

Anthropic haben die Forscher erfolgreich Millionen von Konzepten innerhalb Claude Sonnet, einer ihrer fortgeschrittenen LLMs.
KI-Modelle werden oft als Blackboxen betrachtet, d. h. man kann nicht in sie hineinsehen, um zu verstehen, wie sie genau funktionieren.
Wenn Sie einem LLM eine Eingabe machen, erzeugt es eine Antwort, aber die Gründe für seine Entscheidungen sind nicht klar.
Sie geben etwas ein, und das Ergebnis kommt heraus - und nicht einmal die KI-Entwickler selbst verstehen wirklich, was in dieser "Box" passiert.
Neuronale Netze erstellen ihre eigenen internen Repräsentationen von Informationen, wenn sie während des Datentrainings Eingaben auf Ausgaben abbilden. Die Bausteine dieses Prozesses, die so genannten "Neuronenaktivierungen", werden durch numerische Werte dargestellt.
Jedes Konzept ist auf mehrere Neuronen verteilt, und jedes Neuron trägt zur Darstellung mehrerer Konzepte bei, was es schwierig macht, Konzepte direkt einzelnen Neuronen zuzuordnen.
Dies ist im Großen und Ganzen vergleichbar mit unseren menschlichen Gehirnen. So wie unser Gehirn Sinneseindrücke verarbeitet und Gedanken, Verhaltensweisen und Erinnerungen erzeugt, sind die Milliarden, ja Billionen von Prozessen, die hinter diesen Funktionen stehen, der Wissenschaft noch weitgehend unbekannt.
AnthropicStudie versucht, mit einer Technik namens "Wörterbuchlernen" einen Blick in die Blackbox der KI zu werfen.
Dabei werden komplexe Muster in einem KI-Modell in lineare Bausteine oder "Atome" zerlegt, die für den Menschen intuitiv verständlich sind.
Abbildung von LLMs mit Dictionary Learning
Im Oktober 2023, Anthropic wandte diese Methode auf ein kleines "Spielzeug"-Sprachmodell an und fand kohärente Merkmale, die Konzepten wie Großbuchstaben, DNA-Sequenzen, Nachnamen in Zitaten, mathematischen Substantiven oder Funktionsargumenten in Python-Code entsprechen.
In dieser neuesten Studie wird die Technik so erweitert, dass sie auch für die größeren KI-Sprachmodelle von heute geeignet ist, Anthropic's Claude 3 Sonett.
Im Folgenden wird Schritt für Schritt beschrieben, wie die Studie ablief:
Erkennen von Mustern mit Wörterbuchlernen
Anthropic verwendet Wörterbuchlernen, um Neuronenaktivierungen in verschiedenen Kontexten zu analysieren und gemeinsame Muster zu erkennen.
Beim Wörterbuchlernen werden diese Aktivierungen zu einer kleineren Menge aussagekräftiger "Merkmale" zusammengefasst, die vom Modell erlernte Konzepte auf höherer Ebene darstellen.
Durch die Identifizierung dieser Merkmale können die Forscher besser verstehen, wie das Modell Informationen verarbeitet und darstellt.
Extraktion von Merkmalen aus der mittleren Schicht
Die Forscher konzentrierten sich auf die mittlere Schicht der Claude 3.0 Sonnet, das als kritischer Punkt in der Verarbeitungspipeline des Modells dient.
Durch die Anwendung des Wörterbuchlernens auf diese Ebene werden Millionen von Merkmalen extrahiert, die die internen Repräsentationen des Modells und die gelernten Konzepte in diesem Stadium erfassen.
Die Extraktion von Merkmalen aus der mittleren Schicht ermöglicht es den Forschern, das Informationsverständnis des Modells zu untersuchen nach er hat die Eingabe verarbeitet vor die Erzeugung der endgültigen Ausgabe.
Entdeckung vielfältiger und abstrakter Konzepte
Die extrahierten Merkmale zeigten eine breite Palette von Konzepten, die von Claudevon konkreten Entitäten wie Städten und Menschen bis hin zu abstrakten Begriffen, die sich auf wissenschaftliche Bereiche und Programmiersyntax beziehen.
Interessanterweise erwiesen sich die Merkmale als multimodal und reagierten sowohl auf textuelle als auch auf visuelle Eingaben, was darauf hindeutet, dass das Modell Konzepte über verschiedene Modalitäten hinweg lernen und darstellen kann.
Darüber hinaus deuten die mehrsprachigen Merkmale darauf hin, dass das Modell Konzepte erfassen kann, die in verschiedenen Sprachen ausgedrückt werden.

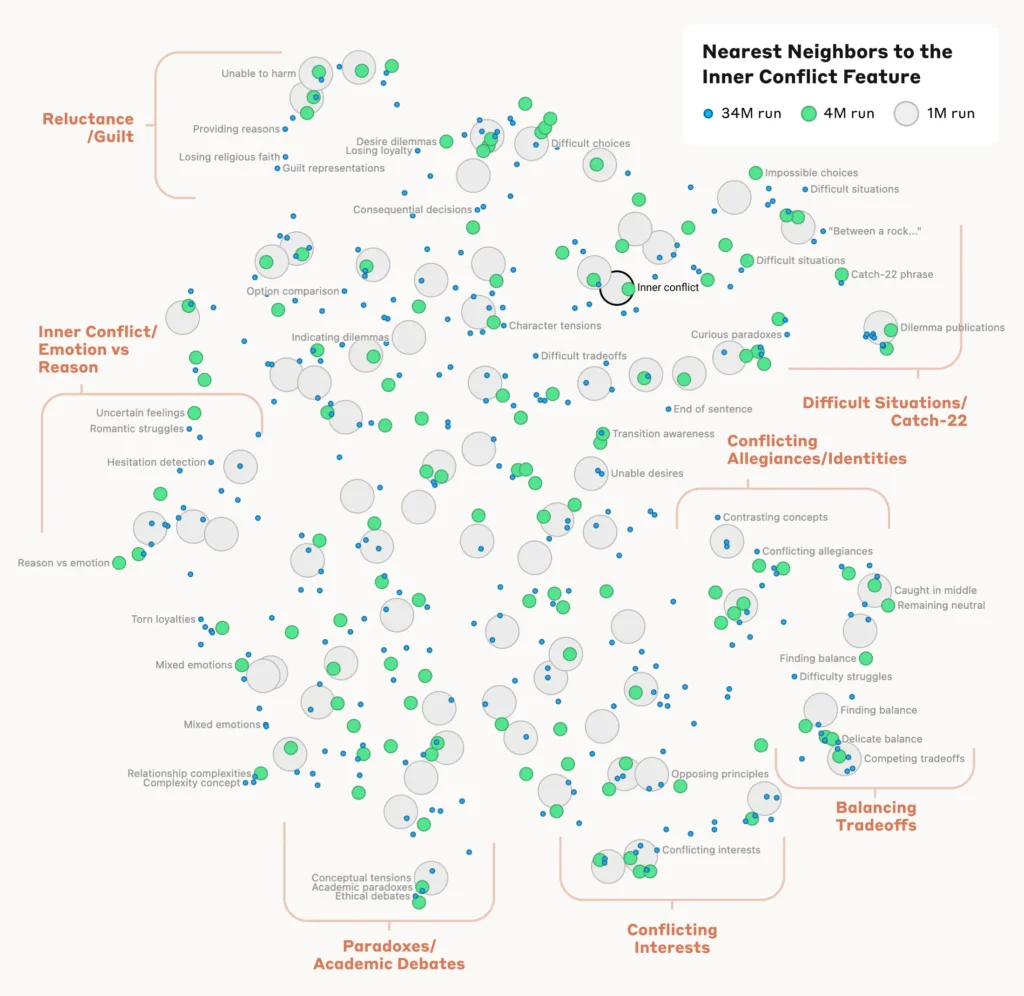
Analyse der Organisation von Konzepten
Um zu verstehen, wie das Modell die verschiedenen Konzepte organisiert und miteinander in Beziehung setzt, analysierten die Forscher die Ähnlichkeit zwischen den Merkmalen auf der Grundlage ihrer Aktivierungsmuster.
Sie entdeckten, dass Merkmale, die verwandte Konzepte darstellen, dazu neigen, sich zu gruppieren. So wiesen beispielsweise Merkmale, die mit Städten oder wissenschaftlichen Disziplinen in Verbindung stehen, eine größere Ähnlichkeit untereinander auf als Merkmale, die nicht verwandte Konzepte darstellen.
Dies deutet darauf hin, dass die interne Organisation der Konzepte des Modells bis zu einem gewissen Grad mit der menschlichen Intuition über konzeptionelle Beziehungen übereinstimmt.
Überprüfen der Merkmale
Um zu bestätigen, dass die identifizierten Merkmale einen direkten Einfluss auf das Verhalten und die Ergebnisse des Modells haben, führten die Forscher Experimente zur "Merkmalssteuerung" durch.
Dabei wurde die Aktivierung bestimmter Merkmale während der Verarbeitung des Modells selektiv verstärkt oder unterdrückt und die Auswirkungen auf die Reaktionen des Modells beobachtet.
Durch die Manipulation einzelner Merkmale konnten die Forscher eine direkte Verbindung zwischen einzelnen Merkmalen und dem Verhalten des Modells herstellen. So führte beispielsweise die Verstärkung eines Merkmals, das sich auf eine bestimmte Stadt bezog, dazu, dass das Modell auch in irrelevanten Kontexten stadtbezogene Ergebnisse erzeugte.
Lesen Sie die vollständige Studie hier.
Warum Interpretierbarkeit für die KI-Sicherheit entscheidend ist
AnthropicDie Forschungen der Gruppe sind von grundlegender Bedeutung für die Interpretierbarkeit von KI und damit auch für die Sicherheit.
Zu verstehen, wie LLMs Informationen verarbeiten und darstellen, hilft Forschern, Risiken zu verstehen und zu mindern. Es legt den Grundstein für die Entwicklung transparenter und erklärbarer KI-Systeme.
Als Anthropic erklärt: "Wir hoffen, dass wir und andere diese Entdeckungen nutzen können, um Modelle sicherer zu machen. Zum Beispiel könnte es möglich sein, die hier beschriebenen Techniken zu nutzen, um KI-Systeme auf bestimmte gefährliche Verhaltensweisen zu überwachen (z. B. Täuschung des Nutzers), sie auf wünschenswerte Ergebnisse zu lenken (Debiasierung) oder bestimmte gefährliche Themen ganz zu entfernen.
Ein besseres Verständnis des KI-Verhaltens ist von entscheidender Bedeutung, da KI in kritischen Entscheidungsprozessen in Bereichen wie dem Gesundheitswesen, dem Finanzwesen und der Strafjustiz allgegenwärtig ist. Es hilft auch bei der Aufdeckung der Ursache von VorspannungHalluzinationen und andere unerwünschte oder unvorhersehbare Verhaltensweisen.
Zum Beispiel, ein aktuelle Studie von der Universität Bonn haben aufgedeckt, dass Graphische Neuronale Netze (GNNs), die für die Entdeckung von Medikamenten verwendet werden, sich stark auf das Abrufen von Ähnlichkeiten aus Trainingsdaten verlassen, anstatt wirklich komplexe neue chemische Interaktionen zu lernen.
Das macht es schwierig zu verstehen, wie genau diese Modelle neue Verbindungen von Interesse bestimmen.
Letztes Jahr hat die Die britische Regierung verhandelte mit großen Tech-Giganten wie OpenAI und DeepMinddie Zugang zu den internen Entscheidungsprozessen ihrer KI-Systeme suchen.
Verordnung wie die Das KI-Gesetz der EU wird die KI-Unternehmen zu mehr Transparenz zwingen, auch wenn Geschäftsgeheimnisse sicher unter Verschluss bleiben werden.
AnthropicDie Forschungen der Universität München geben einen Einblick in das Innere der Box, indem sie Informationen über das Modell "abbilden".
Die Wahrheit ist jedoch, dass diese Modelle so umfangreich sind, dass sie AnthropicWir halten es für ziemlich wahrscheinlich, dass wir um Größenordnungen zu kurz kommen und dass wir, wenn wir alle Merkmale - in allen Schichten! - sehr viel mehr Rechenleistung benötigen würden, als für das Training der zugrunde liegenden Modelle erforderlich ist.
Das ist ein interessanter Punkt - das Reverse Engineering eines Modells ist rechnerisch komplexer als das Engineering des Modells selbst.
Es erinnert an enorm teure neurowissenschaftliche Projekte wie das Human Brain Project (HBP)die Milliarden in die Kartierung unserer eigenen menschlichen Gehirne gesteckt hat, nur um letztendlich zu scheitern.
Unterschätzen Sie nie, wie viel im Inneren der Blackbox steckt.



