
Отбор пациентов для поиска подходящих участников клинических испытаний - трудоемкая, дорогостоящая и чреватая ошибками задача, но скоро искусственный интеллект сможет решить эту проблему.
Группа исследователей из Женской больницы Бригама, Гарвардской медицинской школы и отделения персонализированной медицины Mass General Brigham провела исследование, чтобы выяснить, может ли модель искусственного интеллекта обрабатывать медицинские записи для поиска подходящих кандидатов на участие в клинических испытаниях.
Они использовали GPT-4V, LLM от OpenAI с обработкой изображений с помощью технологии Retrieval-Augmented Generation (RAG) для обработки электронных медицинских карт (EHR) и клинических записей потенциальных кандидатов.
LLM предварительно обучаются на фиксированном наборе данных и могут отвечать на вопросы только на основе этих данных. RAG - это техника, позволяющая LLM извлекать данные из внешних источников, таких как Интернет или внутренние документы организации.
Когда участники отбираются для клинического испытания, их пригодность определяется по списку критериев включения и исключения. Обычно для этого обученному персоналу приходится прочесывать электронные истории болезней сотен или тысяч пациентов, чтобы найти тех, кто соответствует критериям.
Исследователи собрали данные исследования, целью которого было привлечение пациентов с симптоматической сердечной недостаточностью. Они использовали эти данные, чтобы проверить, сможет ли GPT-4V с RAG выполнять работу более эффективно, чем это делал персонал исследования, сохраняя при этом точность.
Структурированные данные из электронных медицинских карт потенциальных кандидатов могут быть использованы для определения 5 из 6 критериев включения и 5 из 17 критериев исключения для клинического испытания. Это самая простая часть.
Оставшиеся 13 критериев необходимо было определить, изучив неструктурированные данные в истории болезни каждого пациента, и именно с этой трудоемкой частью, как надеялись исследователи, поможет справиться искусственный интеллект.
Can @Microsoft @Azure @OpenAI's #GPT4 Что лучше, чем человек, подходит для скрининга клинических испытаний? Мы задались этим вопросом в нашем последнем исследовании, и я очень рад поделиться нашими результатами в препринте:https://t.co/lhOPKCcudP
Включение GPT4 в клинические испытания не...- Озан Унлу (@OzanUnluMD) 9 февраля 2024 года
Результаты
Сначала исследователи получили структурированные оценки, выполненные персоналом исследования, и клинические записи за последние два года.
Они разработали рабочий процесс для системы ответов на вопросы на основе клинических заметок, основанной на архитектуре RAG и GPT-4V, и назвали его RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Записи 100 пациентов были использованы в качестве набора данных для разработки, 282 пациента - в качестве набора данных для проверки, а 1894 пациента - в качестве набора данных для тестирования.
Врач-эксперт провел слепой анализ карт пациентов, чтобы ответить на вопросы о соответствии критериям и определить "золотой стандарт" ответов. Затем они сравнивались с ответами персонала исследования и RECTIFIER на основе следующих критериев:
- Чувствительность - способность теста правильно определить пациентов, которые могут участвовать в исследовании (истинные положительные результаты).
- Специфичность - способность теста правильно идентифицировать пациентов, не подходящих для участия в исследовании (истинно отрицательные результаты).
- Точность - общая доля правильных классификаций (как истинно положительных, так и истинно отрицательных).
- Коэффициент корреляции Мэтьюса (MCC) - метрика, используемая для измерения того, насколько хорошо модель выбирает или исключает человека. Значение 0 равно подбрасыванию монеты, а 1 означает, что модель правильно выбирает в 100% случаев.
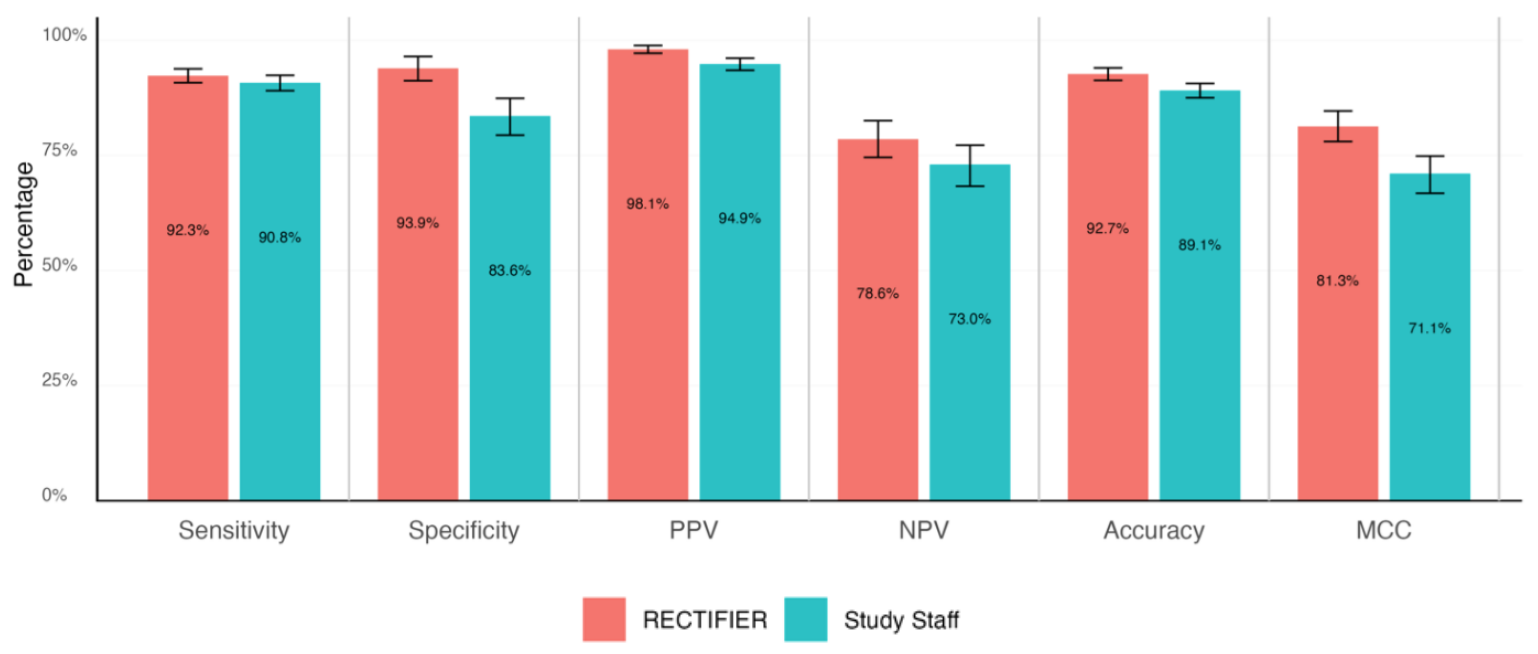
RECTIFIER показал себя не хуже, а в некоторых случаях и лучше, чем сотрудники, участвовавшие в исследовании. Вероятно, самым значительным результатом исследования стало сравнение стоимости.
Хотя данные о вознаграждении персонала исследования не приводятся, оно должно было быть значительно больше, чем стоимость использования GPT-4V, которая варьировалась от $0,02 до $0,10 на пациента. Использование искусственного интеллекта для оценки пула из 1000 потенциальных кандидатов заняло бы несколько минут и стоило бы около $100.
Исследователи пришли к выводу, что использование модели искусственного интеллекта, подобной GPT-4V с RAG, позволяет сохранить или повысить точность определения кандидатов на участие в клинических испытаниях, причем сделать это более эффективно и гораздо дешевле, чем с помощью человеческого персонала.
Они отметили необходимость осторожности при передаче медицинского обслуживания автоматизированным системам, но, похоже, что при правильном управлении ИИ справится с этой задачей лучше, чем мы.



