

AI-alderen byder på et komplekst samspil mellem teknologi og samfundets holdninger.
Den øgede sofistikering af AI-systemer slører grænserne mellem mennesker og maskiner - er AI-teknologi adskilt fra os selv? I hvor høj grad arver AI menneskelige fejl og mangler sammen med færdigheder og viden?
Det er måske fristende at forestille sig AI som en empirisk teknologi, der understreges af matematikkens, kodens og beregningernes objektivitet.
Men vi har indset, at de beslutninger, som AI-systemerne træffer, er meget subjektive baseret på de data, de udsættes for - og det er mennesker, der beslutter, hvordan disse data skal udvælges og samles.
Heri ligger en udfordring, da AI-træningsdata ofte er udtryk for de fordomme og den diskrimination, som menneskeheden kæmper mod.
Selv tilsyneladende subtile former for ubevidst bias kan forstærkes af modeltræningsprocessen og i sidste ende afsløre sig i form af forkerte ansigtsmatch i retshåndhævelsessammenhænge, afslag på kredit, fejldiagnosticering af sygdomme og forringede sikkerhedsmekanismer for selvkørende køretøjer, blandt andre ting.
Menneskehedens forsøg på at forhindre diskrimination på tværs af samfundet er stadig et igangværende arbejde, men AI driver kritisk beslutningstagning lige nu.
Kan vi arbejde hurtigt nok til at synkronisere AI med moderne værdier og forhindre forudindtagede livsændrende beslutninger og adfærd?
Afdækning af bias i AI
I det sidste årti har AI-systemer vist sig at afspejle samfundets fordomme.
Disse systemer er ikke i sig selv forudindtagede - i stedet absorberer de deres skaberes forudindtagethed og de data, de er trænet på.
AI-systemer lærer ligesom mennesker ved at blive eksponeret. Den menneskelige hjerne er et tilsyneladende endeløst informationsregister - et bibliotek med næsten ubegrænsede hylder, hvor vi opbevarer oplevelser, viden og minder.
Neurovidenskabelig studier viser, at hjernen ikke har nogen "maksimal kapacitet" og fortsætter med at sortere og lagre information langt op i alderen.
Selv om den langt fra er perfekt, hjælper hjernens progressive, iterative læringsproces os med at tilpasse os nye kulturelle og samfundsmæssige værdier, fra at give kvinder stemmeret og acceptere forskellige identiteter til at gøre en ende på slaveri og andre former for bevidste fordomme.
We lever nu i en tid, hvor AI-værktøjer bruges til kritisk beslutningstagning i stedet for menneskelig dømmekraft.
Mange maskinlæringsmodeller (ML) lærer af træningsdata, der danner grundlag for deres beslutningstagning, og kan ikke inddrage nye oplysninger lige så effektivt som den menneskelige hjerne. Derfor er de ofte ikke i stand til at producere de opdaterede beslutninger, som vi er kommet til at stole på.
For eksempel bruges AI-modeller til at identificere ansigtsmatch til retshåndhævelsesformål, analysere CV'er til jobansøgningerog træffe sundhedskritiske beslutninger i kliniske sammenhænge.
Når samfundet fortsætter med at integrere AI i vores hverdag, skal vi sikre, at det er lige og præcist for alle.
Det er ikke tilfældet i øjeblikket.
Casestudier i AI-bias
Der er mange eksempler fra den virkelige verden på AI-relateret bias, fordomme og diskrimination.
I nogle tilfælde er konsekvenserne af AI-bias livsforandrende, mens de i andre tilfælde bliver hængende i baggrunden og påvirker beslutninger på en subtil måde.
1. MIT's skævhed i datasættet
Et MIT-træningsdatasæt bygget i 2008 kaldet Små billeder indeholdt ca. 80.000.000 billeder fordelt på ca. 75.000 kategorier.
Det blev oprindeligt udtænkt til at lære AI-systemer at genkende mennesker og objekter i billeder og blev et populært benchmarking-datasæt til forskellige anvendelser inden for computersyn (CV).
A 2020 analyse af The Register fandt ud af, at mange Tiny Images indeholdt uanstændige, racistiske og sexistiske etiketter.
Antonio Torralba fra MIT sagde, at laboratoriet ikke kendte til disse stødende etiketter, og sagde til The Register: "Det er klart, at vi burde have screenet dem manuelt." MIT udsendte senere en erklæring om, at de havde fjernet datasættet fra tjenesten.

Det er ikke den eneste gang, et tidligere benchmark-datasæt har vist sig at være fyldt med problemer. Labeled Faces in the Wild (LFW), et datasæt med berømthedsansigter, der bruges flittigt i ansigtsgenkendelsesopgaver, består af 77,5% mænd og 83,5% hvidhudede personer.
Mange af disse veterandatasæt har fundet vej til moderne AI-modeller, men stammer fra en æra med AI-udvikling, hvor fokus var på at bygge systemer, der bare arbejde snarere end dem, der er egnede til implementering i virkelige scenarier.
Når et AI-system er trænet på et sådant datasæt, har det ikke nødvendigvis det samme privilegium som den menneskelige hjerne til at omkalibrere til nutidige værdier.
Modeller kan opdateres iterativt, men det er en langsom og ufuldkommen proces, der ikke kan matche tempoet i den menneskelige udvikling.
2: Billedgenkendelse: bias mod mørkhudede personer
I 2019 vil Den amerikanske regering fandt at de bedste ansigtsgenkendelsessystemer fejlidentificerer sorte mennesker 5 til 10 gange mere end hvide mennesker.
Det er ikke bare en statistisk anomali - det har alvorlige konsekvenser i den virkelige verden, lige fra Google Fotos, der identificerer sorte mennesker som gorillaer, til selvkørende biler, der ikke genkender mørkhudede personer og kører ind i dem.
Derudover var der en bølge af uretmæssige anholdelser og fængslinger, der involverede falske ansigtsmatch, måske mest produktivt Nijeer Parks' som fejlagtigt blev anklaget for butikstyveri og færdselsforseelser, selv om han befandt sig 50 km væk fra hændelsen. Parks tilbragte efterfølgende 10 dage i fængsel og måtte punge ud med tusindvis af kroner i sagsomkostninger.

Den indflydelsesrige undersøgelse fra 2018, Nuancer af kønundersøgte yderligere algoritmisk bias. Undersøgelsen analyserede algoritmer bygget af IBM og Microsoft og fandt dårlig nøjagtighed, når de blev udsat for mørkhudede kvinder, med fejlrater op til 34% større end for lyshudede mænd.
Dette mønster viste sig at være konsekvent på tværs af 189 forskellige algoritmer.
Videoen nedenfor fra undersøgelsens hovedforsker Joy Buolamwini giver en glimrende guide til, hvordan ansigtsgenkendelsens ydeevne varierer på tværs af hudfarver.
3: OpenAI's CLIP-projekt
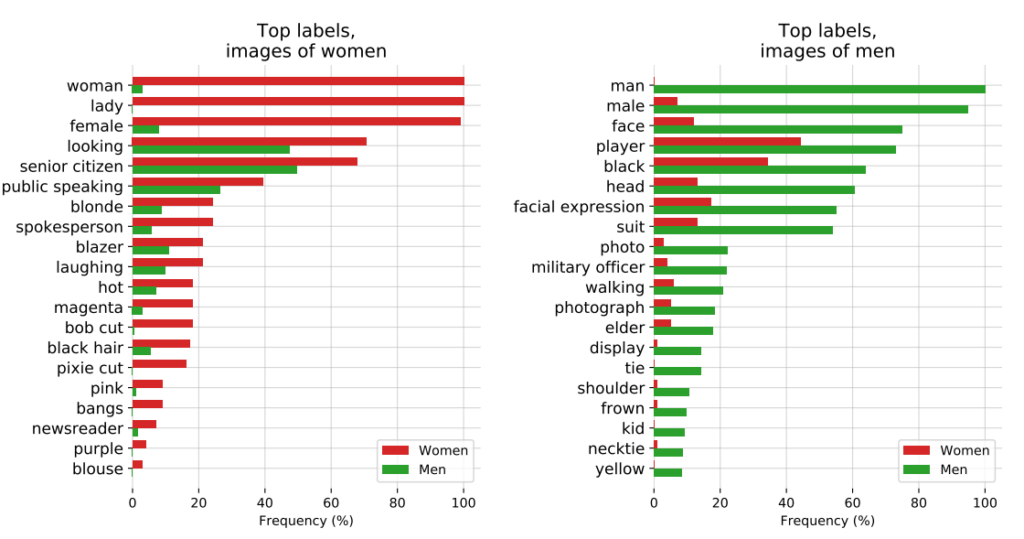
OpenAI's CLIP-projektetder blev udgivet i 2021, og som er designet til at matche billeder med beskrivende tekst, illustrerede også løbende problemer med bias.
I et revisionspapir fremhævede CLIP's skabere deres bekymringer og sagde: "CLIP vedhæftede nogle etiketter, der beskrev højstatuserhverv, uforholdsmæssigt ofte til mænd, såsom 'leder' og 'læge'. Dette svarer til de skævheder, der findes i Google Cloud Vision (GCV), og peger på historiske kønsbestemte forskelle."
4: Retshåndhævelse: PredPol-kontroversen
Et andet eksempel på algoritmisk bias med høj indsats er PredPolen algoritme til forudseende politiarbejde, som bruges af forskellige politiafdelinger i USA.
PredPol blev trænet på historiske kriminalitetsdata for at forudsige fremtidige hotspots for kriminalitet.
Men da disse data i sagens natur afspejler en partisk politipraksis, er algoritmen blevet kritiseret for at opretholde raceprofilering og for at ramme minoritetsområder uforholdsmæssigt hårdt.
5: Bias i dermatologisk AI
I sundhedsvæsenet bliver de potentielle risici ved AI-bias endnu tydeligere.
Tag eksemplet med AI-systemer, der er designet til at opdage hudkræft. Mange af disse systemer er trænet på datasæt, der overvejende består af lyshudede personer.
A 2021 undersøgelse foretaget af University of Oxford undersøgte 21 open access-datasæt for billeder af hudkræft. De opdagede, at ud af de 14 datasæt, der afslørede deres geografiske oprindelse, bestod 11 udelukkende af billeder fra Europa, Nordamerika og Oceanien.
Kun 2.436 ud af 106.950 billeder på tværs af de 21 databaser havde oplysninger om hudtype registreret. Forskerne bemærkede, at "kun 10 billeder var fra personer, der var registreret som havende brun hud, og et var fra en person, der var registreret som havende mørkebrun eller sort hud."
Med hensyn til data om etnicitet var det kun 1.585 billeder, der indeholdt disse oplysninger. Forskerne fandt ud af, at "ingen billeder var fra personer med afrikansk, afrikansk-caribisk eller sydasiatisk baggrund."
De konkluderede: "Sammen med datasættenes geografiske oprindelse var der en massiv underrepræsentation af billeder af hudlæsioner fra mørkhudede befolkninger."
Hvis sådanne AI'er anvendes i kliniske sammenhænge, skaber forudindtagede datasæt en meget reel risiko for fejldiagnoser.
Dissekering af bias i AI-træningsdatasæt: et produkt af deres skabere?
Træningsdata - oftest tekst, tale, billeder og video - giver en overvåget maskinlæringsmodel (ML) et grundlag for at lære begreber.
AI-systemer er ikke andet end tomme lærreder fra starten. De lærer og danner associationer baseret på vores data og maler i bund og grund et billede af verden, som den er afbildet i deres træningsdatasæt.
Ved at lære af træningsdata er håbet, at modellen vil anvende de lærte begreber på nye, usete data.
Når de er implementeret, kan nogle avancerede modeller lære af nye data, men deres træningsdata styrer stadig deres grundlæggende ydeevne.
Det første spørgsmål, der skal besvares, er, hvor dataene kommer fra? Data indsamlet fra ikke-repræsentative, ofte homogene og historisk ulige kilder er problematiske.
Det gælder sandsynligvis for en betydelig mængde onlinedata, herunder tekst- og billeddata, der er skrabet fra "åbne" eller "offentlige" kilder.
Internettet blev skabt for bare få årtier siden, men det er ikke et universalmiddel for menneskelig viden og er langt fra retfærdigt. Halvdelen af verden bruger ikke internettet, endsige bidrager til det, hvilket betyder, at det grundlæggende ikke er repræsentativt for det globale samfund og den globale kultur.
Og selvom AI-udviklere konstant arbejder på at sikre, at teknologiens fordele ikke er begrænset til den engelsktalende verden, produceres størstedelen af træningsdata (tekst og tale) på engelsk - hvilket betyder, at engelsktalende bidragsydere styrer modellens output.
Forskere fra Anthropic har for nylig udgav en artikel om netop dette emne og konkluderede: "Hvis en sprogmodel i uforholdsmæssig grad repræsenterer visse meninger, risikerer den at få potentielt uønskede virkninger, såsom at fremme hegemoniske verdensbilleder og homogenisere folks perspektiver og overbevisninger."
Selv om AI-systemer fungerer ud fra de "objektive" principper for matematik og programmering, eksisterer de ikke desto mindre inden for og formes af en dybt subjektiv menneskelig social kontekst.
Mulige løsninger på algoritmisk bias
Hvis data er det grundlæggende problem, kan løsningen på at opbygge retfærdige modeller virke enkel: Man gør bare datasættene mere afbalancerede, ikke sandt?
Ikke helt. A 2019 undersøgelse viste, at det ikke er tilstrækkeligt at afbalancere datasæt, da algoritmer stadig handler uforholdsmæssigt meget på baggrund af beskyttede karakteristika som køn og race.
Forfatterne skriver: "Overraskende nok viser vi, at selv når datasæt er afbalancerede, så hver etiket forekommer lige meget med hvert køn, forstærker indlærte modeller sammenhængen mellem etiketter og køn, lige så meget som hvis data ikke havde været afbalancerede!"
De foreslår en de-biasing-teknik, hvor sådanne etiketter fjernes helt fra datasættet. Andre teknikker omfatter tilføjelse af tilfældige forstyrrelser og forvrængninger, som reducerer en algoritmes opmærksomhed på specifikke beskyttede egenskaber.
Selv om modificering af maskinlæringsmetoder og optimering er afgørende for at producere ikke-partisk output, er avancerede modeller modtagelige for ændringer eller 'drift', hvilket betyder, at deres præstationer ikke nødvendigvis forbliver konsistente på lang sigt.
En model kan være helt upartisk ved udrulning, men senere blive partisk med øget eksponering for nye data.
Bevægelsen for algoritmisk gennemsigtighed
I sin provokerende bog Kunstig uintelligens: Hvordan computere misforstår verdenMeredith Broussard argumenterer for øget "algoritmisk gennemsigtighed" for at udsætte AI-systemer for flere niveauer af løbende kontrol.
Det betyder, at man skal give klar information om, hvordan systemet fungerer, hvordan det er blevet trænet, og hvilke data det er blevet trænet på.
Mens gennemsigtighedsinitiativer let absorberes i open source AI-landskabet, er proprietære modeller som GPT, Bard og Anthropics Claude 'sorte bokse', og kun deres udviklere ved præcist, hvordan de fungerer - og selv det er et spørgsmål om debat.
Problemet med den "sorte boks" i AI betyder, at eksterne observatører kun ser, hvad der går ind i modellen (input), og hvad der kommer ud (output). Den indre mekanik er fuldstændig ukendt, undtagen for deres skabere - ligesom den magiske cirkel beskytter tryllekunstneres hemmeligheder. AI trækker bare kaninen op af hatten.
Spørgsmålet om sorte bokse blev for nylig udkrystalliseret omkring rapporter om GPT-4's potentielle fald i ydeevne. GPT-4-brugere hævder, at modellens evner er faldet hurtigt, og selv om OpenAI har erkendt, at det er sandt, har de ikke været helt klare over, hvorfor det sker. Det rejser spørgsmålet, om de overhovedet ved det?
AI-forsker Dr. Sasha Luccioni siger, at OpenAI's manglende gennemsigtighed er et problem, der også gælder for andre proprietære eller lukkede AI-modeludviklere. "Alle resultater fra lukkede modeller kan ikke reproduceres eller verificeres, og derfor sammenligner vi fra et videnskabeligt perspektiv vaskebjørne og egern."
“Det er ikke forskernes opgave løbende at overvåge implementerede LLM'er. Det er op til modelskaberne at give adgang til de underliggende modeller, i det mindste til revisionsformål," siger hun.
Luccioni understregede, at udviklere af AI-modeller bør levere rå resultater fra standardbenchmarks som SuperGLUE og WikiText og biasbenchmarks som BOLD og HONEST.
Kampen mod AI-drevet bias og fordomme vil sandsynligvis være konstant og kræve løbende opmærksomhed og forskning for at holde modeloutput i skak, efterhånden som AI og samfundet udvikler sig sammen.
Mens regulering vil kræve former for overvågning og rapportering, er der kun få hårde og hurtige løsninger på spørgsmålet om algoritmisk bias, og det er ikke sidste gang, vi hører om det.



