

En studie fra University of Oxford har utviklet en metode for å teste når språkmodeller er "usikre" på hva de produserer og risikerer å hallusinere.
AI-"hallusinasjoner" refererer til et fenomen der store språkmodeller (LLM-er) genererer flytende og plausible svar som ikke er sannferdige eller konsistente.
Hallusinasjoner er vanskelige - om ikke umulige - å skille fra AI-modeller. AI-utviklere som OpenAI, Google og Anthropic har alle innrømmet at hallusinasjoner sannsynligvis vil forbli et biprodukt av å samhandle med AI.
Som Dr. Sebastian Farquhar, en av forfatterne av studien, sa forklarer i et blogginnlegg"LLM-er er svært dyktige til å si det samme på mange forskjellige måter, noe som kan gjøre det vanskelig å se når de er sikre på et svar, og når de bokstavelig talt bare finner på noe."
Cambridge Dictionary har til og med lagt til en AI-relatert definisjon av ordet i 2023 og kåret det til "Årets ord".
Dette universitetet i Oxford studie, publisert i Nature, søker å finne svar på hvordan vi kan oppdage når det er størst sannsynlighet for at slike hallusinasjoner oppstår.
Den introduserer et begrep som kalles "semantisk entropi", som måler usikkerheten i en LLMs resultater på meningsnivå i stedet for bare de spesifikke ordene eller frasene som brukes.
Ved å beregne den semantiske entropien til en LLM-modells svar kan forskerne estimere modellens tillit til utdataene og identifisere tilfeller der det er sannsynlig at den hallusinerer.
Semantisk entropi i LLM-er forklart
Semantisk entropi, som definert i studien, måler usikkerheten eller inkonsistensen i betydningen av LLM-enes svar. Den hjelper til med å oppdage når en LLM kan hallusinere eller generere upålitelig informasjon.
Semantisk entropi måler hvor "forvirret" et LLM-resultat er.
LLM vil sannsynligvis gi pålitelig informasjon hvis betydningen av resultatene er nært beslektet og konsistent. Men hvis meningene er spredte og inkonsekvente, er det et rødt flagg som tyder på at LLM-en kan hallusinere eller generere unøyaktig informasjon.
Slik fungerer det:
- Forskerne har aktivt bedt LLM om å generere flere mulige svar på det samme spørsmålet. Dette gjøres ved å mate LLM-en med spørsmålet flere ganger, hver gang med et annet tilfeldig frø eller en liten variasjon i inndataene.
- Semantisk entropi undersøker svarene og grupperer dem med samme underliggende mening, selv om de bruker forskjellige ord eller formuleringer.
- Hvis LLM-en er trygg på svaret, bør svarene ha lignende betydninger, noe som resulterer i en lav semantisk entropisk score. Dette tyder på at LLM-en forstår informasjonen på en tydelig og konsekvent måte.
- Hvis LLM-en derimot er usikker eller forvirret, vil svarene ha flere ulike betydninger, og noen av dem kan være inkonsistente eller ikke ha noe med spørsmålet å gjøre. Dette resulterer i en høy semantisk entropisk score, noe som indikerer at LLM-en kan hallusinere eller generere upålitelig informasjon.
For å evaluere effektiviteten brukte forskerne semantisk entropi på et variert sett med spørsmålssvaroppgaver. Dette involverte benchmarks som trivia-spørsmål, leseforståelse, ordoppgaver og biografier.
Semantisk entropi var gjennomgående bedre enn eksisterende metoder når det gjaldt å oppdage når det var sannsynlig at en LLM ville generere et feilaktig eller inkonsistent svar.
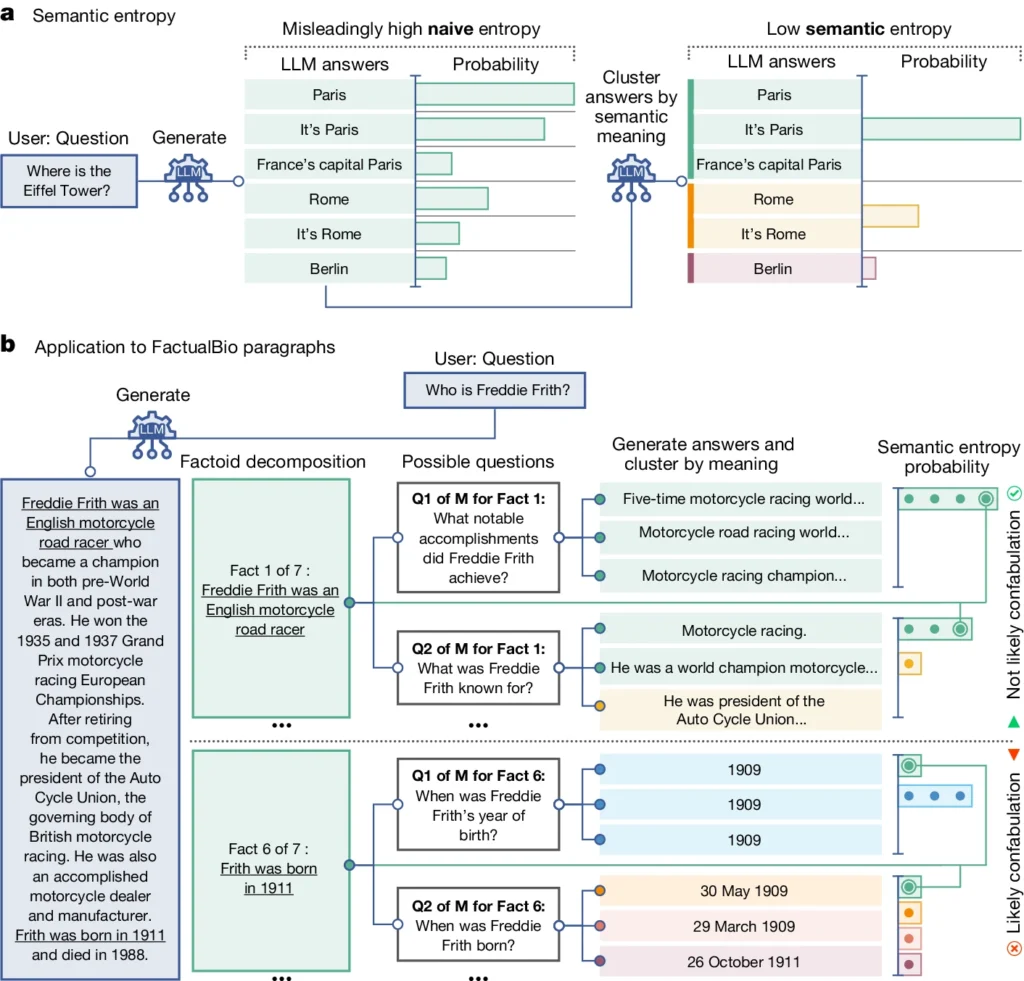
I diagrammet ovenfor kan du se hvordan noen spørsmål presser LLM til å generere et konfabulert (unøyaktig, hallusinatorisk) svar. For eksempel produserer den en fødselsdag og -måned for spørsmålene nederst i diagrammet når informasjonen som kreves for å svare på dem, ikke ble oppgitt i den opprinnelige informasjonen.
Konsekvenser av å oppdage hallusinasjoner
Dette arbeidet kan bidra til å forklare hallusinasjoner og gjøre LLM-er mer pålitelige og troverdige.
Ved å gjøre det mulig å oppdage når en LLM er usikker eller utsatt for hallusinasjoner, baner semantisk entropi vei for bruk av disse AI-verktøyene på områder der det står mye på spill, og der faktanøyaktighet er avgjørende, for eksempel innen helse, juss og finans.
Feilaktige resultater kan ha potensielt katastrofale konsekvenser når de påvirker situasjoner der det står mye på spill, som vist av noen mislykket forutseende politiarbeid og helsesystemer.
Det er imidlertid også viktig å huske at hallusinasjoner bare er én type feil som LLM-er kan gjøre.
Som Dr. Farquhar forklarer: "Hvis en LLM gjør konsekvente feil, vil ikke denne nye metoden fange det opp. De farligste feilene med AI kommer når et system gjør noe galt, men er selvsikkert og systematisk. Her gjenstår det fortsatt mye arbeid."
Oxford-teamets semantiske entropimetode representerer likevel et stort skritt fremover i vår evne til å forstå og redusere begrensningene ved AI-språkmodeller.
Ved å finne objektive metoder for å oppdage dem kommer vi nærmere en fremtid der vi kan utnytte potensialet i kunstig intelligens og samtidig sikre at den forblir et pålitelig og troverdig verktøy i menneskehetens tjeneste.



