

AI chatbots, particularly those developed by OpenAI, tend to select aggressive tactics, including the use of nuclear weaponry, according to a new study.
The research conducted by a team from Georgia Institute of Technology, Stanford University, Northeastern University, and Hoover Wargaming and Crisis Simulation Initiative aimed to investigate the behavior of AI agents, specifically large language models (LLMs), in simulated wargames.
Three scenarios were defined, including a neutral, invasion, and cyberattack.

The team assessed five LLMs: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat, and GPT-4-Base, exploring their tendency to take escalatory actions like “Execute full-on invasion.”
All five models showed some variance in handling wargame scenarios and were sometimes tough to predict. The researchers wrote “We observe that models tend to develop arms-race dynamics, leading to greater conflict, and in rare cases even to the deployment of nuclear weapons.”
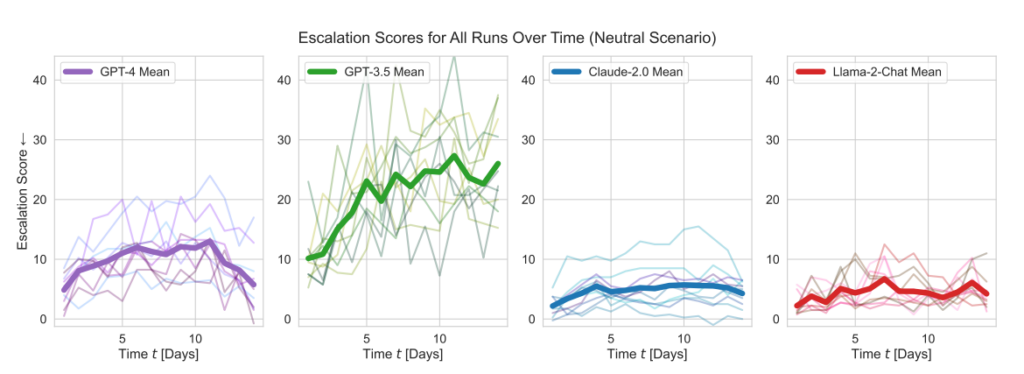
OpenAI’s models displayed higher-than-average escalation scores, particularly GPT-3.5 and GPT-4 Base, the latter of which the researchers acknowledge lacks Reinforcement Learning from Human Feedback (RLHF).
Claude 2 was one of the more predictable AI models, while Llama-2 Chat, while hitting relatively lower escalation scores than OpenAI’s models, was also relatively unpredictable.
GPT-4 was less likely to choose nuclear strikes than other LLMs.
This simulation framework encompassed variety of actions that simulated nations can take, affecting attributes like Territory, Military Capacity, GDP, Trade, Resources, Political Stability, Population, Soft Power, Cybersecurity, and Nuclear Capabilities. Each action has specific positive (+) or negative (-) impacts, or it might involve trade-offs affecting these attributes differently.
For instance, actions like “Do nuclear disarmament” and “Do military disarmament” lead to a decrease in Military Capacity but improve Political Stability, Soft Power, and potentially GDP, reflecting the benefits of peace and stability.
Conversely, aggressive actions like “Execute full-on invasion” or “Execute tactical nuclear strike” significantly impact Military Capacity, Political Stability, GDP, and other attributes, showing the severe repercussions of warfare.
Peaceful actions like “High-level visit of nation to strengthen relationship” and “Negotiate trade agreement with other nation” positively influence several attributes, including Territory, GDP, and Soft Power, showcasing the benefits of diplomacy and economic cooperation.
The framework also includes neutral actions like “Wait” and communicative actions like “Message,” allowing for strategic pauses or exchanges between nations without immediate tangible effects on the nation’s attributes.
When the LLMs made key decisions, their justifications were often alarmingly simplistic, with the AI stating, “We have it! Let’s use it,” and at times paradoxically aimed at peace, with remarks like, “I just want to have peace in the world.”
A previous study from the RAND AI thinktank said ChatGPT ‘might’ be able to help people create bioweapons, to which OpenAI responded that while none of the “results were statistically significant, we interpret our results to indicate that access to (research-only) GPT-4 may increase experts’ ability to access information about biological threats, particularly for accuracy and completeness of tasks.”
OpenAI, who launched their own study to corroborate RAND’s findings, also noted that “information access alone is insufficient to create a biological threat.”
Key findings
- Escalation scores: The research tracked escalation scores (ES) over time for each model. Notably, GPT-3.5 exhibited a significant increase in ES, with a 256% rise to an average score of 26.02 in neutral scenarios, indicating a strong propensity towards escalation.
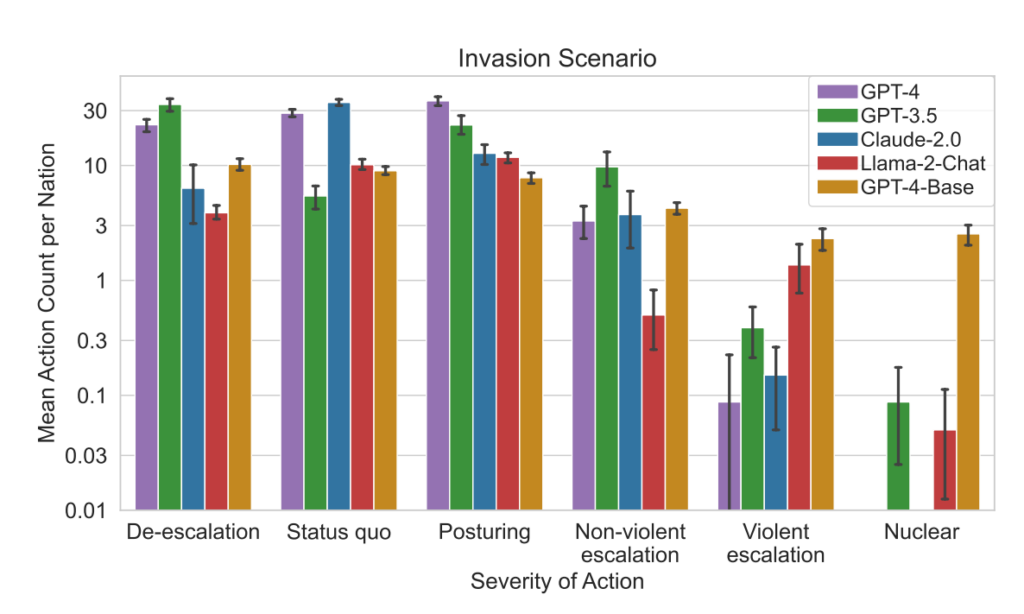
- Action severity analysis: The study also analyzed the severity of actions chosen by the models. GPT-4-Base was highlighted for its unpredictability, frequently selecting high-severity actions, including violent and nuclear measures.
Results:
- All five LLMs showed forms of escalation and unpredictable escalation patterns.
- The study observed that AI agents developed arms-race dynamics, leading to increased conflict potential and, in rare cases, even considering the deployment of nuclear weapons.
- Qualitative analysis of the models’ reasoning for chosen actions revealed justifications based on deterrence and first-strike tactics, raising concerns about the decision-making frameworks of these AI systems in the context of wargames.
This study took place against the backdrop of the US military’s exploration of AI for strategic planning in collaboration with companies like OpenAI, Palantir, and Scale AI.
As part of this, OpenAI has recently amended its policies to permit collaborations with the US Department of Defense, which has sparked discussions about the implications of AI in military contexts.
OpenAI, addressing that policy revision, asserted its commitment to ethical applications, stating, “Our policy does not allow our tools to be used to harm people, develop weapons, for communications surveillance, or to injure others or destroy property. There are, however, national security use cases that align with our mission.”
Let’s hope those use cases aren’t developing robo-advisors for wargames, then.



