

The UAE’s Technology Innovation Institute (TII) released its Falcon 180B LLM on Hugging Face last week and it delivered impressive performance in early testing.
The model, which is open access for researchers and commercial users, is the product of a burgeoning AI industry in the Middle East.
Falcon 180B is 2.5 times larger than Meta’s Llama 2 and was trained with 4 times more compute. The TII trained the model on a massive 3.5 trillion tokens. It’s the unique dataset approach that is largely responsible for the model’s impressive performance.
To train a model you don’t just need a lot of data, you typically need a lot of curated, good-quality data. That costs a lot of money to produce and there aren’t a lot of really large curated data sets that are publicly available. TII decided to try a novel approach to avoid the need for curation.
In June researchers used careful filtering and deduplication of publicly available CommonCrawl data to create the RefinedWeb dataset. Not only was this dataset easier to produce, but it delivers better performance than simply using curated corpora, or web data.
Falcon 180B was trained on a massive 3.5 trillion tokens of the RefinedWeb dataset, significantly more than the 2 trillion tokens of Llama 2’s pretraining dataset.
Falcon 180B performance
Falcon 180B tops the Hugging Face leaderboard for open access LLMs. The model outperforms Llama 2, the previous leader, on a number of benchmarks including reasoning, coding, proficiency, and knowledge tests.
Falcon 180B even scores highly when compared with closed source, proprietary models. It ranks just behind GPT-4 and is on par with Google’s PaLM 2 Large, which is twice the size of Falcon 180B.
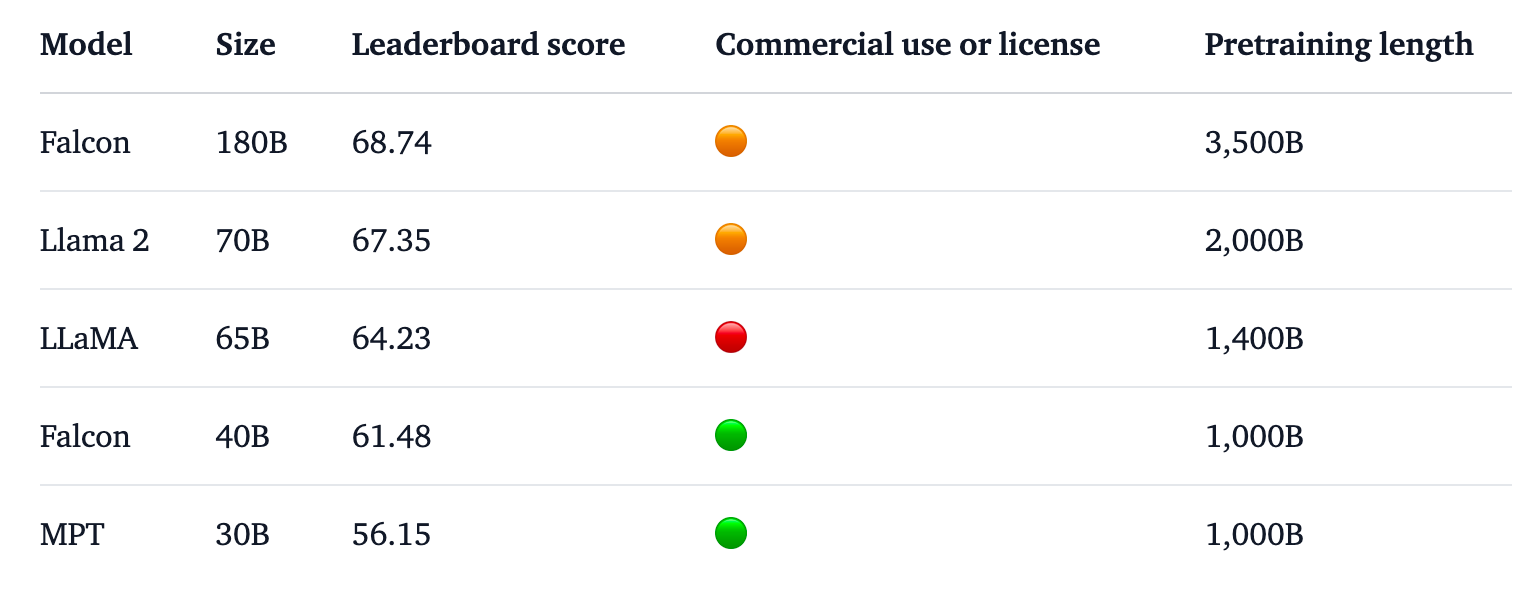
Source: Hugging Face
The TII says that despite the already impressive performance with its pre-trained model, it intends “ to provide increasingly capable versions of Falcon in the future, based on improved datasets and RLHF/RLAIF.”
You can try out a chat version of the model with this Falcon 180B demo on Hugging Face.
The chat version is fine-tuned and sanitized but the base model doesn’t yet have alignment guardrails in place. The TII said that as it hadn’t yet been through a fine-tuning or alignment process it could output “problematic” responses.
It’ll take some time to get it aligned to the point where it can be commercially deployed with confidence.
Even so, the impressive performance of this model highlights the opportunities for improvement beyond simply scaling computing resources.
Falcon 180B shows that smaller models trained on good-quality datasets may be a more cost-effective and efficient direction for AI development.
The release of this impressive model underscores the meteoric growth in AI development in the Middle East, in spite of recent export restrictions of GPUs to the region.
As the likes of TII and Meta continue to release their powerful models under open access licenses, it will be interesting to see what Google and OpenAI do to drive the adoption of their closed models.
The performance gap between open access and proprietary models definitely seems to be closing.



