

Digital kolonialisme refererer til teknologigiganters og mektige aktørers dominans over det digitale landskapet, der de former flyten av informasjon, kunnskap og kultur slik at den tjener deres interesser.
Denne dominansen handler ikke bare om å kontrollere den digitale infrastrukturen, men også om å påvirke de fortellingene og kunnskapsstrukturene som definerer vår digitale tidsalder.
Digital kolonialisme, og nå også AI-kolonialisme, er allment anerkjente begreper, og institusjoner som MIT har forsket på og skrevet om dem i stor utstrekning.
Toppforskere fra Anthropic, Google, DeepMind og andre teknologiselskaper har åpent diskutert AIs begrensede muligheter til å betjene mennesker med ulik bakgrunn, særlig med henvisning til skjevhet i maskinlæringssystemer.
Maskinlæringssystemer fningsdataene de er opplært på - data som kankan ses på som et produkt av vår digitale tidsånd - en samling av rådende fortellinger, bilder og ideer som dominerer nettverdenen.
Men hvem er det som får lov til å forme disse informasjonskreftene? Hvem sine stemmer blir forsterket, og hvem blir dempet?
Når kunstig intelligens lærer av opplæringsdata, arver den spesifikke verdensbilder som ikke nødvendigvis stemmer overens med eller representerer globale kulturer og erfaringer. I tillegg er kontrollene som styrer resultatet av generative AI-verktøy, formet av underliggende sosiokulturelle vektorer.
Dette har ført til at utviklere som Anthropic søke demokratiske metoder for å forme AI-atferd ved hjelp av offentlige synspunkter.
Jack Clark, Anthropics politiske sjef, beskrev en nylig eksperiment fra selskapet hans: "Vi prøver å finne en måte å utvikle en grunnlov som er utviklet av en hel haug med tredjeparter, i stedet for av folk som tilfeldigvis jobber på et laboratorium i San Francisco."
Dagens generative AI-treningsparadigmer risikerer å skape et digitalt ekkokammer der de samme ideene, verdiene og perspektivene kontinuerlig forsterkes, noe som ytterligere forsterker dominansen til de som allerede er overrepresentert i dataene.
Etter hvert som kunstig intelligens integreres i komplekse beslutningsprosesser, fra sosial velferd og rekruttering til økonomiske beslutninger og medisinske diagnoserfører skjev representasjon til skjevheter og urettferdighet i den virkelige verden.
Datasettene er geografisk og kulturelt lokalisert
En nylig studie utført av Data Provenance Initiative undersøkte 1800 populære datasett beregnet på naturlig språkbehandling (NLP), en disiplin innen kunstig intelligens som fokuserer på språk og tekst.
NLP er den dominerende maskinlæringsmetodikken bak store språkmodeller (LLM-er), inkludert ChatGPT og Metas Llama-modeller.
Studien avdekker en vestsentrisk skjevhet i språkrepresentasjonen på tvers av datasettene, der engelsk og vesteuropeiske språk definerer tekstdataene.
Språk fra asiatiske, afrikanske og søramerikanske land er markant underrepresentert.
Derfor kan ikke LLM-språk representere de kulturelle og språklige nyansene i disse regionene i like stor grad som vestlige språk.
Selv når språk fra det globale sør er representert, stammer språkets kilde og dialekt først og fremst fra nordamerikanske eller europeiske opphavsmenn og nettkilder.

A forrige Antropisk eksperiment fant at det å bytte språk i modeller som ChatGPT fortsatt ga vestsentriske synspunkter og stereotypier i samtalene.
Forskerne konkluderte: "Hvis en språkmodell i uforholdsmessig stor grad representerer visse meninger, risikerer den å få potensielt uønskede effekter, som å fremme hegemoniske verdensbilder og homogenisere folks perspektiver og oppfatninger."
Data Provenance-studien dissekerte også det geografiske landskapet for kuratering av datasett. Akademiske organisasjoner fremstår som de viktigste pådriverne, og bidrar til 69% av datasettene, etterfulgt av industrilaboratorier (21%) og forskningsinstitusjoner (17%).
De største bidragsyterne er AI2 (12,3%), University of Washington (8,9%) og Facebook AI Research (8,4%).
A egen 2020-studie fremhever at halvparten av datasettene som ble brukt til AI-evaluering i rundt 26 000 forskningsartikler, stammet fra så få som 12 toppuniversiteter og teknologiselskaper.
Igjen viste det seg at geografiske områder som Afrika, Sør- og Mellom-Amerika og Sentral-Asia var sørgelig underrepresentert, som vist nedenfor.
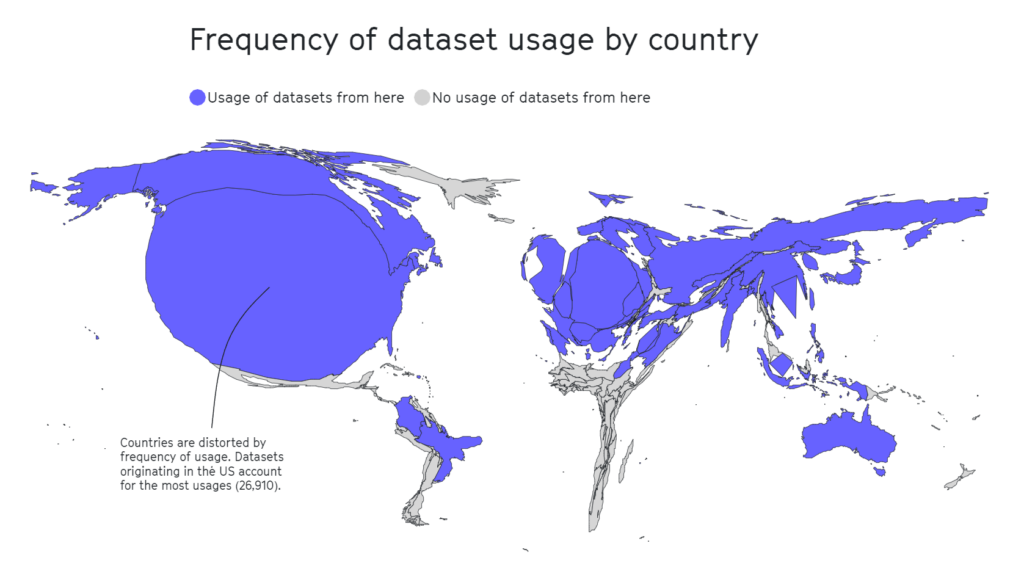
I annen forskning har innflytelsesrike datasett som MITs Tiny Images eller Labeled Faces in the Wild primært inneholdt bilder av hvite, vestlige menn, med rundt 77,5% menn og 83,5% personer med hvit hudfarge i tilfellet Labeled Faces in the Wild.
Når det gjelder Tiny Images, er en 2020-analyse av The Register fant at mange Tiny Images inneholdt obskøne, rasistiske og sexistiske merkelapper.
Antonio Torralba fra MIT sa at de ikke var klar over merkelappene, og datasettet ble slettet. Torralba sa: "Det er klart at vi burde ha screenet dem manuelt."
Engelsk dominerer økosystemet for kunstig intelligens
Pascale Fung, informatiker og direktør for Center for AI Research ved Hong Kong University of Science and Technology, diskuterte problemene knyttet til hegemonisk AI.
Fung viser til over 15 forskningsartikler som har undersøkt flerspråkskompetansen til LLM-er, og som gjennomgående finner at de har mangler, særlig når de oversetter engelsk til andre språk. Språk med ikke-latinsk skrift, som koreansk, avslører for eksempel LLM-enes begrensninger.
I tillegg til dårlig flerspråklig støtte, andre studier tyder på at de fleste mål og tiltak for skjevheter er utviklet med tanke på engelskspråklige modeller.
Det er få benchmarks for ikke-engelskspråklige skjevheter, noe som fører til et betydelig gap i vår evne til å vurdere og korrigere skjevheter i flerspråklige språkmodeller.
Det finnes tegn til forbedring, for eksempel Googles innsats med språkmodellen PaLM 2 og Meta's Massivt flerspråklig tale (MMS) som kan identifisere mer enn 4000 talte språk, 40 ganger mer enn andre metoder. MMS er imidlertid fortsatt på forsøksstadiet.
Forskere skaper ulike, flerspråklige datasett, men den overveldende mengden engelske tekstdata, som ofte er gratis og lett tilgjengelige, gjør at utviklere de facto velger engelsk.
Utover data: strukturelle problemer i AI-arbeid
MITs omfattende gjennomgang av AI-kolonialisme rettet oppmerksomheten mot et relativt skjult aspekt ved utviklingen av kunstig intelligens - utnyttelse av arbeidskraft.
AI har utløst en voldsom økning i etterspørselen etter tjenester for datamerking. Selskaper som Appen og Sama har vokst frem som viktige aktører, og tilbyr tjenester som tagging av tekst, bilder og videoer, sortering av bilder og transkribering av lyd for å mate maskinlæringsmodeller.
Menneskelige dataspesialister merker også innholdstyper manuelt, ofte for å sortere data som inneholder ulovlig, illegalt eller uetisk innhold, for eksempel beskrivelser av seksuelle overgrep, skadelig atferd eller andre ulovlige aktiviteter.
Selv om AI-selskaper automatiserer noen av disse prosessene, er det fortsatt viktig å holde "mennesker i loopen" for å sikre at modellene er nøyaktige og i samsvar med sikkerhetskravene.
Markedsverdien av dette "spøkelsesarbeidet", som antropologen Mary Gray og samfunnsforskeren Siddharth Suri kaller det, er anslått til skyte i været til $13,7 milliarder innen 2030.
Spøkelsesarbeid innebærer ofte utnyttelse av billig arbeidskraft, særlig fra økonomisk sårbare land. Venezuela har for eksempel blitt en viktig kilde til AI-relatert arbeidskraft på grunn av den økonomiske krisen i landet.
Da landet slet med sin verste økonomiske katastrofe i fredstid og en astronomisk inflasjon, vendte en betydelig del av den velutdannede og internetttilkoblede befolkningen seg til crowd-working-plattformer som et middel til å overleve.
Kombinasjonen av en velutdannet arbeidsstyrke og økonomisk desperasjon gjorde Venezuela til et attraktivt marked for datomerkingsselskaper.
Dette er ikke et kontroversielt poeng - når MIT publiserer artikler med titler som "Kunstig intelligens skaper en ny kolonial verdensorden...", med henvisning til slike scenarier, er det tydelig at noen i bransjen ønsker å trekke forhenget for denne underfundige arbeidspraksisen.
Som MIT rapporterer, har den voksende AI-industrien vært et tveegget sverd for mange venezuelanere. Samtidig som den har gitt en økonomisk livline midt i desperasjonen, har den også utsatt folk for utnyttelse.
Julian Posada, doktorgradsstipendiat ved University of Toronto, fremhever den "enorme maktubalansen" i disse arbeidsordningene. Plattformene dikterer reglene, slik at arbeidstakerne har lite å si og får begrenset økonomisk kompensasjon til tross for utfordringer på jobben, som eksponering for forstyrrende innhold.
Denne dynamikken minner uhyggelig mye om tidligere tiders kolonipraksis, der imperier utnyttet arbeidskraften i sårbare land, hentet ut profitt og forlot dem når mulighetene ble færre, ofte fordi "bedre verdi" var tilgjengelig andre steder.
Lignende situasjoner har blitt observert i Nairobi, Kenya, der en gruppe tidligere innholdsmoderatorer som jobbet på ChatGPT innlevert en begjæring med den kenyanske regjeringen.
De hevdet at de ble "utnyttet" under oppholdet hos Sama, et USA-basert selskap som leverer dataannotasjonstjenester på kontrakt med OpenAI. Klagerne hevdet at de ble eksponert for urovekkende innhold uten tilstrekkelig psykososial støtte, noe som førte til alvorlige psykiske problemer, deriblant PTSD, depresjon og angst.

Dokumenter anmeldt av TIME viste at OpenAI hadde inngått kontrakter med Sama til en verdi av rundt $200 000. Disse kontraktene omfattet merking av beskrivelser av seksuelle overgrep, hatefulle ytringer og vold.
De psykiske konsekvensene for arbeiderne var dyptgripende. Mophat Okinyi, en tidligere moderator, fortalte om de psykiske følgene, og beskrev hvordan eksponeringen for grafisk innhold førte til paranoia, isolasjon og betydelige personlige tap.
Lønnen for et så slitsomt arbeid var sjokkerende lav - en talsperson for Sama opplyste at arbeiderne tjente mellom $1,46 og $3,74 i timen.
Motstand mot digital kolonialisme
Hvis AI-industrien har blitt en ny grense for digital kolonialisme, er motstanden allerede i ferd med å bli mer sammenhengende.
Aktivister, ofte med støtte fra KI-forskere, tar til orde for ansvarliggjøring, politiske endringer og utvikling av teknologi som prioriterer lokalsamfunnenes behov og rettigheter.
Nanjala Nyabolas Kiswahili Digital Rights Project er et nyskapende eksempel på hvordan lokale grasrotprosjekter kan etablere den infrastrukturen som kreves for å beskytte lokalsamfunn mot digitalt hegemoni.
Prosjektet tar hensyn til det vestlige regelverkets hegemoni når det gjelder å definere en gruppes digitale rettigheter, ettersom ikke alle er beskyttet av de lovene om immaterielle rettigheter, opphavsrett og personvern som mange av oss tar for gitt. Dette gjør at en betydelig andel av verdens befolkning kan bli utnyttet av teknologiselskaper.
Nyabola og teamet hennes innså at diskusjoner om digitale rettigheter blir svekket hvis folk ikke kan kommunisere på sitt eget morsmål, og oversatte derfor sentrale begreper om digitale rettigheter og teknologi til kiswahili, et språk som først og fremst snakkes i Tanzania, Kenya og Mosambik.
Nyabola beskrevet av prosjektet"I løpet av prosessen [med Huduma Namba-initiativet] hadde vi ikke språket og verktøyene som skulle til for å forklare ikke-spesialister eller ikke-engelskspråklige lokalsamfunn i Kenya hva initiativet innebar."
I et lignende grasrotprosjekt hadde Te Hiku Media, en ideell radiostasjon som hovedsakelig sender på maori-språket, en enorm database med opptak som strakte seg over flere tiår, og mange av dem var et ekko av forfedrenes stemmer, som ikke lenger ble uttalt.
Vanlige talegjenkjenningsmodeller, som ligner på LLM-modeller, har en tendens til å underoppfylle kravene når de blir bedt om å bruke ulike språk eller engelske dialekter.
Den Te Hiku Media samarbeidet med forskere og åpen kildekode-teknologi for å trene opp en talegjenkjenningsmodell skreddersydd for maorispråket. Māori-aktivisten Te Mihinga Komene bidro med rundt 4000 fraser til de utallige andre som deltok i prosjektet.
Den resulterende modell og data er beskyttet i henhold til Kaitiakitanga Lisens - Kaitiakitanga er et maori-ord uten en spesifikk engelsk definisjon, men det kan sammenlignes med "verge" eller "vokter".
Keoni Mahelona, en av grunnleggerne av Te Hiku Media, sa det slik: "Data er koloniseringens siste grense."
Disse prosjektene har inspirert andre urfolk og innfødte samfunn som er under press fra digital kolonialisme og andre former for sosial omveltning, for eksempel mohawkfolket i Nord-Amerika og indianerne på Hawaii.
Etter hvert som AI med åpen kildekode blir billigere og lettere tilgjengelig, bør det bli enklere å iterere og finjustere modeller ved hjelp av unike, lokaliserte datasett, noe som vil gi bedre tilgang til teknologien på tvers av kulturer.
Selv om AI-bransjen fortsatt er ung, er tiden nå inne for å få disse utfordringene frem i lyset, slik at vi kan utvikle løsninger i fellesskap.
Løsningene kan være både på makronivå, i form av regelverk, retningslinjer og opplæringsmetoder for maskinlæring, og på mikronivå, i form av lokale prosjekter og grasrotprosjekter.
Sammen kan forskere, aktivister og lokalsamfunn finne metoder for å sikre at AI kommer alle til gode.


