

Et forskerteam fra New York University har gjort fremskritt innen nevral taledekoding, noe som bringer oss nærmere en fremtid der personer som har mistet evnen til å snakke, kan få stemmen sin tilbake.
Den studie, publisert i Naturens maskinintelligenspresenterer et nytt rammeverk for dyp læring som nøyaktig oversetter hjernesignaler til forståelig tale.
Personer med hjerneskader som følge av hjerneslag, degenerative tilstander eller fysiske traumer kan bruke disse systemene til å kommunisere ved å avkode tankene eller den tiltenkte talen sin fra nervesignaler.
NYU teamets system involverer en dyp læringsmodell som kartlegger elektrokortikografi-signaler (EKoG) fra hjernen til talekjennetegn, som tonehøyde, lydstyrke og annet spektralt innhold.
Det andre trinnet involverer en nevral talesynthesizer som konverterer de ekstraherte talefunksjonene til et hørbart spektrogram, som deretter kan omdannes til en talebølgeform.
Denne bølgeformen kan til slutt konverteres til syntetisk tale med naturlig lyd.
Ny artikkel publisert i dag i @NatMachIntellhvor vi viser robust nevrale til tale-avkoding hos 48 pasienter. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBCBVzp
- Adeen Flinker 🇮🇱🇺🇦🎗️ (@adeenflinker) 9. april 2024
Slik fungerer studien
Denne studien går ut på å trene opp en AI-modell som kan drive en talesynteseenhet som gjør det mulig for personer med nedsatt taleevne å snakke ved hjelp av elektriske impulser fra hjernen.
Her kan du lese mer om hvordan det fungerer:
1. Innsamling av hjernedata
Det første trinnet innebærer å samle inn rådataene som trengs for å trene opp taledekodingsmodellen. Forskerne jobbet med 48 deltakere som gjennomgikk en nevrokirurgisk operasjon for epilepsi.
I løpet av studien ble deltakerne bedt om å lese hundrevis av setninger høyt, mens hjerneaktiviteten deres ble registrert ved hjelp av EKG-registrering.
Disse rutenettene plasseres direkte på hjernens overflate og fanger opp elektriske signaler fra de hjerneområdene som er involvert i taleproduksjon.
2. Kartlegging av hjernesignaler til tale
Ved hjelp av taledata utviklet forskerne en sofistikert AI-modell som tilordner de innspilte hjernesignalene til spesifikke talekjennetegn, som tonehøyde, lydstyrke og de unike frekvensene som ulike talelyder består av.
3. Syntetisering av tale fra funksjoner
Det tredje trinnet fokuserer på å konvertere talefunksjonene som er hentet ut fra hjernesignalene, tilbake til hørbar tale.
Forskerne brukte en spesiell talesynthesizer som tar de ekstraherte funksjonene og genererer et spektrogram - en visuell fremstilling av talelydene.
4. Evaluering av resultatene
Forskerne sammenlignet talen som ble generert av modellen, med den opprinnelige talen som ble talt av deltakerne.
De brukte objektive parametere for å måle likheten mellom de to, og fant ut at den genererte talen stemte godt overens med originalens innhold og rytme.
5. Testing på nye ord
For å sikre at modellen kan håndtere nye ord den ikke har sett før, ble visse ord med vilje utelatt under modellens treningsfase, og deretter ble modellens ytelse på disse usette ordene testet.
Modellens evne til å avkode selv nye ord viser at den har potensial til å generalisere og håndtere ulike talemønstre.
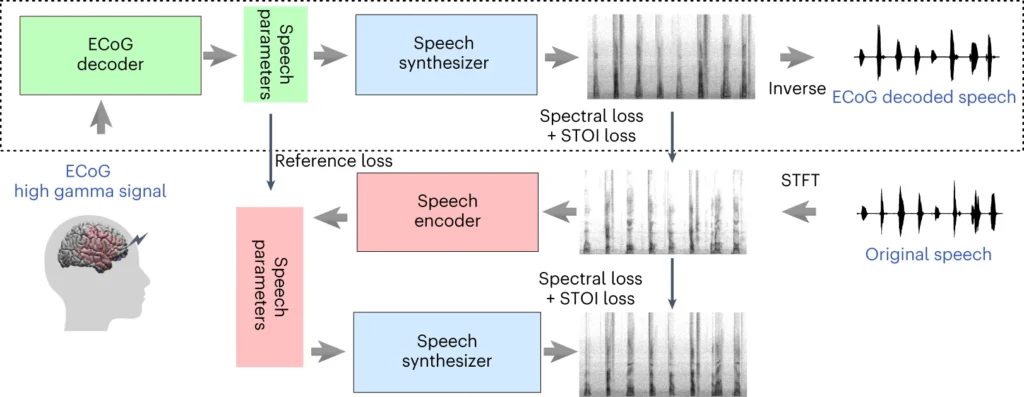
Den øverste delen av diagrammet ovenfor beskriver en prosess for å konvertere hjernesignaler til tale. Først gjør en dekoder disse signalene om til taleparametere over tid. Deretter lager en synthesizer lydbilder (spektrogrammer) av disse parameterne. Et annet verktøy endrer disse bildene tilbake til lydbølger.
Den nederste delen omhandler et system som hjelper til med å trene opp hjernens signaldekoder ved å etterligne tale. Det tar et lydbilde, gjør det om til taleparametere, og bruker deretter disse til å lage et nytt lydbilde. Denne delen av systemet lærer av faktiske talelyder for å bli bedre.
Etter opplæring er det bare den øverste prosessen som trengs for å gjøre hjernesignaler om til tale.
En av de viktigste fordelene med NYUs system er at det gir taledekoding av høy kvalitet uten behov for elektroder med ultrahøy tetthet, noe som er upraktisk for langvarig bruk.
I bunn og grunn tilbyr den en lettere, bærbar løsning.
En annen prestasjon er vellykket avkoding av tale fra både venstre og høyre hjernehalvdel, noe som er viktig for pasienter med hjerneskade på den ene siden av hjernen.
Konverterer tanker til tale ved hjelp av kunstig intelligens
NYU-studien bygger på tidligere forskning innen nevral taledekoding og hjerne-datamaskin-grensesnitt (BCI).
I 2023 gjorde et team ved University of California, San Francisco, det mulig for en lammet slagpasient å generere setninger med en hastighet på 78 ord i minuttet ved hjelp av en BCI som syntetiserte både vokalisering og ansiktsuttrykk fra hjernesignaler.
Andre nyere studier har utforsket bruken av kunstig intelligens til å tolke ulike aspekter ved menneskelig tankevirksomhet ut fra hjerneaktivitet. Forskere har demonstrert evnen til å generere bilder, tekst og til og med musikk fra MR- og EEG-data (elektroencefalogram) fra hjernen.
For eksempel kan en studie fra Universitetet i Helsinki brukte EEG-signaler til å veilede et generativt kontradiktorisk nettverk (GAN) i å produsere ansiktsbilder som samsvarte med deltakernes tanker.
Meta AI har også utviklet en teknikk for delvis å avkode hva noen lyttet til ved hjelp av hjernebølger som ble samlet inn ikke-invasivt.
Muligheter og utfordringer
NYUs metode bruker mer allment tilgjengelige og klinisk anvendelige elektroder enn tidligere metoder, noe som gjør den mer tilgjengelig.
Selv om dette er spennende, er det store hindringer som må overvinnes hvis vi skal se utbredt bruk.
For det første er det komplisert og tidkrevende å samle inn hjernedata av høy kvalitet. Individuelle forskjeller i hjerneaktivitet gjør det vanskelig å generalisere, noe som betyr at en modell som er trent opp for én gruppe deltakere, kanskje ikke fungerer like godt for en annen.
NYU-studien representerer likevel et skritt i denne retningen ved å demonstrere høypresis taleavkoding ved hjelp av lettere elektrodeoppsett.
I tiden fremover har NYU-teamet som mål å videreutvikle modellene sine for taledekoding i sanntid, slik at vi kommer nærmere det endelige målet om å muliggjøre naturlige, flytende samtaler for personer med talevansker.
De har også til hensikt å tilpasse systemet til implanterbare trådløse enheter som kan brukes i hverdagen.



