

Earlier this month Google proudly announced that its most powerful Gemini model beat GPT-4 on the Massive Multitask Language Understanding MMLU benchmark tests. Microsoft’s new prompting technique sees GPT-4 regain the top spot, albeit by a fraction of a percent.
Besides the drama surrounding its marketing video, Google’s Gemini is a big deal for the company and its MMLU benchmark results are impressive. But Microsoft, OpenAI’s biggest investor, didn’t wait long to throw shade on Google’s efforts.
The headline is that Microsoft got GPT-4 to beat Gemini Ultra’s MMLU results. The reality is that it beat Gemini’s score of 90.04% by just 0.06%.
The backstory of what made this possible is more exciting than the incremental one-upmanship we see on these leaderboards. Microsoft’s new prompting techniques could boost the performance of older AI models.
Remember how Google’s unreleased Gemini Ultra just beat out GPT-4 to become the top AI?
Well, Microsoft just demonstrated that, with proper prompting, GPT-4 actually beats Gemini on the benchmarks.
There is lots of room for gains even with older models. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
— Ethan Mollick (@emollick) December 12, 2023
Medprompt
When you hear people speak about “steering” a model they just mean that with careful prompting you can guide a model to give you an output that is better aligned with what you wanted.
Microsoft developed a combination of prompting techniques that proved to be really good at this. Medprompt started as a project to get GPT-4 to provide better responses on medical challenge benchmarks like MultiMedQA suite of tests.
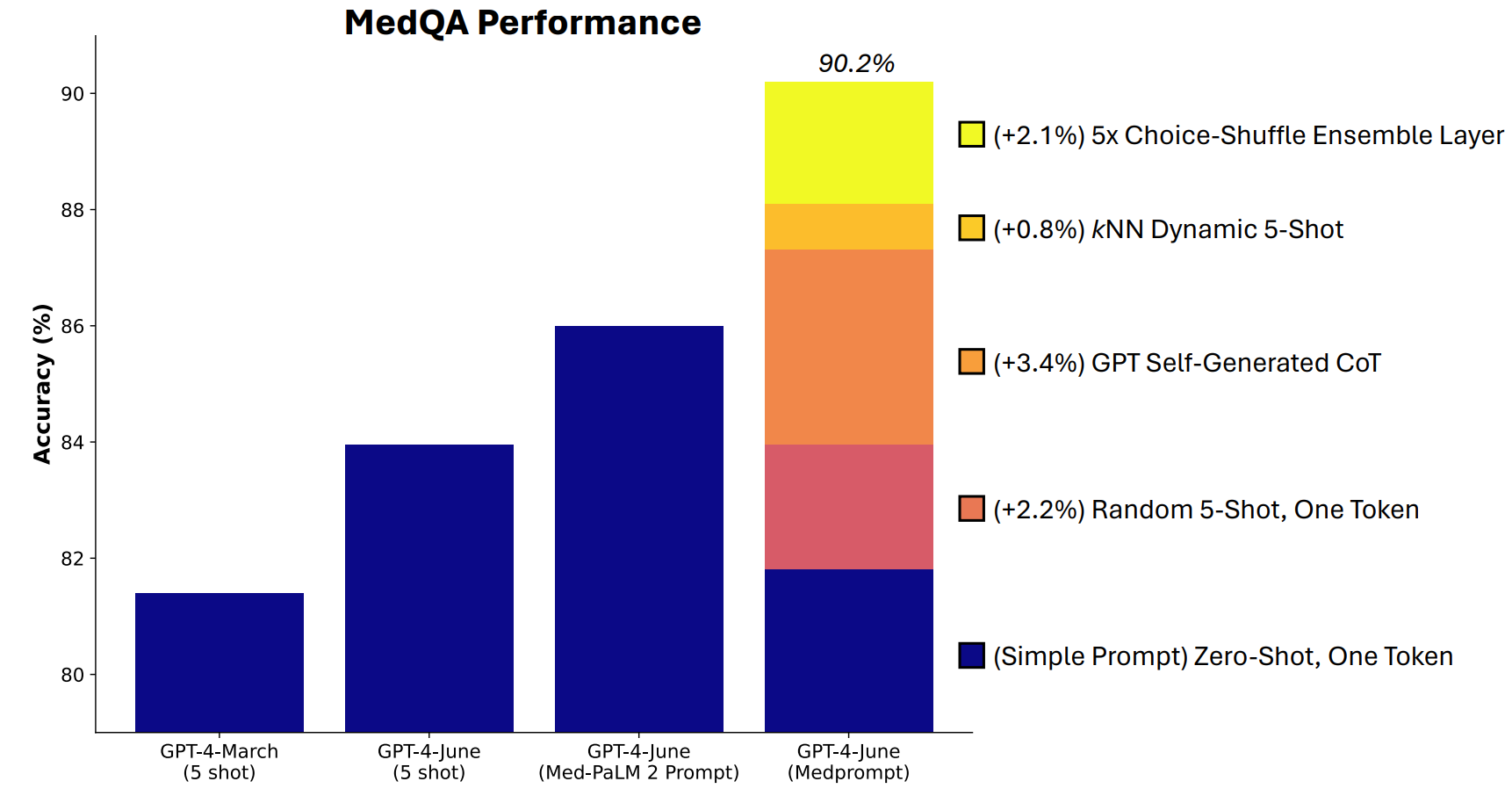
The Microsoft researchers figured that if Medprompt worked well in specialist medical tests, it could improve the generalist performance of GPT-4 too. And hence Microsoft and OpenAI’s regained bragging rights with GPT-4 over Gemini Ultra.
How does Medprompt work?
Medprompt is a combination of clever prompting techniques all rolled into one. It relies on three main techniques.
Dynamic Few-Shot Learning (DFSL)
“Few-shot learning” refers to giving GPT-4 a few examples before asking it to solve a similar problem. When you see a reference like “5-shot” it means the model was provided with 5 examples. “Zero-shot” means it had to answer without any examples.
The Medprompt paper explained that “for simplicity and efficiency, the few-shot examples applied in prompting for a particular task are typically fixed; they are unchanged across test examples.”
The result is that the examples models are presented with are often only broadly relevant or representative.
If your training set is large enough you can get the model to look through all the examples and choose those that are semantically similar to the problem it has to solve. The result is that the few-shot learning examples are more specifically aligned with a particular problem.
Self-Generated Chain of Thought (CoT)
Chain of Thought (CoT) prompting is a great way to steer an LLM. When you prompt it with “think carefully” or “solve it step by step” the results are much improved.
You can get a lot more specific in the way you guide the chain of thought the model should follow but that involves manual prompt engineering.
The researchers found that they “could simply ask GPT-4 to generate chain-of-thought for the training examples.” Their approach basically tells GPT-4, ‘Here’s a question, the answer choices, and the correct answer. What CoT should we include in a prompt that would arrive at this answer?’
Choice Shuffle Ensembling
Most of the MMLU benchmark tests are multiple-choice questions. When an AI model answers these questions it can fall prey to positional bias. In other words, it could favor option B over time even though it isn’t always the right answer.
Choice Shuffle Ensembling shuffles the positions of the answer options and has GPT-4 answer the question again. It does this several times and then the most consistently chosen answer is selected as the final response.
Combining these three prompt techniques is what gave Microsoft the opportunity to throw a little shade on Gemini’s results. It will be interesting to see what results Gemini Ultra would achieve if it used a similar approach.
Medprompt is exciting because it shows that older models can perform even better than we thought if we prompt them in clever ways. The additional processing power needed for these extra steps may not make it a viable approach in most scenarios though.



