

Et studie fra University of Oxford har udviklet en metode til at teste, hvornår sprogmodeller er "usikre" på deres output og risikerer at hallucinere.
AI-"hallucinationer" henviser til et fænomen, hvor store sprogmodeller (LLM'er) genererer flydende og plausible svar, som ikke er sandfærdige eller konsistente.
Hallucinationer er svære - hvis ikke umulige - at adskille fra AI-modeller. AI-udviklere som OpenAI, Google og Anthropic har alle indrømmet, at hallucinationer sandsynligvis vil forblive et biprodukt af at interagere med AI.
Som Dr. Sebastian Farquhar, en af undersøgelsens forfattere, siger, forklarer i et blogindlæg"LLM'er er i høj grad i stand til at sige det samme på mange forskellige måder, hvilket kan gøre det svært at se, hvornår de er sikre på et svar, og hvornår de bogstaveligt talt bare finder på noget."
Cambridge Dictionary har endda tilføjet en AI-relateret definition af ordet i 2023 og udnævnte det til "Årets ord".
Dette universitet i Oxford undersøgelseoffentliggjort i Nature, forsøger at svare på, hvordan vi kan opdage, hvornår disse hallucinationer er mest sandsynlige.
Den introducerer et begreb kaldet "semantisk entropi", som måler usikkerheden i en LLM's output på betydningsniveau i stedet for blot de specifikke ord eller sætninger, der bruges.
Ved at beregne den semantiske entropi i en LLM's svar kan forskerne estimere modellens tillid til dens output og identificere tilfælde, hvor det er sandsynligt, at den hallucinerer.
Semantisk entropi i LLM'er forklaret
Semantisk entropi, som defineret i undersøgelsen, måler usikkerheden eller inkonsistensen i betydningen af en LLM's svar. Det hjælper med at opdage, når en LLM måske hallucinerer eller genererer upålidelige oplysninger.
Enkelt sagt måler semantisk entropi, hvor "forvirret" en LLM's output er.
LLM vil sandsynligvis give pålidelig information, hvis betydningen af dens output er tæt forbundet og konsistent. Men hvis betydningerne er spredte og inkonsekvente, er det et rødt flag for, at LLM'en måske hallucinerer eller genererer unøjagtige oplysninger.
Sådan her fungerer det:
- Forskerne opfordrede aktivt LLM til at generere flere mulige svar på det samme spørgsmål. Det sker ved at sende spørgsmålet til LLM'en flere gange, hver gang med et forskelligt tilfældigt frø eller en lille variation i input.
- Semantisk entropi undersøger svar og grupperer dem med samme underliggende betydning, selv om de bruger forskellige ord eller formuleringer.
- Hvis LLM'en er sikker på svaret, bør dens svar have samme betydning, hvilket resulterer i en lav semantisk entropiscore. Det tyder på, at LLM'en klart og konsekvent forstår informationen.
- Men hvis LLM'en er usikker eller forvirret, vil dens svar have en bredere vifte af betydninger, hvoraf nogle kan være inkonsekvente eller ikke relateret til spørgsmålet. Dette resulterer i en høj semantisk entropiscore, hvilket indikerer, at LLM'en kan hallucinere eller generere upålidelig information.
For at evaluere dens effektivitet anvendte forskerne semantisk entropi på en række forskellige spørgsmålssvaropgaver. Dette involverede benchmarks som trivia-spørgsmål, læseforståelse, ordopgaver og biografier.
Over hele linjen var semantisk entropi bedre end eksisterende metoder til at opdage, hvornår en LLM sandsynligvis ville generere et forkert eller inkonsekvent svar.
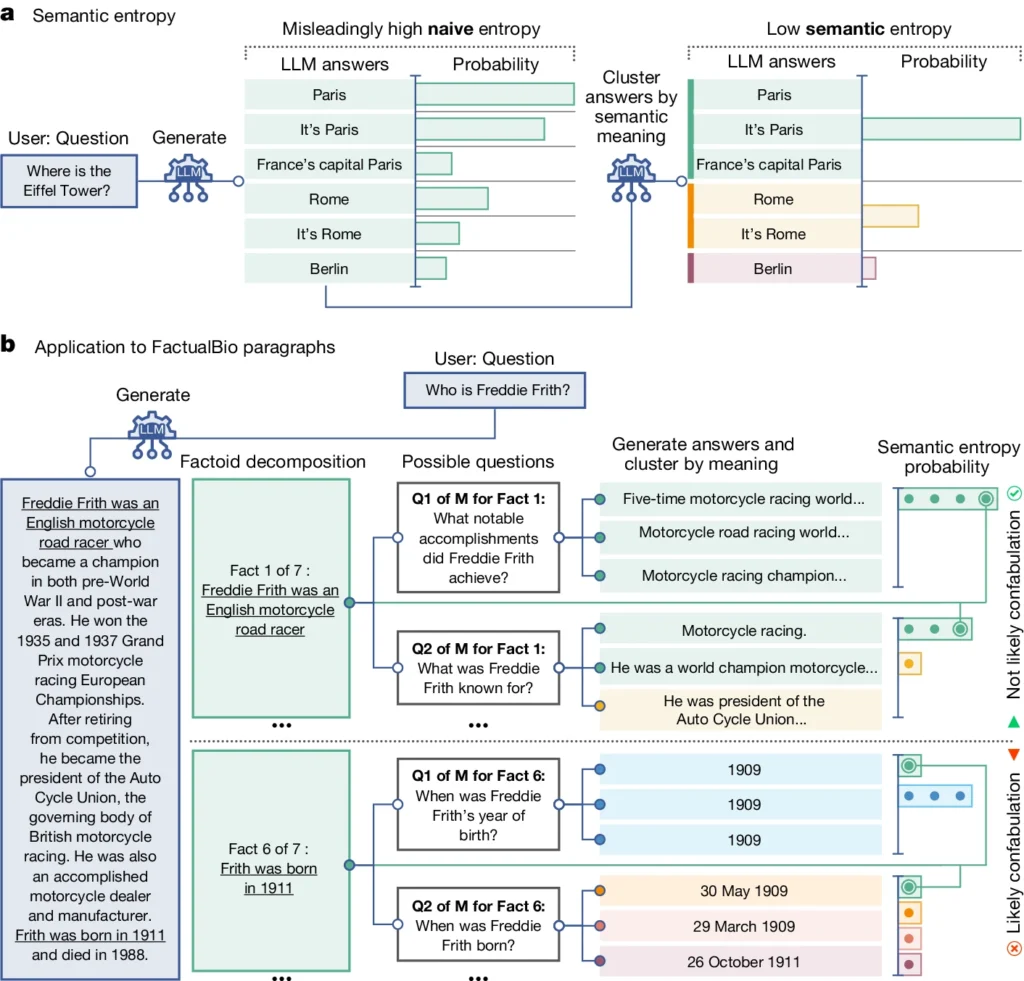
I ovenstående diagram kan du se, hvordan nogle spørgsmål presser LLM til at generere et konfabuleret (unøjagtigt, hallucinatorisk) svar. For eksempel producerer den en fødselsdag og -måned til spørgsmålene i bunden af diagrammet, når de oplysninger, der kræves for at besvare dem, ikke blev givet i de oprindelige oplysninger.
Konsekvenser af at opdage hallucinationer
Dette arbejde kan hjælpe med at forklare hallucinationer og gøre LLM'er mere pålidelige og troværdige.
Ved at give mulighed for at opdage, hvornår en LLM er usikker eller tilbøjelig til at hallucinere, baner semantisk entropi vejen for at anvende disse AI-værktøjer på områder, hvor der står meget på spil, og hvor faktuel nøjagtighed er afgørende, som f.eks. sundhedspleje, jura og finans.
Fejlagtige resultater kan have potentielt katastrofale konsekvenser, når de påvirker situationer med høj indsats, som det fremgår af nogle mislykket forudsigende politiarbejde og sundhedssystemer.
Men det er også vigtigt at huske, at hallucinationer kun er én type fejl, som LLM'er kan begå.
Som Dr. Farquhar forklarer: "Hvis en LLM laver konsekvente fejl, vil denne nye metode ikke fange det. De farligste fejl i AI kommer, når et system gør noget dårligt, men er selvsikkert og systematisk. Der er stadig meget arbejde at gøre."
Ikke desto mindre repræsenterer Oxford-teamets semantiske entropimetode et stort skridt fremad i vores evne til at forstå og afbøde begrænsningerne i AI-sprogmodeller.
At tilvejebringe et objektivt middel til at opdage dem bringer os tættere på en fremtid, hvor vi kan udnytte AI's potentiale og samtidig sikre, at det forbliver et pålideligt og troværdigt værktøj i menneskehedens tjeneste.



