

Vi hører meget om AI-sikkerhed, men betyder det, at det fylder meget i forskningen?
En ny undersøgelse fra Georgetown University's Emerging Technology Observatory tyder på, at forskning i AI-sikkerhed på trods af støjen kun udgør et lille mindretal af branchens forskningsfokus.
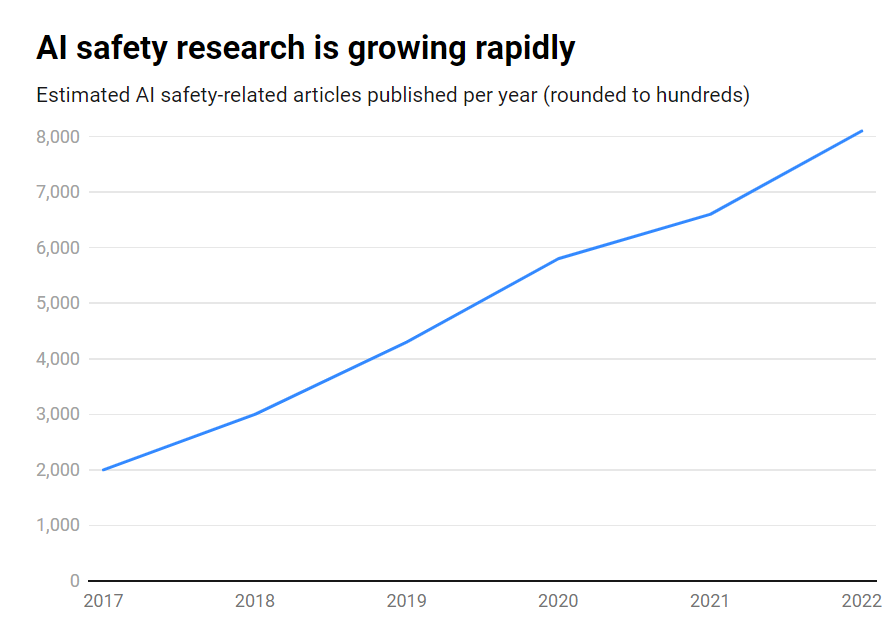
Forskerne analyserede over 260 millioner videnskabelige publikationer og fandt ud af, at kun 2% af de AI-relaterede artikler, der blev udgivet mellem 2017 og 2022, direkte behandlede emner relateret til AI-sikkerhed, etik, robusthed eller styring.
Selvom antallet af publikationer om AI-sikkerhed voksede med imponerende 315% i den periode, fra omkring 1.800 til over 7.000 om året, er det stadig et perifert emne.
Her er de vigtigste resultater:
- Kun 2% af AI-forskningen fra 2017-2022 fokuserede på AI-sikkerhed
- AI-sikkerhedsforskningen voksede 315% i den periode, men er en dværg i forhold til den samlede AI-forskning
- USA er førende inden for forskning i AI-sikkerhed, mens Kina halter bagefter
- De vigtigste udfordringer er robusthed, retfærdighed, gennemsigtighed og opretholdelse af menneskelig kontrol.
Mange førende AI-forskere og etikere har advaret om eksistentielle risici, hvis kunstig generel intelligens (AGI) udvikles uden tilstrækkelige sikkerhedsforanstaltninger og forholdsregler.
Forestil dig et AGI-system, der er i stand til at forbedre sig selv rekursivt og hurtigt overgår den menneskelige intelligens, mens det forfølger mål, der ikke er i overensstemmelse med vores værdier. Det er et scenarie, som nogle mener kan komme ud af vores kontrol.
Men det er ikke envejstrafik. Faktisk mener et stort antal AI-forskere, at AI-sikkerhed er overhypet.
Derudover mener nogle endda, at hypen er blevet fremstillet for at hjælpe Big Tech med at håndhæve regler og eliminere græsrødder og open source-konkurrenter.
Men selv nutidens snævre AI-systemer, der er trænet på tidligere data, kan udvise bias, producere skadeligt indhold, krænke privatlivets fred og blive brugt ondsindet.
Så selvom AI-sikkerhed skal se ind i fremtiden, skal den også håndtere risici her og nu, hvilket uden tvivl er utilstrækkeligt, da deep fakes, bias og andre problemer fortsat fylder meget.
Effektiv forskning i AI-sikkerhed skal adressere udfordringer på kort sigt såvel som spekulative risici på længere sigt.
USA er førende inden for forskning i AI-sikkerhed
Når man dykker ned i dataene, er USA klart førende inden for forskning i AI-sikkerhed med 40% af relaterede publikationer sammenlignet med 12% fra Kina.
Men Kinas sikkerhedsproduktion halter langt bagefter landets samlede AI-forskning - mens 5% af den amerikanske AI-forskning omhandlede sikkerhed, var det kun 1% af Kinas.
Man kunne forestille sig, at det er en meget vanskelig opgave at undersøge kinesisk forskning. Desuden har Kina været proaktiv omkring regulering - uden tvivl mere end USA - så disse data giver måske ikke landets AI-industri en fair behandling.
På institutionsniveau fører Carnegie Mellon University, Google, MIT og Stanford an.
Men globalt set producerede ingen organisation mere end 2% af de samlede sikkerhedsrelaterede publikationer, hvilket understreger behovet for en større og mere samordnet indsats.
Ubalancer i sikkerheden
Så hvad kan man gøre for at rette op på denne ubalance?
Det afhænger af, om man mener, at AI-sikkerhed er en presserende risiko på linje med atomkrig, pandemier osv. Der er ikke noget entydigt svar på dette spørgsmål, hvilket gør AI-sikkerhed til et meget spekulativt emne med ringe gensidig aftale mellem forskere.
Sikkerhedsforskning og etik er også en slags tangentielt domæne til maskinlæring, der kræver andre færdigheder, akademiske baggrunde osv. og som måske ikke er velfinansieret.
At lukke AI-sikkerhedskløften vil også kræve, at man konfronterer spørgsmål om åbenhed og hemmeligholdelse i AI-udvikling.
De største teknologivirksomheder udfører omfattende intern sikkerhedsforskning, som aldrig er blevet offentliggjort. I takt med at kommercialiseringen af AI tager fart, bliver virksomhederne mere beskyttende over for deres AI-gennembrud.
OpenAI var for eksempel et kraftcenter for forskning i sine tidlige dage.
Virksomheden plejede at producere dybdegående uafhængige revisioner af sine produkter, mærkningsforstyrrelser og risici - som f.eks. sexistisk bias i sit CLIP-projekt.
Anthropic er stadig aktivt engageret i forskning i offentlig AI-sikkerhed og udgiver ofte studier om skævhed og jailbreaking.
DeepMind dokumenterede også muligheden for, at AI-modeller etablerer "emergente mål" og aktivt modsiger deres instruktioner eller bliver fjendtlige over for deres skabere.
Overordnet set er sikkerheden dog trådt i baggrunden for fremskridtet, da Silicon Valley lever efter sit motto om at 'bevæge sig hurtigt og ødelægge ting'.
Georgetown-undersøgelsen fremhæver i sidste ende, at universiteter, regeringer, teknologivirksomheder og forskningsfinansiører er nødt til at investere flere kræfter og penge i AI-sikkerhed.
Nogle har også opfordret til en internationalt organ for AI-sikkerhedDet svarer til Det Internationale Atomenergiagentur (IAEA), som blev oprettet efter en række atomhændelser, der gjorde et omfattende internationalt samarbejde obligatorisk.
Får AI brug for sin egen katastrofe for at få staten og virksomhederne til at samarbejde på det niveau? Lad os ikke håbe det.



