

Researchers from UC San Diego and New York University developed V*, an LLM-guided search algorithm that is a lot better than GPT-4V at contextual understanding, and precise targeting of specific visual elements in images.
Multimodal Large Language Models (MLLM) like OpenAI’s GPT-4V blew us away last year with the ability to answer questions about images. As impressive as GPT-4V is, it struggles sometimes when images are very complex and often misses small details.
The V* algorithm uses a Visual Question Answering (VQA) LLM to guide it in identifying which area of the image to focus on to answer a visual query. The researchers call this combination Show, sEArch, and telL (SEAL).
If someone gave you a high-resolution image and asked you a question about it, your logic would guide you to zoom in on an area where you’re most likely to find the item in question. SEAL uses V* to analyze images in a similar way.
A visual search model could simply divide an image into blocks, zoom into each block, and then process it to find the object in question, but that is computationally very inefficient.
When prompted with a textual query about an image, V* first tries to locate the image target directly. If it’s unable to do that it asks the MLLM to use a common sense approach to identify which area of the image the target is most likely to be in.
It then focuses its search just on that area, rather than attempting a “zoomed-in” search of the entire image.

When GPT-4V is prompted to answer questions about an image that requires extensive visual processing of high-res images it struggles. SEAL using V* performs a lot better.

When prompted with “What kind of drink can we buy from that vending machine?” SEAL answered “Coca-Cola” while GPT-4V incorrectly guessed “Pepsi”.
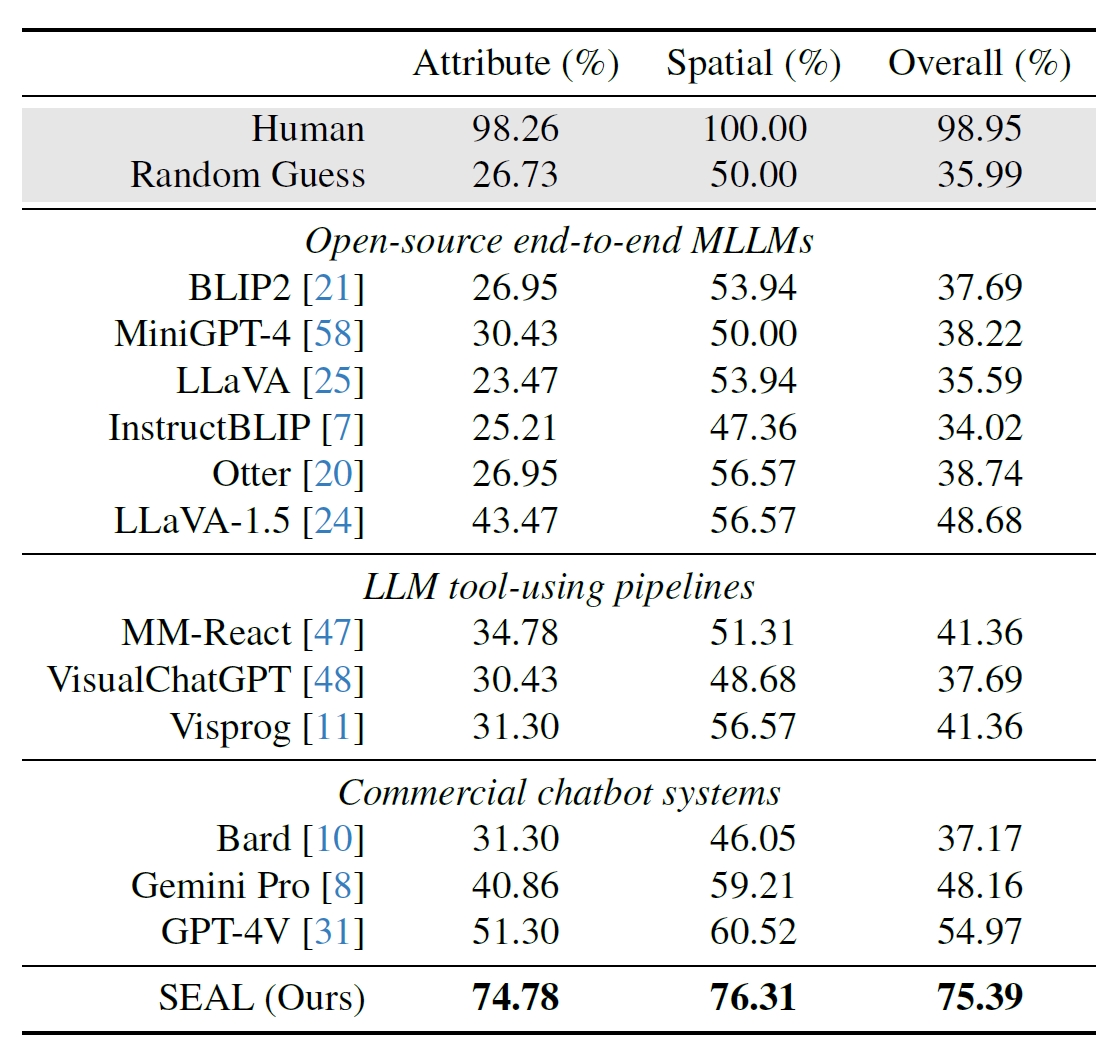
The researchers used 191 high-resolution images from Meta’s Segment Anything (SAM) dataset and created a benchmark to see how SEAL’s performance compared with other models. The V*Bench benchmark tests two tasks: attribute recognition and spatial relationship reasoning.
The figures below show human performance compared with open-source models, commercial ones like GPT-4V, and SEAL. The boost that V* gives in SEAL’s performance is particularly impressive because the underlying MLLM it uses is LLaVa-7b, which is a lot smaller than GPT-4V.
This intuitive approach to analyzing images seems to work really well with a number of impressive examples on the paper’s summary on GitHub.
It will be interesting to see if other MLLMs like those from OpenAI or Google adopt a similar approach.
When asked what beverage was sold from the vending machine in the picture above, Google’s Bard responded, “There is no vending machine in the foreground.” Maybe Gemini Ultra will do a better job.
For now, it looks like SEAL and its novel V* algorithm are ahead of some of the biggest multimodal models by some distance when it comes to visual questioning.



