet og jailbreaking.
DeepMind dokumenterte også muligheten for at AI-modeller kan etablere "fremvoksende mål" og aktivt motsi instruksjonene sine eller bli motstandere av skaperne sine.
Men generelt sett har sikkerheten blitt nedprioritert til fordel for fremskritt, ettersom Silicon Valley lever etter mottoet "move fast and break stuff".
Georgetown-studien understreker at universiteter, myndigheter, teknologiselskaper og forskningsfinansiører må investere mer innsats og penger i AI-sikkerhet.
Noen har også etterlyst en internasjonalt organ for AI-sikkerhetDet internasjonale atomenergibyrået (IAEA), som ble opprettet etter en rekke atomhendelser som gjorde et omfattende internasjonalt samarbeid obligatorisk.
Vil AI trenge sin egen katastrofe for å få til et slikt samarbeid mellom stat og næringsliv? La oss ikke håpe det.


