

Google’s DeepMind released Gecko, a new benchmark for comprehensively evaluating AI text-to-image (T2I) models.
Over the last two years, we’ve seen AI image generators like DALL-E and Midjourney become progressively better with each version release.
However, deciding which of the underlying models these platforms use is best has been largely subjective and difficult to benchmark.
To make a broad claim that one model is “better” than another isn’t so simple. Different models excel in various aspects of image generation. One may be good at text rendering while another may be better at object interaction.
A key challenge that T2I models face is to follow each detail in the prompt and have these accurately reflected in the generated image.
With Gecko, the DeepMind researchers have created a benchmark that evaluates the capabilities of T2I models similarly to how humans do.
Skill set
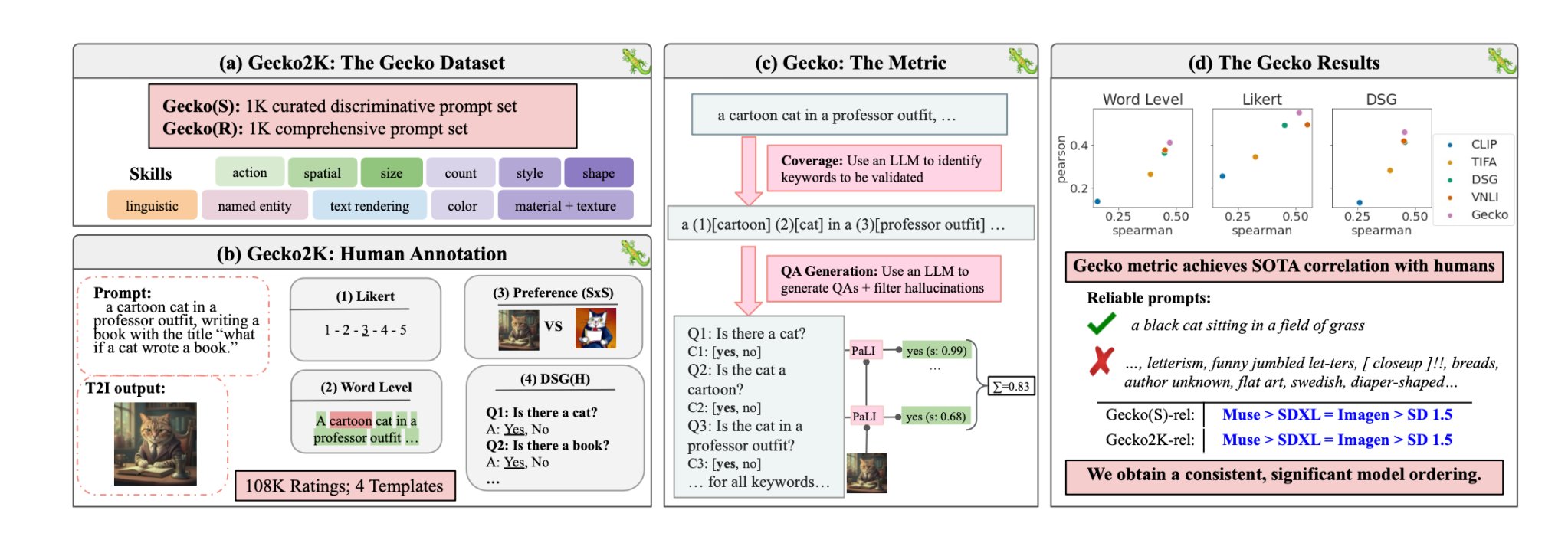
The researchers first defined a comprehensive dataset of skills relevant to T2I generation. These include spatial understanding, action recognition, text rendering, and others. They further broke these down into more specific sub-skills.
For example, under text rendering, sub-skills might include rendering different fonts, colors, or text sizes.
An LLM was then used to generate prompts to test the T2I model’s capability on a specific skill or sub-skill.
This enables the creators of a T2I model to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging for their model.
Human vs Auto eval
Gecko also measures how accurately a T2I model follows all the details in a prompt. Again, an LLM was used to isolate key details in each input prompt and then generate a set of questions related to those details.
These questions could be both simple, direct questions about visible elements in the image (e.g., “Is there a cat in the image?”) and more complex questions that test understanding of the scene or the relationships between objects (e.g., “Is the cat sitting above the book?”).
A Visual Question Answering (VQA) model then analyzes the generated image and answers the questions to see how accurately the T2I model aligns its output image with an input prompt.
The researchers collected over 100,000 human annotations where the participants scored a generated image based on how aligned the image was to specific criteria.
The humans were asked to consider a specific aspect of the input prompt and score the image on a scale of 1 to 5 based on how well it aligned with the prompt.
Using the human-annotated evaluations as the gold standard, the researchers were able to confirm that their auto-eval metric “is better correlated with human ratings than existing metrics for our new dataset.”
The result is a benchmarking system capable of putting numbers to specific factors that make a generated image good or not.
Gecko essentially scores the output image in a way that closely aligns with how we intuitively decide whether or not we’re happy with the generated image.
So what is the best text-to-image model?
In their paper, the researchers concluded that Google’s Muse model beats Stable Diffusion 1.5 and SDXL on the Gecko benchmark. They may be biased but the numbers don’t lie.



