

Stanford University offentliggjorde sin AI Index Report 2024, der det påpekes at AIs raske utvikling gjør sammenligninger med mennesker stadig mindre relevante.
Den årsrapport gir et omfattende innblikk i trendene og utviklingen innen kunstig intelligens. Rapporten sier at AI-modeller forbedres så raskt nå at referansene vi bruker for å måle dem, i økende grad blir irrelevante.
Mange bransjereferanser sammenligner AI-modeller med hvor gode mennesker er til å utføre oppgaver. Massive Multitask Language Understanding (MMLU) er et godt eksempel på dette.
Den bruker flervalgsspørsmål for å evaluere LLM-er i 57 fag, inkludert matematikk, historie, juss og etikk. MMLU har vært den viktigste AI-referansen siden 2019.
Den menneskelige baseline-poengsummen på MMLU er 89,8%, og i 2019 fikk den gjennomsnittlige AI-modellen litt over 30%. Bare fem år senere ble Gemini Ultra den første modellen som slo den menneskelige baseline med en poengsum på 90,04%.
Rapporten konstaterer at dagens "AI-systemer rutinemessig overgår menneskelig ytelse på standard benchmarks". Trendene i grafen nedenfor tyder på at MMLU og andre benchmarks må byttes ut.
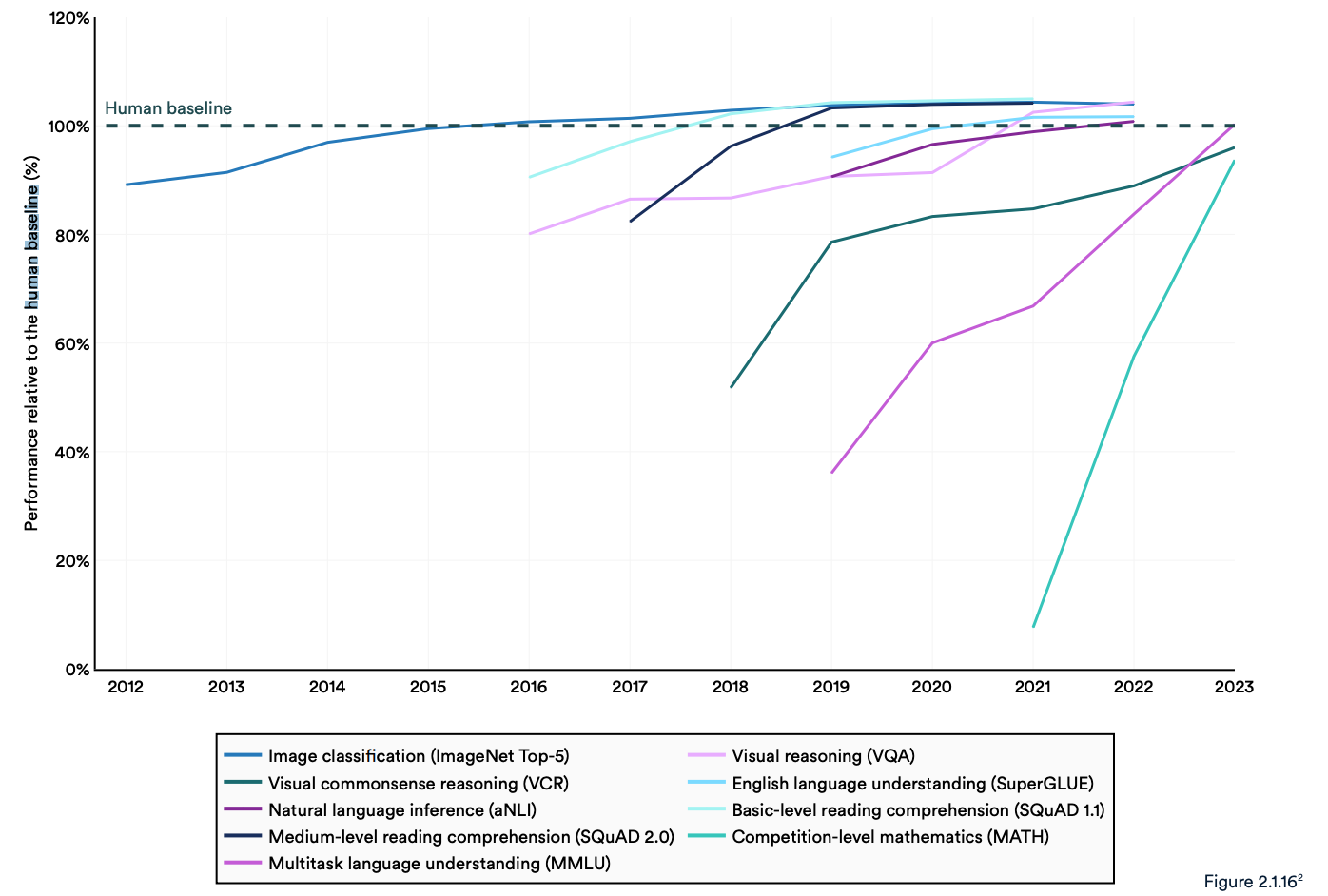
AI-modeller har nådd ytelsesmetning på etablerte benchmarks som ImageNet, SQuAD og SuperGLUE, og forskerne utvikler derfor mer utfordrende tester.
Et eksempel er Graduate-Level Google-Proof Q&A Benchmark (GPQA), som gjør det mulig å måle AI-modeller mot virkelig smarte mennesker, i stedet for mot gjennomsnittlig menneskelig intelligens.
GPQA-testen består av 400 vanskelige flervalgsspørsmål på høyere nivå. Eksperter som har eller er i ferd med å ta doktorgrad, svarer riktig på spørsmålene i 65% av tilfellene.
I GPQA-rapporten står det at "høyt kvalifiserte validatorer som ikke er eksperter, bare oppnår 34% nøyaktighet når de blir stilt spørsmål utenfor sitt eget felt, til tross for at de i gjennomsnitt bruker over 30 minutter med ubegrenset tilgang til nettet".
I forrige måned kunngjorde Anthropic at Claude 3 fikk rett under 60% med 5 skudd CoT-melding. Vi trenger en større referanse.
Claude 3 får ~60% nøyaktighet på GPQA. Det er vanskelig for meg å undervurdere hvor vanskelige disse spørsmålene er - bokstavelige doktorgrader (i andre domener enn spørsmålene) med tilgang til internett får 34%.
Doktorgrader *i samme domene* (også med internettilgang!) får 65% - 75% nøyaktighet. https://t.co/ARAiCNXgU9 pic.twitter.com/PH8J13zIef
- david rein (@idavidrein) 4. mars 2024
Menneskelige evalueringer og sikkerhet
Rapporten peker på at kunstig intelligens fortsatt står overfor betydelige problemer: "Den kan ikke håndtere fakta på en pålitelig måte, utføre komplekse resonnementer eller forklare konklusjonene sine."
Disse begrensningene bidrar til en annen egenskap ved AI-systemet som ifølge rapporten er dårlig målt; AI-sikkerhet. Vi har ikke effektive referanser som gjør at vi kan si: "Denne modellen er tryggere enn den andre."
Det skyldes delvis at det er vanskelig å måle, og delvis at "AI-utviklere mangler åpenhet, spesielt når det gjelder offentliggjøring av opplæringsdata og metoder".
Rapporten bemerket at en interessant trend i bransjen er å bruke menneskelige evalueringer av AI-ytelse i stedet for referansetester.
Det er vanskelig å rangere en modells bildestetikk eller prosa med en test. Som et resultat sier rapporten at "benchmarking sakte har begynt å skifte mot å innlemme menneskelige evalueringer som Chatbot Arena Leaderboard i stedet for datastyrte rangeringer som ImageNet eller SQuAD."
Etter hvert som AI-modeller ser den menneskelige baseline forsvinne i bakspeilet, kan følelser etter hvert avgjøre hvilken modell vi velger å bruke.
Trendene tyder på at AI-modeller etter hvert vil bli smartere enn oss og vanskeligere å måle. Snart vil vi kanskje si: "Jeg vet ikke hvorfor, men jeg liker bare denne bedre."



