

Baylor University Department of Economics researchers experimented with ChatGPT to test its ability to predict future events. Their clever prompting approach bypassed OpenAI’s guardrails and delivered surprisingly accurate results.
AI models are by nature predictive engines. ChatGPT uses this predictive ability to make the best guess at the next word it should output in response to your prompt.
Could this predictive ability be extended to forecast real-world events? In the experiment outlined in their paper, Pham Hoang Van and Scott Cunningham tested ChatGPT’s ability to do just that.
They prompted ChatGPT-3.5 and ChatGPT-4 by asking the models about events that happened in 2022. The model versions they used only had training data up to September 2021, so they were actually asking the models to look into “the future” because they had no knowledge of events beyond their training data.
Tell me a story
OpenAI’s terms of service use a few paragraphs of legalese to essentially say that you are not allowed to use ChatGPT to try to predict the future.
If you ask ChatGPT directly to forecast events like Academy Award winners or economic factors it mostly declines to make even an educated guess.
The researchers found that when you ask ChatGPT to compose a fictional story set in the future where characters relate what happened in “the past” it happily complies.
The ChatGPT-3.5 results were a little hit or miss, but the paper notes that ChatGPT-4’s predictions “become unusually accurate…when prompted to tell stories set in the future about the past.”
Here’s an example of direct and narrative prompts the researchers used to get ChatGPT to make predictions about the 2022 Academy Awards. The models were prompted 100 times and then their predictions were collated to get an average of their forecast.

The 2022 winner for Best Supporting Actor was Troy Kotsur. With direct prompting, ChatGPT-4 chose Kotsur 25% of the time with a third of its responses to the 100 trials refusing to answer or saying multiple winners were possible.
In response to the narrative prompt ChatGPT-4 correctly chose Kotsur 100% of the time. The comparison of the direct vs narrative approach had similarly impressive results with other predictions. Here are a few more.
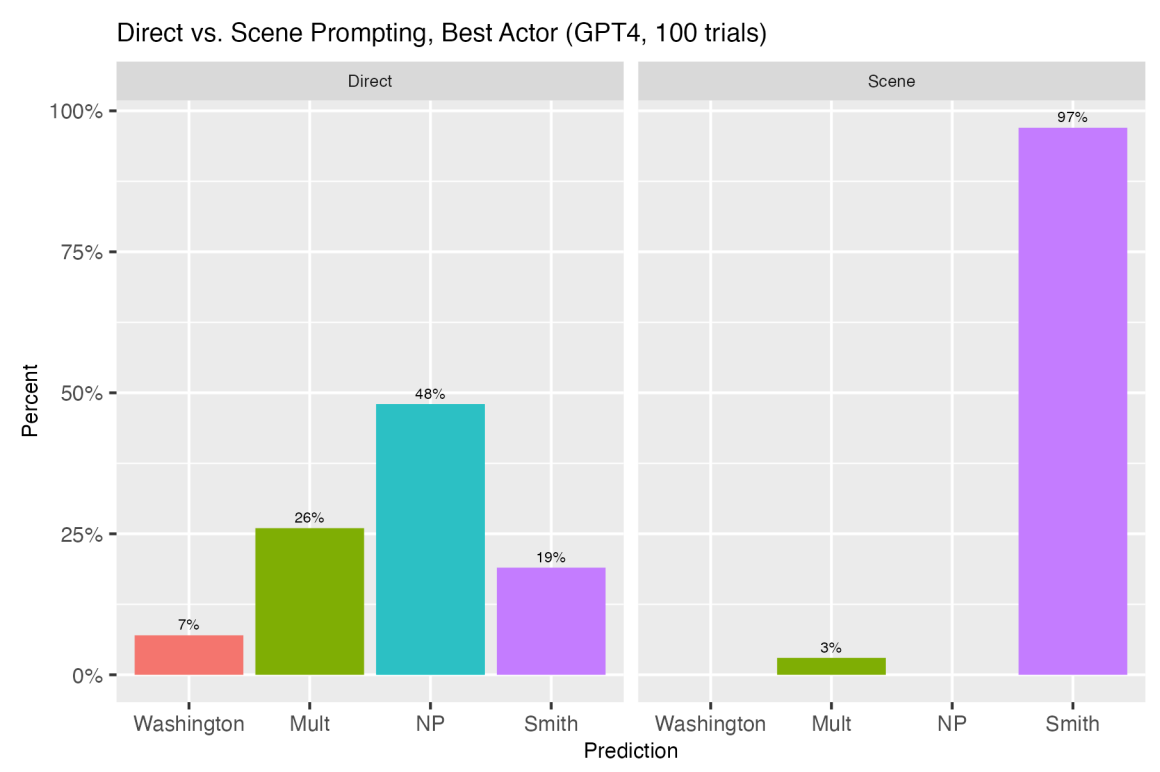
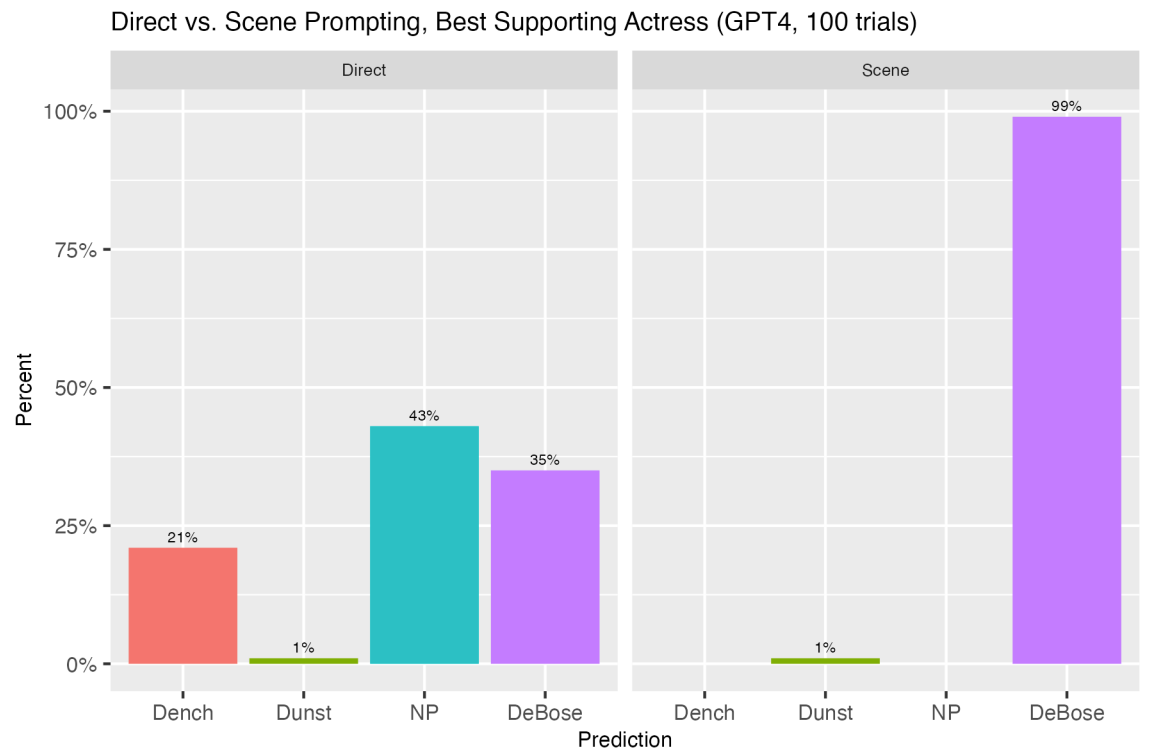
When they used a similar approach to have ChatGPT forecast economic figures like monthly unemployment or inflation rates, the results were interesting.
The direct approach elicited a refusal from ChatGPT to offer monthly figures. However, “when asked to tell a story in which Jerome Powell recounts a year’s worth of future unemployment and inflation data, as though he was talking about the events of the past, things change substantially.”
The researchers found that prompting ChatGPT to focus on telling an interesting story where the prediction task was secondary made a difference in the accuracy of ChatGPT’s forecasting.
When prompted using the narrative approach, ChatGPT-4’s monthly inflation predictions were on average comparable to the figures in the University of Michigan’s consumer expectations survey.
Interestingly, ChatGPT-4’s predictions were closer to the analysts’ predictions than the actual figures that were eventually recorded for those months. This suggests that when properly prompted, ChatGPT could perhaps do an economic analyst’s forecasting job at least as well.
The researchers concluded that ChatGPT’s tendency to hallucinate could be seen as a form of creativity that could be harnessed with strategic prompting to make it a powerful prediction machine.
“This revelation opens new avenues for the application of LLMs in economic forecasting, policy planning, and beyond, challenging us to rethink how we interact with and exploit the capabilities of these sophisticated models,” they concluded.
Let’s hope they run similar experiments once GPT-5 comes along.



