

Mistral AI is a French AI startup that is grabbing headlines with its lightweight open-source models. Along with the attention came a new batch of funding as it secured investments of €385m, or $414m, this week.
The company’s second round of funding was led by venture capital firms Andreessen Horowitz and Lightspeed Venture Partners.
The argument over open-source models versus proprietary ones is ongoing and Mistral AI is firmly on the open-source side.
Companies like OpenAI have been criticized for their fearmongering over the safety of open-source models with many saying it’s a case of Big Tech trying to retain its hegemony.
Mistral AI says that by training its own models “releasing them openly, and fostering community contributions, we can build a credible alternative to the emerging AI oligopoly. Open-weight generative models will play a pivotal role in the upcoming AI revolution.”
Several big investors confirmed their confidence in this strategy. The funding Mistral AI secured this week has the company valued at $2 billion. That’s a 7x rise in valuation in the six months since the company launched.
Mixtral 8x7B
September saw the release of Mistral 7B, Mistral AI’s small but powerful LLM that beat or matched bigger open-source models like Meta’s Llama 2 34B.
OpenAI’s GPT proprietary models are rightly held as the gold standard when comparing model performance. With Mistral AI’s new model, Mixtral 8x7B, the company has secured significant bragging rights in this regard.
Mixtral 8x7B is a sparse Mixture-of-Experts model with a 32k context window. Here’s how it performed in benchmark tests compared to Llama 2 and GPT-3.5.
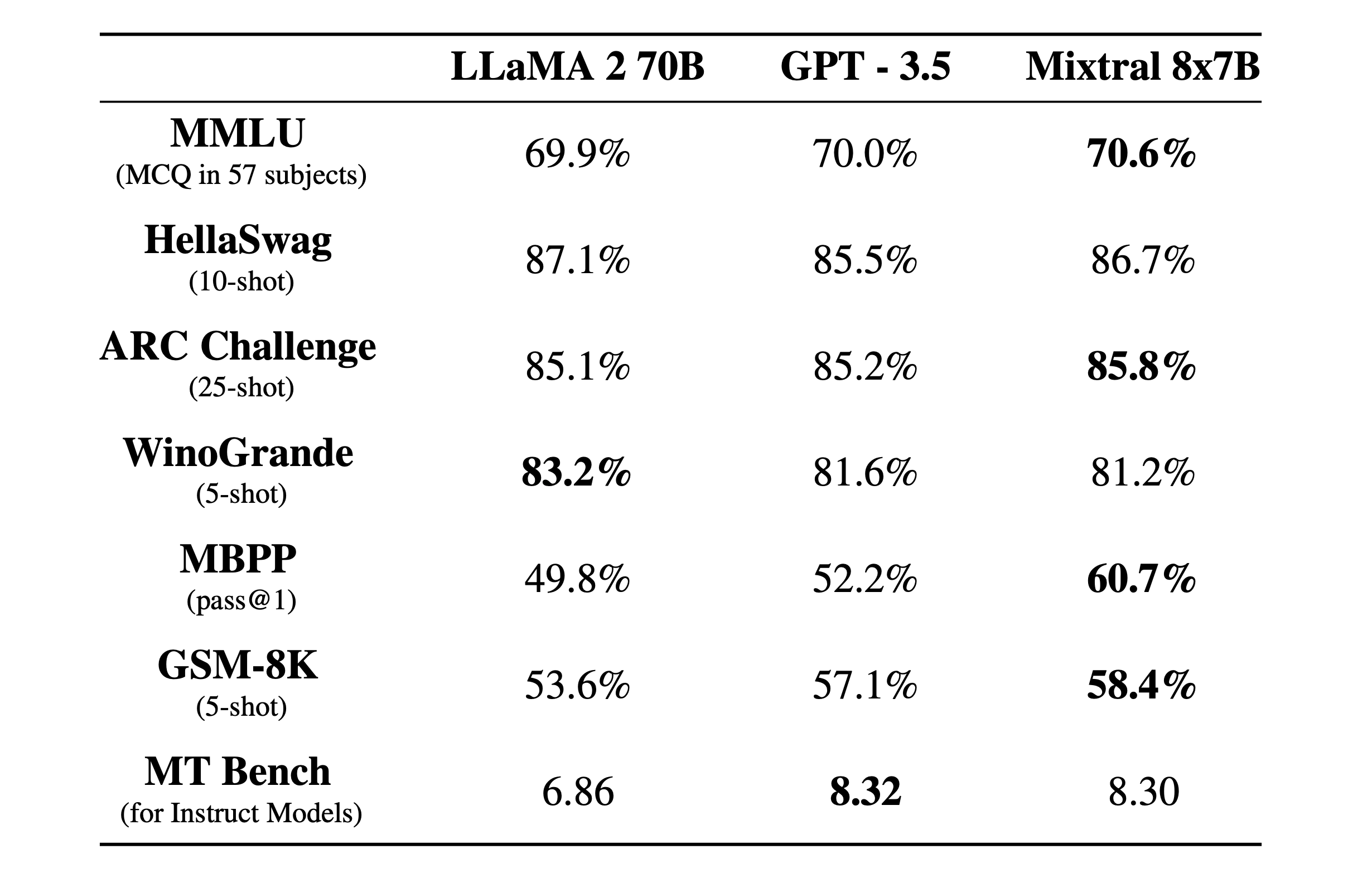
The benchmark tests are a good way to get an idea of how good a model is at performing different functions. The tests above were:
- MMLU (MCQ in 57 subjects): Stands for Multiple-choice Questions in 57 subjects.
- HellaSwag (10-shot): Evaluates the AI’s ability to predict the end of a scenario having been given 10 examples.
- ARC Challenge (25-shot): Tests the AI’s understanding of scientific concepts and reasoning after being given 25 examples to learn from before being tested.
- WinoGrande (5-shot): Tests common sense reasoning based on resolving ambiguities in sentences, with 5 examples for the AI to learn from.
- MBPP (pass@1): Tests an AI model’s ability to generate correct Python code snippets. The pass@1 metric measures the percentage of problems where the model’s first completion was correct.
- GSM-8K (5-shot): The Grade School Math 8K benchmark tests an AI’s ability to solve math word problems at the level expected in grade school having been provided with 5 examples.
- MT Bench (for Instruct Models): Machine Translation Benchmark for Instruct Models measures how well an AI can follow instructions in the context of translation tasks.
What’s even more impressive than the benchmark test results is how small and efficient Mixtral 8x7B is. You could run this model locally on a decent laptop with around 32GB of RAM.
With a lot more money at its disposal, we can expect some exciting developments coming from Mistral AI.



