

Google har släppt två modeller från sin familj av lätta, öppna modeller som kallas Gemma.
Medan Googles Gemini-modeller är proprietära, eller slutna modeller, har Gemma-modellerna släppts som "öppna modeller" och gjorts fritt tillgängliga för utvecklare.
Google släppte Gemma-modeller i två storlekar, 2B- och 7B-parametrar, med förtränade och instruktionsanpassade varianter för var och en. Google släpper modellvikterna samt en uppsättning verktyg för utvecklare som vill anpassa modellerna efter sina behov.
Google säger att Gemma-modellerna byggdes med samma teknik som driver sin flaggskeppsmodell Gemini. Flera företag har släppt 7B-modeller i ett försök att leverera en LLM som behåller användbar funktionalitet samtidigt som den potentiellt körs lokalt istället för i molnet.
Llama-2-7B och Mistral-7B är anmärkningsvärda utmanare i detta utrymme men Google säger att "Gemma överträffar betydligt större modeller på viktiga riktmärken" och erbjöd denna riktmärkesjämförelse som bevis.
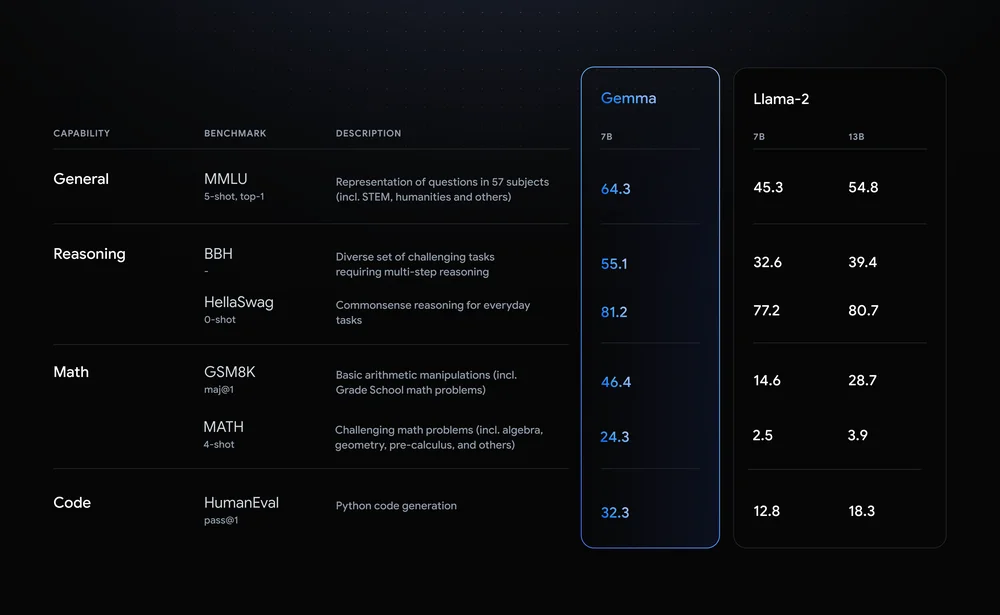
Benchmarkresultaten visar att Gemma till och med slår den större 12B-versionen av Llama 2 i alla fyra funktionerna.
Det som är riktigt spännande med Gemma är möjligheten att köra det lokalt. Google har samarbetat med NVIDIA för att optimera Gemma för NVIDIA GPU:er. Om du har en dator med en av NVIDIA:s RTX GPU:er kan du köra Gemma på din enhet.
NVIDIA säger sig ha en installerad bas på över 100 miljoner NVIDIA RTX GPU:er. Detta gör Gemma till ett attraktivt alternativ för utvecklare som försöker bestämma vilken lättviktsmodell som ska användas som bas för deras produkter.
NVIDIA kommer också att lägga till stöd för Gemma på sin Chatta med RTX plattform som gör det enkelt att köra LLM på RTX-datorer.
Även om det tekniskt sett inte är öppen källkod är det bara användningsbegränsningarna i licensavtalet som hindrar Gemma-modellerna från att äga den etiketten. Kritiker av öppna modeller pekar på riskerna med att hålla dem i linje, men Google säger att det utförde omfattande red-teaming för att säkerställa att Gemma var säker.
Google säger att de använde "omfattande finjustering och förstärkningsinlärning från mänsklig feedback (RLHF) för att anpassa våra instruktionsinställda modeller till ansvarsfulla beteenden." Det släppte också en Responsible Generative AI Toolkit för att hjälpa utvecklare att hålla Gemma inriktad efter finjustering.
Anpassningsbara lättviktsmodeller som Gemma kan erbjuda utvecklare mer nytta än större modeller som GPT-4 eller Gemini Pro. Möjligheten att köra LLM:er lokalt utan kostnaden för molntjänster eller API-samtal blir mer tillgänglig för varje dag.
Med Gemma öppet tillgänglig för utvecklare blir det intressant att se utbudet av AI-drivna applikationer som snart kan köras på våra datorer.



