

Tidligere denne måneden kunngjorde Google stolt at deres kraftigste Gemini-modell slo GPT-4 i Massive Multitask Language Understanding MMLU-referansetestene. Microsofts nye prompting-teknikk gjør at GPT-4 gjenvinner førsteplassen, om enn med en brøkdel av en prosent.
Foruten dramaet rundt markedsføringsvideoen, er Googles Gemini en stor sak for selskapet, og MMLU-referanseresultatene er imponerende. Men Microsoft, OpenAIs største investor, ventet ikke lenge med å kaste skygge over Googles innsats.
Overskriften er at Microsoft fikk GPT-4 til å slå Gemini Ultras MMLU-resultater. I virkeligheten slo den Geminis poengsum på 90,04% med bare 0,06%.
Bakgrunnen for hva som gjorde dette mulig, er mer spennende enn den inkrementelle opphentingen vi ser på disse topplistene. Microsofts nye prompting-teknikker kan øke ytelsen til eldre AI-modeller.
Husker du hvordan Googles uutgitte Gemini Ultra nettopp slo ut GPT-4 for å bli den beste AI-en?
Microsoft har nettopp demonstrert at GPT-4 faktisk slår Gemini på benchmarks, med riktig veiledning.
Det er mye å hente selv med eldre modeller. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12. desember 2023
Medprompt
Når folk snakker om å "styre" en modell, mener de bare at du med forsiktig veiledning kan få modellen til å gi deg et resultat som er bedre tilpasset det du ønsker.
Microsoft utviklet en kombinasjon av prompting-teknikker som viste seg å være veldig gode til dette. Medprompt startet som et prosjekt for å få GPT-4 til å gi bedre svar på medisinske utfordringer som MultiMedQA-testserien.
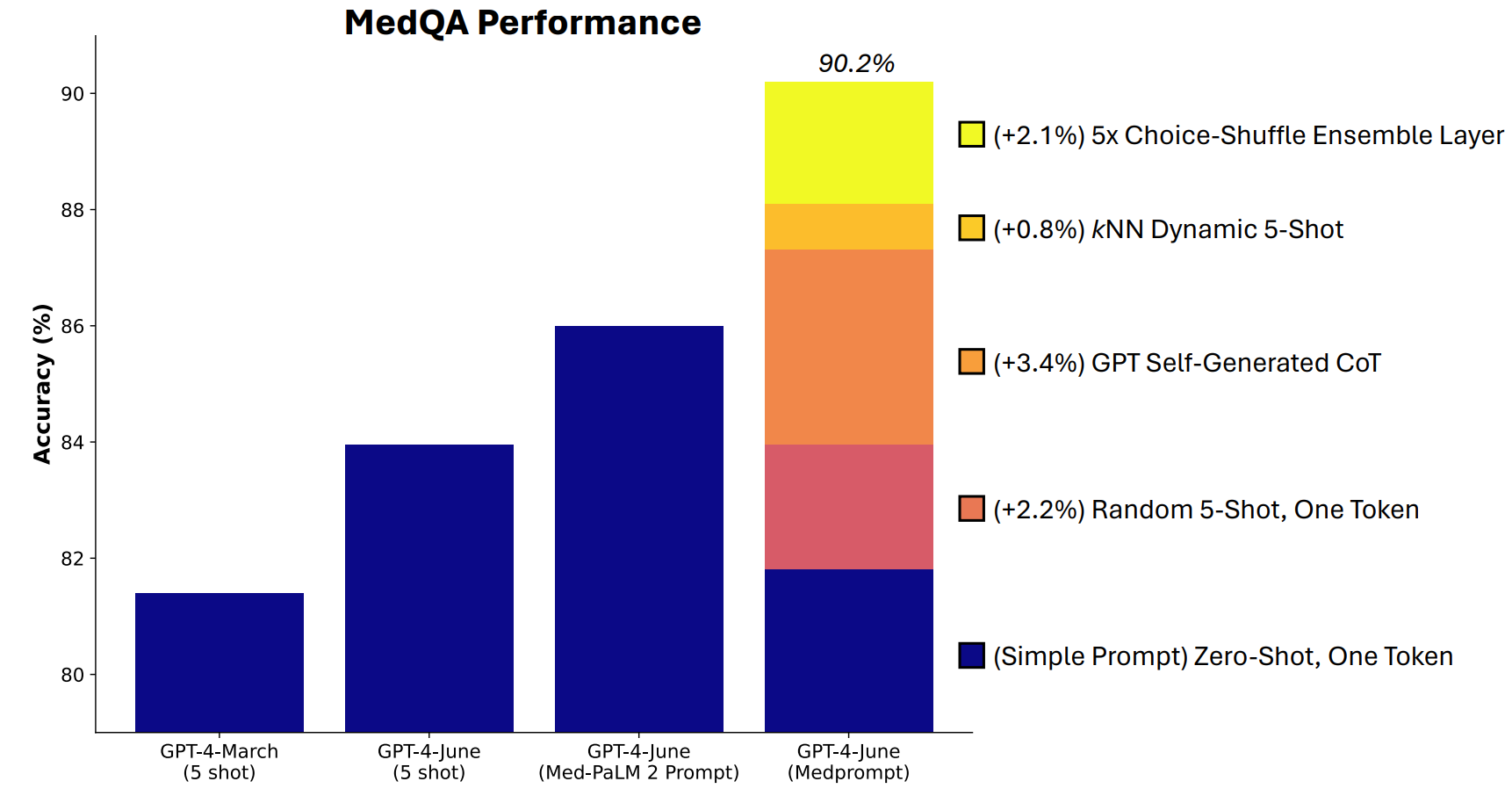
Microsoft-forskerne tenkte at hvis Medprompt fungerte godt i spesialiserte medisinske tester, kunne det også forbedre GPT-4s generalistytelse. Og dermed vant Microsoft og OpenAIs GPT-4 over Gemini Ultra.
Hvordan fungerer Medprompt?
Medprompt er en kombinasjon av smarte promptteknikker i ett og samme program. Den baserer seg på tre hovedteknikker.
Dynamisk læring med få skudd (DFSL)
"Few-shot learning" betyr at GPT-4 får noen få eksempler før den blir bedt om å løse et lignende problem. Når du ser en referanse som "5-shot", betyr det at modellen ble gitt fem eksempler. "Null-shot" betyr at den måtte svare uten noen eksempler.
I Medprompt-artikkelen forklares det at "for enkelhetens og effektivitetens skyld er de få eksemplene som brukes i prompting for en bestemt oppgave, vanligvis faste; de er uforandret på tvers av testeksemplene".
Resultatet er at eksemplene som presenteres for modellene, ofte bare er lite relevante eller representative.
Hvis treningssettet er stort nok, kan du få modellen til å se gjennom alle eksemplene og velge dem som semantisk sett ligner på problemet den skal løse. Resultatet er at de få eksemplene som læres opp, er mer spesifikt tilpasset et bestemt problem.
Selvgenererte tankekjeder (CoT)
Tankekjede (CoT) er en flott måte å styre en LLM på. Når du ber den om å "tenke seg om" eller "løse det steg for steg", blir resultatene mye bedre.
Du kan bli mye mer spesifikk i måten du styrer tankekjeden modellen skal følge, men det innebærer manuell prompt engineering.
Forskerne fant ut at de "ganske enkelt kunne be GPT-4 om å generere tankekjeder for treningseksemplene". Tilnærmingen deres forteller GPT-4: "Her er et spørsmål, svaralternativene og det riktige svaret. Hvilken CoT bør vi inkludere i en ledetekst som fører til dette svaret?
Choice Shuffle Ensembling
De fleste av MMLUs referansetester er flervalgsspørsmål. Når en AI-modell besvarer disse spørsmålene, kan den bli utsatt for posisjonsskjevhet. Med andre ord kan den favorisere alternativ B over tid, selv om det ikke alltid er det riktige svaret.
Choice Shuffle Ensembling blander svaralternativenes plasseringer og lar GPT-4 svare på spørsmålet på nytt. Dette gjøres flere ganger, og deretter velges det svaret som er mest konsekvent valgt, som det endelige svaret.
Kombinasjonen av disse tre promptteknikkene er det som ga Microsoft muligheten til å kaste litt skygge over Geminis resultater. Det blir interessant å se hvilke resultater Gemini Ultra ville oppnådd med en lignende tilnærming.
Medprompt er spennende fordi det viser at eldre modeller kan prestere enda bedre enn vi trodde hvis vi spør dem på smarte måter. Den ekstra prosessorkraften som trengs for disse ekstra trinnene, gjør det imidlertid ikke til en levedyktig tilnærming i de fleste tilfeller.



