

When Google announced the release of its Gemini models there was a lot of excitement as the company said these were on par with offerings from OpenAI. That may not be completely true.
Google said that its Gemini Ultra model is better than GPT-4. The model is yet to be released so we’ll have to take their benchmark test results at face value. Gemini Pro has been released and Google says it is on par with GPT-3.5.
Researchers from Carnegie Mellon University and the AI software platform BerriAI put Gemini Pro through a series of tasks to test its language understanding and generation abilities.
They ran the same tests using GPT-3.5 Turbo, GPT-4 Turbo, and Mistral AI’s new Mixtral 8x7B model.
Google’s Gemini recently made waves as a major competitor to OpenAI’s GPT. Exciting! But we wondered:
How good is Gemini really?
At CMU, we performed an impartial, in-depth, and reproducible study comparing Gemini, GPT, and Mixtral.
Paper: https://t.co/S3T7ediQLa
🧵 pic.twitter.com/NmEOeDd8pI— Graham Neubig (@gneubig) December 19, 2023
Results
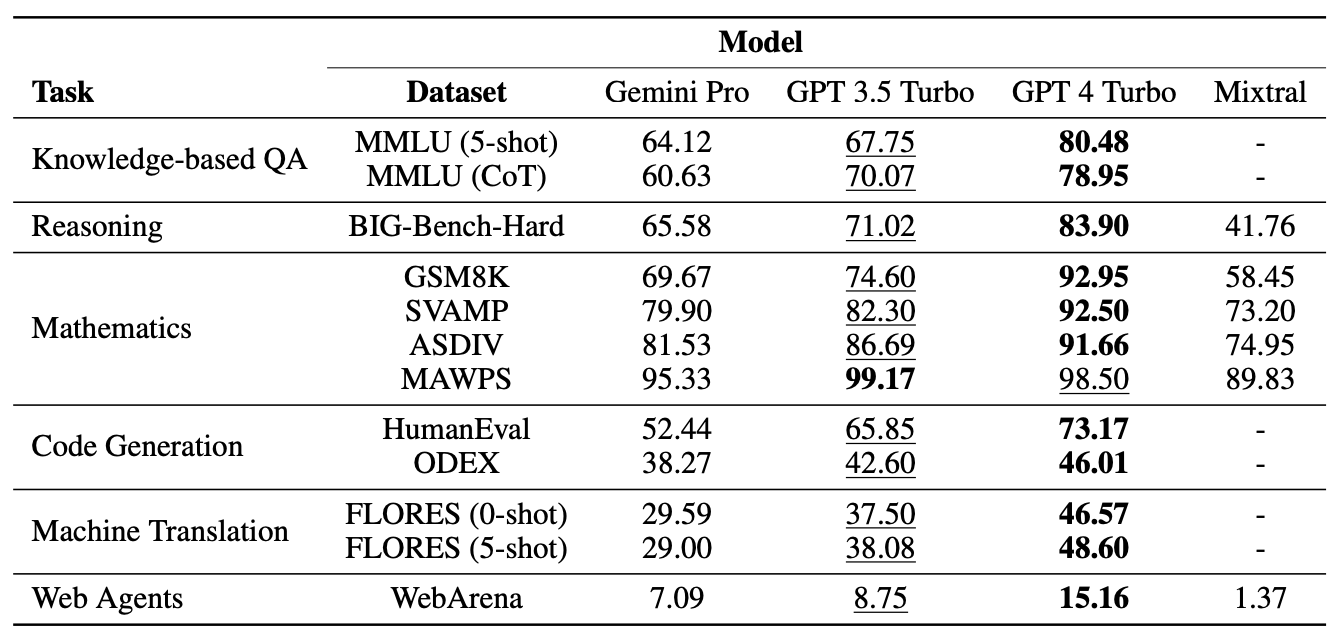
Unsurprisingly, GPT-4 came out on top but Google will be less excited to see how Gemini Pro stacked up against GPT 3.5 Turbo. In a summary of the team’s results, the paper said, “Gemini’s Pro model achieved comparable but slightly inferior accuracy compared to the current version of OpenAI’s GPT 3.5 Turbo.”
Here’s a summary of the results.
The models were prompted using BerriAI’s LiteLLM interface with each model given exactly the same prompts and evaluation protocol.
The models were tested on multiple choice questions, general-purpose reasoning, math reasoning, code generation, language translation, and acting as a web agent.
One of the reasons why Gemini Pro scored poorly in the multiple-choice questions is that it had a strong positional bias. It often chose the answer in position D, whether it was correct or not. Interestingly, this is something that Microsoft’s Medprompt solves with shuffling.
Despite losing out on some of the tests, Gemini Pro did beat GPT-3.5 Turbo in two areas notably, word sorting and symbol manipulation and translation.
In all of the translation tasks Gemini Pro completed, it outperformed all of the other models, including GPT-4. Gemini Pro’s final score on the translation tests came in lower than GPT-3.5 though because it declined to complete some requests when its overzealous content moderation guardrails kicked in.
So what?
Google disputes the figures the researchers came to and insists its figures show that Gemini Pro is on par or better than GPT-3.5. If we allow for the myriad of variables and cut Google some slack, we could split the difference and say that Gemini Pro and GPT-3.5 are pretty much the same.
The key takeaway here is that Gemini Pro, a brand new model that Google spent months developing, doesn’t beat a model that has been out for more than a year and is free to use via ChatGPT.
Gemini Ultra is expected to be released early in 2024. Will it live up to its claim to be better than GPT-4? Let’s hope that Professor Graham Neubig and his team get to run similar benchmarking tests soon.



