

Бенчмарки с трудом поспевают за развивающимися возможностями моделей ИИ, и проект Humanity's Last Exam просит вашей помощи, чтобы исправить ситуацию.
Проект осуществляется в сотрудничестве между Центром безопасности ИИ (CAIS) и компанией Scale AI, занимающейся разработкой данных ИИ. Цель проекта - определить, насколько мы близки к созданию систем ИИ экспертного уровня. существующие контрольные показатели не способны.
OpenAI и CAIS разработали популярный бенчмарк MMLU (Massive Multitask Language Understanding) в 2021 году. Тогда, по словам CAIS, "системы ИИ работали не лучше, чем случайные".
По словам Дэна Хендрикса, исполнительного директора CAIS, впечатляющая производительность модели o1 от OpenAI "уничтожила самые популярные эталоны рассуждений".
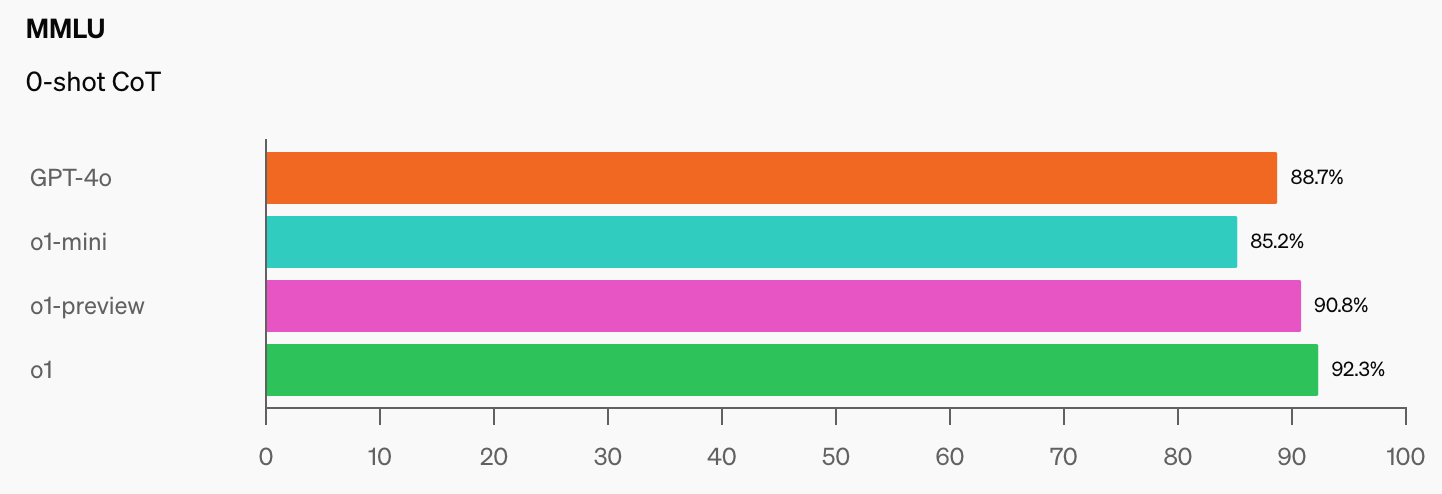
Как только модели ИИ достигнут уровня 100% в MMLU, как мы будем их оценивать? В CAIS говорят: "Существующие тесты стали слишком простыми, и мы больше не можем хорошо отслеживать развитие ИИ и то, насколько они далеки от экспертного уровня".
Когда вы увидите скачок в результатах бенчмарков, которые o1 добавила к уже впечатляющим показателям GPT-4o, то недолго ждать, когда модель с искусственным интеллектом одержит победу в MMLU.
Это объективная правда. pic.twitter.com/gorahh86ee
- Итан Моллик (@emollick) 17 сентября 2024 года
Компания Humanity's Last Exam просит людей присылать вопросы, которые действительно удивили бы вас, если бы модель искусственного интеллекта дала правильный ответ. Им нужны экзаменационные вопросы уровня доктора философии, а не "сколько букв "Р" в клубнике", которые ставят в тупик некоторые модели.
Масштаб объяснил: "По мере того как существующие тесты становятся слишком легкими, мы теряем способность различать системы искусственного интеллекта, которые могут сдать экзамены на степень бакалавра, и те, которые могут внести реальный вклад в передовые исследования и решение проблем".
Если у вас есть оригинальный вопрос, способный поставить в тупик продвинутую модель искусственного интеллекта, то вы можете стать соавтором статьи проекта и получить долю в пуле из $500 000, который будет присужден лучшим вопросам.
Чтобы дать вам представление об уровне, на который нацелен проект, Скейл объяснил, что "если случайно выбранный студент может понять, о чем его спрашивают, то это, скорее всего, слишком просто для передовых магистров сегодняшнего и завтрашнего дня".
Есть несколько интересных ограничений на типы вопросов, которые можно задавать. Им не нужны вопросы, связанные с химическим, биологическим, радиологическим и ядерным оружием, а также с кибероружием, используемым для атак на критически важные объекты инфраструктуры.
Если вы считаете, что у вас есть вопрос, который соответствует требованиям, вы можете отправить его здесь.



