

El colonialismo digital se refiere al dominio de los gigantes tecnológicos y las entidades poderosas sobre el paisaje digital, moldeando el flujo de información, conocimiento y cultura para servir a sus intereses.
Este dominio no consiste sólo en controlar la infraestructura digital, sino también en influir en las narrativas y estructuras de conocimiento que definen nuestra era digital.
El colonialismo digital, y ahora el colonialismo de la IA, son términos ampliamente reconocidos, e instituciones como El MIT ha investigado y escrito sobre ampliamente.
Los principales investigadores de Anthropic, Google, DeepMind y otras empresas tecnológicas han debatido abiertamente sobre el alcance limitado de la IA a la hora de atender a personas de orígenes diversos, sobre todo en referencia a sesgo en sistemas de aprendizaje automático.
Sistemas de aprendizaje automático fnamentalmente reflejan los datos con los que se han entrenado, datos que ce podría considerar un producto de nuestro zeitgeist digital, una colección de narrativas, imágenes e ideas predominantes que dominan el mundo en línea.
Pero, ¿quién da forma a estas fuerzas informativas? ¿Qué voces se amplifican y cuáles se atenúan?
Cuando la IA aprende a partir de datos de entrenamiento, hereda visiones del mundo específicas que no necesariamente resuenan con las culturas y experiencias globales o las representan. Además, los vectores socioculturales subyacentes determinan los controles que rigen los resultados de las herramientas de IA generativa.
Esto ha llevado a desarrolladores como Anthropic a buscar métodos democráticos de moldear el comportamiento de la IA mediante opiniones públicas.
Como Jack Clark, responsable político de Anthropic, describió un experimento reciente de su empresa: "Intentamos encontrar una forma de desarrollar una constitución que sea desarrollada por un montón de terceros, en lugar de por personas que casualmente trabajan en un laboratorio de San Francisco".
Los actuales paradigmas de formación de IA generativa corren el riesgo de crear una cámara de eco digital en la que se refuercen continuamente las mismas ideas, valores y perspectivas, afianzando aún más el dominio de los que ya están sobrerrepresentados en los datos.
A medida que la IA se integra en la toma de decisiones complejas, de bienestar social y contratación a decisiones financieras y diagnósticos médicosLa representación desigual conduce a prejuicios e injusticias en el mundo real.
Los conjuntos de datos están situados geográfica y culturalmente
Un reciente estudio de la Data Provenance Initiative sondeó 1.800 conjuntos de datos populares destinados al procesamiento del lenguaje natural (PLN), una disciplina de la IA que se centra en el lenguaje y el texto.
NLP es la metodología de aprendizaje automático dominante detrás de los grandes modelos lingüísticos (LLM), incluidos los modelos ChatGPT y Llama de Meta.
El estudio revela un sesgo occidentalista en la representación lingüística de los conjuntos de datos, con el inglés y las lenguas de Europa Occidental definiendo los datos de texto.
Las lenguas de las naciones asiáticas, africanas y sudamericanas están notablemente infrarrepresentadas.
En consecuencia, los LLM no pueden aspirar a representar con precisión los matices lingüístico-culturales de estas regiones en la misma medida que las lenguas occidentales.
Incluso cuando aparecen representadas lenguas del Sur Global, el origen y el dialecto de la lengua proceden principalmente de creadores y fuentes web norteamericanos o europeos.

A anterior Experimento antrópico descubrieron que el cambio de idioma en modelos como ChatGPT seguía dando lugar a puntos de vista occidentales y estereotipos en las conversaciones.
Los investigadores antrópicos concluyeron: "Si un modelo lingüístico representa desproporcionadamente ciertas opiniones, corre el riesgo de imponer efectos potencialmente indeseables, como promover visiones hegemónicas del mundo y homogeneizar las perspectivas y creencias de la gente."
El estudio sobre la procedencia de los datos también diseccionó el panorama geográfico de la conservación de conjuntos de datos. Las organizaciones académicas son las principales impulsoras, con 69% de los conjuntos de datos, seguidas de los laboratorios industriales (21%) y las instituciones de investigación (17%).
Los mayores contribuyentes son AI2 (12,3%), la Universidad de Washington (8,9%) y Facebook AI Research (8,4%).
A estudio separado 2020 destaca que la mitad de los conjuntos de datos utilizados para la evaluación de la IA en aproximadamente 26.000 artículos de investigación proceden de tan solo 12 universidades y empresas tecnológicas de primer nivel.
Una vez más, zonas geográficas como África, América del Sur y Central y Asia Central resultaron estar lamentablemente infrarrepresentadas, como se ve a continuación.
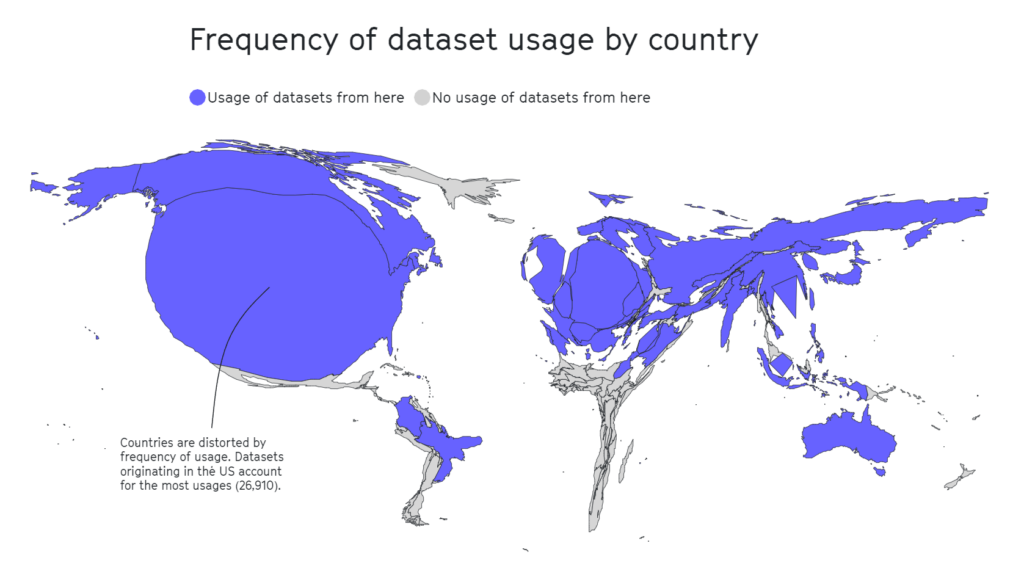
En otras investigaciones, conjuntos de datos influyentes como Tiny Images del MIT o Labeled Faces in the Wild llevaban principalmente imágenes de hombres occidentales blancos, con unos 77,5% varones y 83,5% individuos de piel blanca en el caso de Labeled Faces in the Wild.
En el caso de Tiny Images, un 2020 análisis de The Register descubrió que muchas Tiny Images contenían etiquetas obscenas, racistas y sexistas.
Antonio Torralba, del MIT, dijo que no estaban al tanto de las etiquetas y que el conjunto de datos fue eliminado. Torralba dijo: "Está claro que deberíamos haberlos filtrado manualmente".
El inglés domina el ecosistema de la IA
Pascale Fung, informática y directora del Centro de Investigación sobre IA de la Universidad de Ciencia y Tecnología de Hong Kong, habló de los problemas asociados a la IA hegemónica.
Fung hace referencia a más de 15 trabajos de investigación sobre el dominio multilingüe de los LLM, en los que se constatan sistemáticamente sus carencias, sobre todo a la hora de traducir del inglés a otros idiomas. Por ejemplo, las lenguas con alfabetos no latinos, como el coreano, ponen de manifiesto las limitaciones de los LLM.
Además de un soporte multilingüe deficiente, otros estudios sugieren que la mayoría de los puntos de referencia y medidas de sesgo se han desarrollado teniendo en cuenta los modelos en lengua inglesa.
Los puntos de referencia de sesgo en lengua no inglesa son escasos y distantes entre sí, lo que supone una laguna importante en nuestra capacidad para evaluar y rectificar el sesgo en modelos lingüísticos multilingües.
Hay indicios de mejora, como los esfuerzos de Google con su modelo lingüístico PaLM 2 y Meta's Habla multilingüe masiva (MMS) que puede identificar más de 4.000 lenguas habladas, 40 veces más que otros enfoques. Sin embargo, MMS sigue siendo experimental.
Los investigadores están creando diversos conjuntos de datos multilingües, pero la abrumadora cantidad de datos de texto en inglés, a menudo gratuitos y de fácil acceso, los convierte en la opción de facto para los desarrolladores.
Más allá de los datos: cuestiones estructurales en el trabajo de la IA
Amplia revisión del colonialismo de la IA en el MIT llamó la atención sobre un aspecto relativamente oculto del desarrollo de la IA: las prácticas de explotación laboral.
La IA ha provocado un intenso aumento de la demanda de servicios de etiquetado de datos. Empresas como Appen y Sama han surgido como actores clave, ofreciendo servicios de etiquetado de texto, imágenes y vídeos, clasificación de fotos y transcripción de audio para alimentar modelos de aprendizaje automático.
Los especialistas en datos humanos también etiquetan manualmente los tipos de contenido, a menudo para clasificar los datos que contienen contenidos ilegales, ilícitos o poco éticos, como descripciones de abusos sexuales, comportamientos nocivos u otras actividades ilegales.
Aunque las empresas de IA automatizan algunos de estos procesos, sigue siendo vital mantener a los "humanos en el bucle" para garantizar la precisión de los modelos y el cumplimiento de las normas de seguridad.
Se calcula que el valor de mercado de este "trabajo fantasma", como lo denominan la antropóloga Mary Gray y el científico social Siddharth Suri, ascenderá a 1,5 millones de euros. se dispararán a $13.700 millones en 2030.
El trabajo fantasma suele implicar la explotación de mano de obra barata, sobre todo de países económicamente vulnerables. Venezuela, por ejemplo, se ha convertido en una fuente primaria de mano de obra relacionada con la IA debido a su crisis económica.
Mientras el país se enfrentaba a su peor catástrofe económica en tiempos de paz y a una inflación astronómica, una parte significativa de su población, bien formada y conectada a Internet, recurrió a plataformas de trabajo colectivo como medio de supervivencia.
La confluencia de una mano de obra bien formada y la desesperación económica hicieron de Venezuela un mercado atractivo para las empresas de etiquetado de datos.
No se trata de un punto controvertido: cuando el MIT publica artículos con títulos como "La inteligencia artificial está creando un nuevo orden mundial colonialAl referirse a escenarios como éste, es evidente que algunos en la industria buscan correr la cortina sobre estas prácticas laborales turbias.
Como informa el MIT, para muchos venezolanos, la floreciente industria de la IA ha sido un arma de doble filo. Aunque ha supuesto un salvavidas económico en medio de la desesperación, también ha expuesto a la gente a la explotación.
Julián Posada, doctorando de la Universidad de Toronto, subraya los "enormes desequilibrios de poder" de estos acuerdos laborales. Las plataformas dictan las normas, dejando a los trabajadores con poco poder de decisión y una compensación económica limitada a pesar de las dificultades en el trabajo, como la exposición a contenidos perturbadores.
Esta dinámica recuerda inquietantemente a las prácticas coloniales históricas, en las que los imperios explotaban la mano de obra de los países vulnerables, extraían beneficios y los abandonaban una vez que se agotaban las oportunidades, a menudo porque en otros lugares se ofrecían "mejores precios".
Se han observado situaciones similares en Nairobi, Kenia, donde un grupo de antiguos moderadores de contenidos que trabajaban en ChatGPT presentó una petición con el gobierno keniano.
Alegaron "condiciones de explotación" durante su permanencia en Sama, una empresa estadounidense de servicios de anotación de datos contratada por OpenAI. Los peticionarios afirmaron que estuvieron expuestos a contenidos perturbadores sin un apoyo psicosocial adecuado, lo que les provocó graves problemas de salud mental, como TEPT, depresión y ansiedad.

Documentos reseñado por TIME indicó que OpenAI había firmado contratos con Sama por valor de unos $200.000. Estos contratos implicaban el etiquetado de descripciones de abusos sexuales, incitación al odio y violencia.
El impacto en la salud mental de los trabajadores fue profundo. Mophat Okinyi, antiguo moderador, habló de las consecuencias psicológicas y describió cómo la exposición a contenidos gráficos provocó paranoia, aislamiento e importantes pérdidas personales.
Los salarios por un trabajo tan penoso eran escandalosamente bajos: un portavoz de Sama reveló que los trabajadores ganaban entre $1,46 y $3,74 la hora.
Resistir al colonialismo digital
Si la industria de la IA se ha convertido en una nueva frontera del colonialismo digital, la resistencia ya se está cohesionando.
Los activistas, a menudo respaldados por investigadores en IA, abogan por la rendición de cuentas, los cambios políticos y el desarrollo de tecnologías que den prioridad a las necesidades y los derechos de las comunidades locales.
Nanjala Nyabola Proyecto de derechos digitales en kiswahili ofrece un ejemplo innovador de cómo los proyectos de base a escala local pueden instalar la infraestructura necesaria para proteger a las comunidades de la hegemonía digital.
El proyecto tiene en cuenta la hegemonía de las normativas occidentales a la hora de definir los derechos digitales de un grupo, ya que no todo el mundo está protegido por las leyes de propiedad intelectual, derechos de autor y privacidad que muchos de nosotros damos por sentadas. Esto deja a una parte importante de la población mundial expuesta a la explotación de las empresas tecnológicas.
Conscientes de que los debates en torno a los derechos digitales quedan embotados si la gente no puede comunicar los temas en su lengua materna, Nyabola y su equipo tradujeron los términos clave de los derechos digitales y la tecnología al kiswahili, lengua hablada principalmente en Tanzania, Kenia y Mozambique.
Nyabola descripción del proyectoDurante ese proceso [de la iniciativa Huduma Namba], no disponíamos realmente del lenguaje ni de las herramientas para explicar a las comunidades no especializadas o no anglófonas de Kenia cuáles eran las implicaciones de la iniciativa".
En un proyecto de base similar, Te Hiku Media, una emisora de radio sin ánimo de lucro que emite principalmente en lengua maorí, poseía una vasta base de datos de grabaciones de décadas, muchas de las cuales se hacían eco de las voces de frases ancestrales que ya no se pronunciaban.
Los principales modelos de reconocimiento del habla, similares a los LLM, tienden a no dar la talla cuando se les pregunta en distintos idiomas o dialectos del inglés.
En Te Hiku Media colaboró con investigadores y tecnologías de código abierto para entrenar un modelo de reconocimiento de voz adaptado a la lengua maorí. El activista maorí Te Mihinga Komene contribuyó con unas 4.000 frases a las innumerables personas que participaron en el proyecto.
En modelo resultante y los datos están protegidos por la Licencia Kaitiakitanga - Kaitiakitanga es una palabra maorí sin una definición específica en español, pero es similar a "guardián" o "custodio".
Keoni Mahelona, cofundador de Te Hiku Media, comentó conmovido: "Los datos son la última frontera de la colonización".
Estos proyectos han inspirado a otras comunidades indígenas y nativas sometidas a la presión del colonialismo digital y otras formas de agitación social, como los pueblos mohawk de Norteamérica y los nativos hawaianos.
A medida que la IA de código abierto se abarata y facilita el acceso, la iteración y el perfeccionamiento de los modelos utilizando conjuntos de datos localizados únicos debería ser más sencilla, lo que mejoraría el acceso transcultural a la tecnología.
Aunque la industria de la IA sigue siendo joven, ha llegado el momento de sacar a la luz estos retos para que la gente pueda desarrollar soluciones colectivamente.
Las soluciones pueden ser tanto a nivel macroeconómico, en forma de normativas, políticas y enfoques de formación en aprendizaje automático, como a nivel microeconómico, en forma de proyectos locales y de base.
Juntos, investigadores, activistas y comunidades locales pueden encontrar métodos para garantizar que la IA beneficie a todos.



