

En ny studie viser at trening av AI-bildegeneratorer med AI-genererte bilder til slutt fører til en betydelig reduksjon i kvaliteten på utdataene.
Baraniuk og teamet hans demonstrerte hvordan denne problematiske AI-treningssløyfen påvirker generativ AI, inkludert StyleGAN og diffusjonsmodeller. Disse er blant modellene som brukes i AI-bildegeneratorer som Stable Diffusion, DALL-E og MidJourney.
I deres eksperimentteamet trente AI-ene på enten AI-genererte eller ekte bilder. 70 000 ekte menneskeansikter hentet fra Flickr.
Når hver AI ble trent på sine egne AI-genererte bilder, begynte StyleGAN-bildegeneratorens utdata å vise forvrengte og bølgete visuelle mønstre, mens diffusjonsbildegeneratorens utdata ble mer uskarpe.
I begge tilfeller førte opplæring av AI på AI-genererte bilder til et tap av kvalitet.
En av de studie Richard Baraniuk fra Rice University i Texas, advarer: "Det kommer til å bli et skråplan å bruke syntetiske data, enten bevisst eller ubevisst."
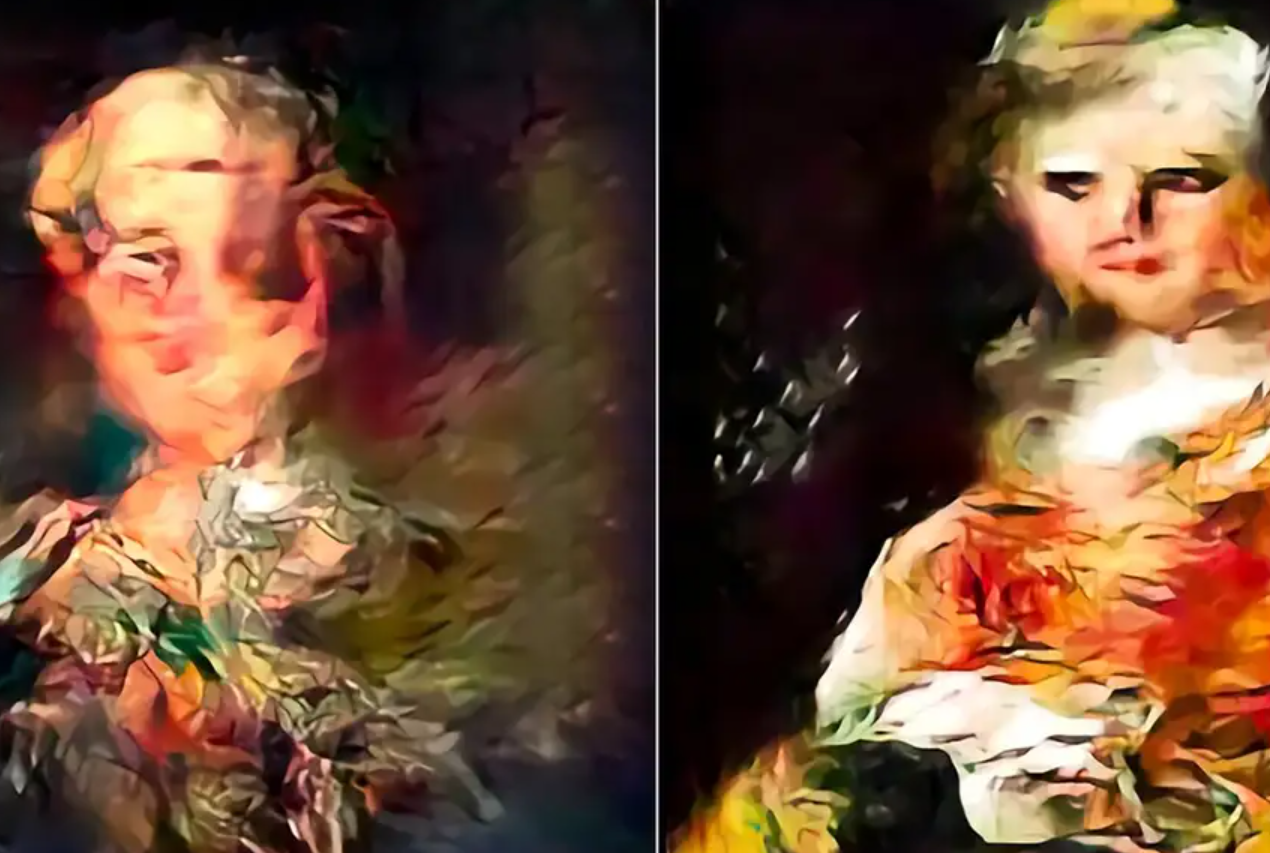
Selv om nedgangen i bildekvalitet ble redusert ved å velge AI-genererte bilder av høyere kvalitet til opplæring, førte dette til et tap av bildediversitet.
Forskerne prøvde også å inkorporere et fast sett med ekte bilder i treningssett som primært inneholdt AI-genererte bilder, en metode som noen ganger brukes for å supplere små treningssett.
Dette forsinket imidlertid bare nedgangen i bildekvaliteten - det virker uunngåelig at jo mer AI-genererte data som kommer inn i opplæringsdatasettene, desto dårligere blir resultatet. Det er bare et spørsmål om når.
Vi oppnådde rimelige resultater da hver AI ble trent opp på en blanding av AI-genererte bilder og et sett med autentiske bilder som stadig ble endret. Dette bidro til å opprettholde kvaliteten og mangfoldet i bildene.
Det er utfordrende å balansere kvantitet og kvalitet - syntetiske bilder er potensielt ubegrensede sammenlignet med ekte bilder, men det koster å bruke dem.
Den kunstige intelligensen går tom for data
Kunstig intelligens er datahungrige, men autentiske data av høy kvalitet er en begrenset ressurs.
Funnene i denne undersøkelsen gjenspeiler lignende studier for tekstgenerering, der AI-resultater har en tendens til å lide når modeller trenes på AI-genererte tekster.
Forskerne fremhever at mindre organisasjoner med begrenset mulighet til å samle inn autentiske data står overfor de største utfordringene når det gjelder å filtrere AI-genererte bilder fra datasettene sine.
I tillegg forsterkes problemet av at internett oversvømmes av AI-generert innhold, noe som gjør det utrolig vanskelig å avgjøre hvilken type data modellene er opplært på.
Sina Alemohammad fra Rice University mener at det kan være nyttig å utvikle vannmerker for å identifisere AI-genererte bilder, men advarer samtidig om at skjulte vannmerker kan forringe kvaliteten på AI-genererte bilder.
Alemohammad konkluderer: "Du er forbannet hvis du gjør det, og forbannet hvis du ikke gjør det. Men det er definitivt bedre å vannmerke bildet enn å la være."
De langsiktige konsekvensene av at AI bruker det den produserer, er omdiskutert, men akkurat nå må AI-utviklere finne løsninger for å sikre kvaliteten på modellene sine.



