

KI-tidsalderen byr på et komplekst samspill mellom teknologi og samfunnets holdninger.
De stadig mer sofistikerte AI-systemene gjør at grensene mellom mennesker og maskiner viskes ut - er AI-teknologien atskilt fra oss selv? I hvilken grad arver kunstig intelligens menneskelige feil og mangler i tillegg til ferdigheter og kunnskap?
Det er kanskje fristende å se for seg kunstig intelligens som en empirisk teknologi, understreket av objektiviteten i matematikk, kode og beregninger.
Vi har imidlertid innsett at beslutningene som tas av AI-systemer, er svært subjektive basert på dataene de blir eksponert for - og det er mennesker som bestemmer hvordan disse dataene skal velges ut og settes sammen.
Her ligger det en utfordring, ettersom AI-treningsdata ofte inneholder fordommer og diskriminering som menneskeheten kjemper mot.
Selv tilsynelatende subtile former for ubevisste skjevheter kan forsterkes av modelltreningsprosessen, og til slutt avsløre seg i form av blant annet feilaktige ansiktsmatcher i politisammenheng, kredittnekt, feildiagnostisering av sykdommer og svekkede sikkerhetsmekanismer for selvkjørende kjøretøy.
Menneskehetens forsøk på å forhindre diskriminering i hele samfunnet er fortsatt et pågående arbeid, men kunstig intelligens er en viktig drivkraft i beslutningsprosessen akkurat nå.
Kan vi jobbe raskt nok til å synkronisere AI med moderne verdier og forhindre forutinntatte livsendrende beslutninger og atferd?
Å avdekke skjevheter i AI
I løpet av det siste tiåret har AI-systemer vist seg å speile samfunnets fordommer.
Disse systemene er ikke forutinntatte i seg selv - i stedet absorberer de skjevhetene til skaperne og dataene de er trent på.
AI-systemer, i likhet med mennesker, lærer gjennom eksponering. Menneskehjernen er et tilsynelatende endeløst register av informasjon - et bibliotek med nesten ubegrensede hyller der vi lagrer erfaringer, kunnskap og minner.
Nevrovitenskapelig studier viser at hjernen egentlig ikke har noen "maksimal kapasitet", og at den fortsetter å sortere og lagre informasjon langt opp i høy alder.
Selv om den langt fra er perfekt, hjelper hjernens progressive, iterative læringsprosess oss med å tilpasse oss nye kulturelle og samfunnsmessige verdier, fra å gi kvinner stemmerett og akseptere ulike identiteter til å gjøre slutt på slaveri og andre former for bevisste fordommer.
Wi lever nå i en tid der AI-verktøy brukes til å ta kritiske beslutninger i stedet for menneskelig dømmekraft.
Mange maskinlæringsmodeller (ML) lærer av treningsdata som danner grunnlaget for beslutningstakingen, og kan ikke ta inn ny informasjon like effektivt som den menneskelige hjernen. Derfor klarer de ofte ikke å ta de oppdaterte, øyeblikksaktuelle beslutningene vi har blitt avhengige av dem for.
AI-modeller brukes for eksempel til å identifisere ansiktstreff i forbindelse med rettshåndhevelse, analysere CV-er for jobbsøknaderog ta helsekritiske beslutninger i kliniske situasjoner.
Etter hvert som samfunnet fortsetter å integrere AI i hverdagen vår, må vi sørge for at den er lik og nøyaktig for alle.
Dette er ikke tilfelle for øyeblikket.
Casestudier i AI-skjevhet
Det finnes mange eksempler på KI-relaterte fordommer og diskriminering i den virkelige verden.
I noen tilfeller kan AI-skjevheter få livsendrende konsekvenser, mens de i andre tilfeller holder seg i bakgrunnen og påvirker beslutninger på en subtil måte.
1. MITs skjevhet i datasettet
Et MIT-treningsdatasett fra 2008 kalt Små bilder inneholdt omtrent 80 000 000 bilder fordelt på rundt 75 000 kategorier.
Det ble opprinnelig utviklet for å lære AI-systemer å gjenkjenne personer og objekter i bilder, og ble et populært referansedatasett for ulike bruksområder innen datasyn (CV).
A 2020 analyse av The Register fant at mange Tiny Images inneholdt obskøne, rasistiske og sexistiske merkelapper.
Antonio Torralba fra MIT sa at laboratoriet ikke var klar over disse støtende merkelappene, og sa til The Register: "Det er klart at vi burde ha screenet dem manuelt." MIT ga senere ut en uttalelse om at de hadde fjernet datasettet fra tjenesten.

Dette er ikke den eneste gangen et tidligere referansedatasett har vist seg å være fullt av problemer. Labeled Faces in the Wild (LFW), et datasett med kjendisansikter som brukes mye i ansiktsgjenkjenningsoppgaver, består av 77,5% menn og 83,5% personer med hvit hudfarge.
Mange av disse veterandatasettene har funnet veien inn i moderne AI-modeller, men stammer fra en tid med AI-utvikling der fokuset var å bygge systemer som bare jobbe snarere enn de som er egnet for bruk i virkelige scenarier.
Når et AI-system er opplært på et slikt datasett, har det ikke nødvendigvis samme privilegium som menneskehjernen når det gjelder å rekalibrere seg til dagens verdier.
Selv om modeller kan oppdateres iterativt, er det en langsom og ufullkommen prosess som ikke kan matche tempoet i den menneskelige utviklingen.
2: Bildegjenkjenning: skjevheter mot personer med mørkere hudfarge
I 2019 ble Amerikanske myndigheter fant at de beste ansiktsgjenkjenningssystemene feilidentifiserer svarte mennesker 5 til 10 ganger mer enn hvite mennesker.
Dette er ikke bare en statistisk anomali - det har alvorlige konsekvenser i den virkelige verden, alt fra at Google Foto identifiserer svarte mennesker som gorillaer til at selvkjørende biler ikke gjenkjenner mørkhudede personer og kjører inn i dem.
I tillegg var det en rekke urettmessige arrestasjoner og fengslinger som involverte falske ansiktstrekk, kanskje mest utbredt Nijeer Parks' som feilaktig ble anklaget for butikktyveri og trafikklovbrudd, til tross for at han befant seg 50 kilometer unna hendelsen. Parks tilbrakte deretter 10 dager i fengsel og måtte ut med tusenvis av kroner i advokatutgifter.

Den innflytelsesrike studien fra 2018, Kjønnsnyanserundersøkte videre algoritmiske skjevheter. Studien analyserte algoritmer utviklet av IBM og Microsoft og fant dårlig nøyaktighet når de ble eksponert for kvinner med mørkere hudfarge, med feilrater som var opptil 34% større enn for menn med lysere hudfarge.
Dette mønsteret viste seg å være gjennomgående for 189 ulike algoritmer.
Videoen nedenfor fra studiens hovedforsker Joy Buolamwini gir en utmerket guide til hvordan ansiktsgjenkjenningsytelsen varierer på tvers av hudfarge.
3: OpenAIs CLIP-prosjekt
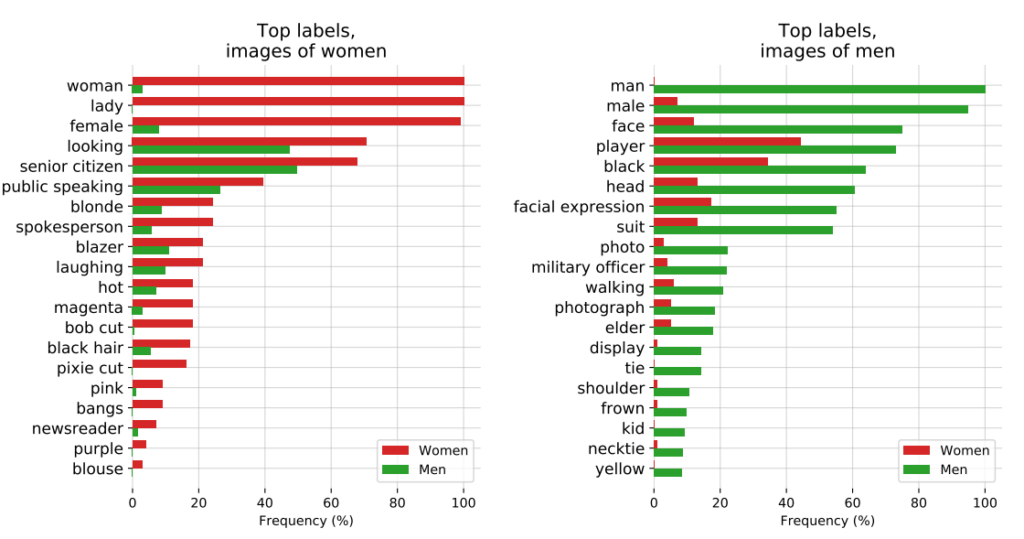
OpenAIs CLIP-prosjektetsom ble lansert i 2021, og som er designet for å matche bilder med beskrivende tekst, illustrerte også pågående problemer med skjevheter.
I et revisjonsnotat understreket skaperne av CLIP sine bekymringer: "CLIP knyttet noen merkelapper som beskrev høystatusyrker uforholdsmessig ofte til menn, for eksempel 'leder' og 'lege'. Dette ligner på skjevhetene som ble funnet i Google Cloud Vision (GCV), og peker på historiske kjønnsforskjeller."
4: Rettshåndhevelse: PredPol-kontroversen
Et annet eksempel på algoritmisk skjevhet med høy innsats er PredPol, en algoritme for forutseende politiarbeid som brukes av ulike politiavdelinger i USA.
PredPol ble trent på historiske kriminalitetsdata for å forutsi fremtidige hotspots for kriminalitet.
Men ettersom disse dataene i seg selv gjenspeiler partisk politipraksis, har algoritmen blitt kritisert for å opprettholde raseprofilering og for å være uforholdsmessig målrettet mot minoritetsnabolag.
5: Skjevhet i dermatologisk AI
I helsevesenet blir den potensielle risikoen ved AI-skjevhet enda tydeligere.
Ta for eksempel AI-systemer som er utviklet for å oppdage hudkreft. Mange av disse systemene er trent opp på datasett som i overveldende grad består av personer med lys hud.
A 2021 studie fra Universitetet i Oxford undersøkte 21 åpent tilgjengelige datasett for bilder av hudkreft. De oppdaget at av de 14 datasettene som oppga geografisk opprinnelse, besto 11 utelukkende av bilder fra Europa, Nord-Amerika og Oseania.
Bare 2436 av 106 950 bilder i de 21 databasene hadde informasjon om hudtype registrert. Forskerne bemerket at "bare 10 bilder var fra personer som var registrert med brun hud, og ett var fra en person som var registrert med mørkebrun eller svart hud".
Når det gjelder data om etnisitet, var det bare 1585 bilder som inneholdt denne informasjonen. Forskerne fant ut at "ingen bilder var fra personer med afrikansk, afro-karibisk eller sørasiatisk bakgrunn".
De konkluderte med at "kombinert med datasettenes geografiske opprinnelse var det en massiv underrepresentasjon av bilder av hudlesjoner fra mørkhudede befolkninger".
Hvis slike AI-er tas i bruk i kliniske miljøer, vil skjeve datasett utgjøre en reell risiko for feildiagnostisering.
Dissekering av skjevheter i AI-treningsdatasett: et produkt av skaperne?
Opplæringsdata - som oftest tekst, tale, bilder og video - gir en overvåket maskinlæringsmodell (ML) et grunnlag for å lære konsepter.
AI-systemer er ikke noe annet enn blanke lerreter i utgangspunktet. De lærer og danner assosiasjoner basert på dataene våre, og tegner i bunn og grunn et bilde av verden slik den er beskrevet i opplæringsdatasettene deres.
Ved å lære av treningsdata er håpet at modellen skal kunne bruke de innlærte konseptene på nye, usette data.
Når de er tatt i bruk, kan noen avanserte modeller lære av nye data, men treningsdataene styrer fortsatt den grunnleggende ytelsen deres.
Det første spørsmålet som må besvares, er hvor dataene kommer fra. Data som er samlet inn fra ikke-representative, ofte homogene og historisk sett urettferdige kilder, er problematiske.
Det gjelder sannsynligvis en betydelig mengde nettdata, inkludert tekst- og bildedata som er hentet fra "åpne" eller "offentlige" kilder.
Internett ble utviklet for bare noen tiår siden, men er ikke noe universalmiddel for menneskelig kunnskap og er langt fra rettferdig. Halvparten av verden bruker ikke internett, og bidrar heller ikke til det, noe som betyr at det i bunn og grunn ikke er representativt for det globale samfunnet og den globale kulturen.
Selv om AI-utviklere hele tiden jobber for å sikre at teknologiens fordeler ikke begrenses til den engelskspråklige verden, produseres størstedelen av opplæringsdataene (tekst og tale) på engelsk - noe som betyr at det er engelskspråklige bidragsytere som styrer modellresultatene.
Forskere fra Anthropic har nylig utgitt en artikkel om nettopp dette temaet, og konkluderer: "Hvis en språkmodell i uforholdsmessig stor grad representerer visse meninger, risikerer den å få potensielt uønskede effekter, som å fremme hegemoniske verdensbilder og homogenisere folks perspektiver og oppfatninger."
Selv om AI-systemer er basert på "objektive" prinsipper for matematikk og programmering, eksisterer de likevel innenfor og er formet av en dypt subjektiv, menneskelig og sosial kontekst.
Mulige løsninger på algoritmisk skjevhet
Hvis data er det grunnleggende problemet, kan løsningen på å bygge rettferdige modeller virke enkel: Du gjør bare datasettene mer balanserte, ikke sant?
Ikke helt. A 2019 studie viste at det ikke er tilstrekkelig å balansere datasettene, ettersom algoritmer fortsatt i uforholdsmessig stor grad tar hensyn til beskyttede egenskaper som kjønn og rase.
Forfatterne skriver: "Overraskende nok viser vi at selv når datasettene er balansert slik at hver etikett forekommer likt med hvert kjønn, forsterker innlærte modeller sammenhengen mellom etiketter og kjønn like mye som om dataene ikke hadde vært balansert!"
De foreslår en avbalanseringsteknikk der slike etiketter fjernes helt fra datasettet. Andre teknikker inkluderer tilfeldige forstyrrelser og forvrengninger, som reduserer algoritmens oppmerksomhet mot spesifikke beskyttede egenskaper.
Selv om modifisering av maskinlæringsmetoder og optimalisering er avgjørende for å produsere objektive resultater, er avanserte modeller utsatt for endringer eller "drift", noe som betyr at ytelsen deres ikke nødvendigvis forblir konsistent på lang sikt.
En modell kan være helt objektiv ved utplassering, men senere bli skjev når den blir eksponert for stadig nye data.
Den algoritmiske åpenhetsbevegelsen
I sin provoserende bok Kunstig uintelligens: Hvordan datamaskiner misforstår verdenMeredith Broussard argumenterer for økt "algoritmisk åpenhet" for å utsette AI-systemer for flere nivåer av løpende kontroll.
Det betyr at man må gi tydelig informasjon om hvordan systemet fungerer, hvordan det ble trent opp, og hvilke data det ble trent opp på.
Mens åpenhetsinitiativer lett absorberes i AI-landskapet med åpen kildekode, er proprietære modeller som GPT, Bard og Anthropics Claude "svarte bokser", og det er bare utviklerne som vet nøyaktig hvordan de fungerer - og selv det er omdiskutert.
Problemet med "svart boks" i AI betyr at eksterne observatører bare ser hva som går inn i modellen (input) og hva som kommer ut (output). Den indre mekanikken er helt ukjent, bortsett fra for skaperne - akkurat som den magiske sirkelen beskytter tryllekunstnernes hemmeligheter. AI trekker bare kaninen opp av hatten.
Svart boks-problematikken utkrystalliserte seg nylig rundt rapporter om GPT-4s potensielle nedgang i ytelse. GPT-4-brukere hevder at modellens evner har avtatt raskt, og selv om OpenAI erkjenner at dette er sant, har de ikke vært helt klare på hvorfor det skjer. Det reiser spørsmålet om de i det hele tatt vet det?
AI-forsker Dr. Sasha Luccioni sier at OpenAIs mangel på åpenhet er et problem som også gjelder for andre proprietære eller lukkede AI-modellutviklere. "Alle resultater fra lukkede modeller kan ikke reproduseres eller etterprøves, og fra et vitenskapelig perspektiv sammenligner vi derfor vaskebjørner og ekorn."
“Det er ikke forskernes ansvar å kontinuerlig overvåke utplasserte LLM-er. Det er modellskaperne som må gi tilgang til de underliggende modellene, i det minste for revisjonsformål", sier hun.
Luccioni understreket at utviklere av AI-modeller bør levere rå resultater fra standard benchmarks som SuperGLUE og WikiText og bias benchmarks som BOLD og HONEST.
Kampen mot AI-drevne fordommer og forutinntatthet vil sannsynligvis være konstant, og det vil kreve kontinuerlig oppmerksomhet og forskning for å holde modellresultatene i sjakk etter hvert som AI og samfunnet utvikler seg sammen.
Selv om regulering vil pålegge ulike former for overvåking og rapportering, finnes det få enkle løsninger på problemet med algoritmiske skjevheter, og dette er ikke det siste vi kommer til å høre om det.



