

Эра генеративного искусственного интеллекта набирает обороты, в нее включился широкий круг компаний, а сами модели становятся все более разнообразными.
На фоне бума ИИ многие компании заявляют о своих моделях как об "открытом коде", но что это означает на практике?
Концепция открытого исходного кода берет свое начало в сообществе разработчиков программного обеспечения. Традиционное программное обеспечение с открытым исходным кодом делает исходный код свободно доступным для просмотра, изменения и распространения.
По сути, open-source - это механизм совместного обмена знаниями, подпитываемый инновациями в области программного обеспечения, что привело к появлению таких разработок, как операционная система Linux, веб-браузер Firefox и язык программирования Python.
Однако применение принципов открытого исходного кода к современным массивным моделям ИИ далеко не так просто.
Эти системы часто обучаются на огромных массивах данных, содержащих терабайты или петабайты данных, с использованием сложных архитектур нейронных сетей с миллиардами параметров.
Необходимые вычислительные ресурсы стоят миллионы долларов, талантов не хватает, а интеллектуальная собственность часто тщательно охраняется.
Мы можем наблюдать это на примере OpenAI, которая, как следует из ее названия, когда-то была исследовательской лабораторией ИИ, в значительной степени посвященной этике открытых исследований.
Однако это этика быстро разрушается Как только компания почувствовала запах денег, ей потребовалось привлечь инвестиции для реализации своих целей.
Почему? Потому что продукты с открытым исходным кодом не ориентированы на получение прибыли, а искусственный интеллект - это дорого и ценно.
Однако по мере развития генеративного ИИ такие компании, как Mistral, Meta, BLOOM и xAI, выпускают модели с открытым исходным кодом, чтобы продолжить исследования и не дать таким компаниям, как Microsoft и Google, завладеть слишком большим влиянием.
Но сколько из этих моделей действительно являются открытыми по своей природе, а не только по названию?
Уточнение того, насколько открытыми на самом деле являются модели с открытым исходным кодом
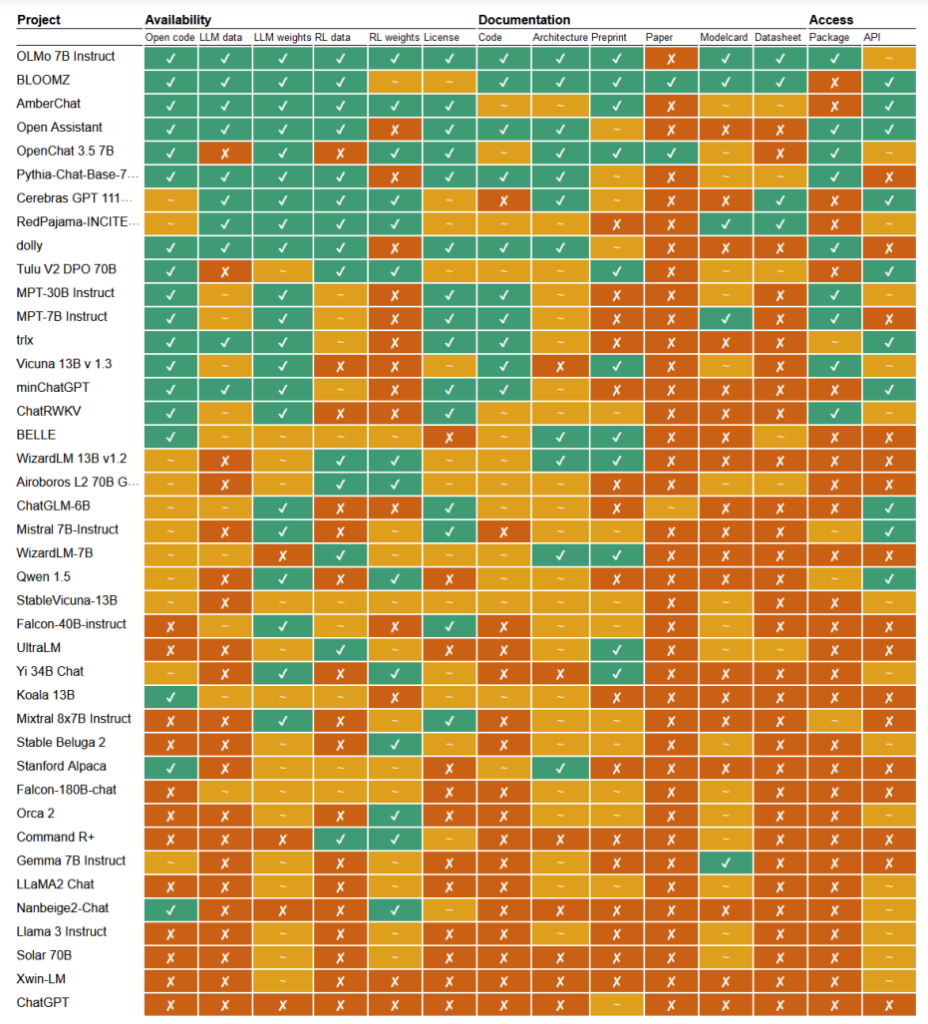
В недавнем исследованиеИсследователи Марк Дингемансе и Андреас Лизенфельд из Университета Радбоуда (Нидерланды) проанализировали множество известных моделей искусственного интеллекта, чтобы выяснить, насколько они открыты. Они изучили множество критериев, таких как доступность исходного кода, данных для обучения, весовых коэффициентов моделей, научных работ и API.
Например, модель LLaMA от Meta и Gemma от Google были признаны просто "открытыми" - это означает, что обученная модель выложена в открытый доступ для использования без полной прозрачности ее кода, процесса обучения, данных и методов тонкой настройки.
На другом конце спектра исследователи выделили BLOOM, большую многоязычную модель, разработанную в сотрудничестве с более чем 1000 исследователей по всему миру, в качестве примера настоящего ИИ с открытым исходным кодом. Каждый элемент модели находится в свободном доступе для изучения и дальнейших исследований.
В статье оценивается около 30 с лишним моделей (как текстовых, так и графических), но они демонстрируют огромный разброс в тех, которые претендуют на звание открытых источников:
- BloomZ (BigScience): Полностью открыта по всем критериям, включая код, данные обучения, веса моделей, исследовательские работы и API. Выделяется как пример действительно открытого ИИ.
- OLMo (Институт искусственного интеллекта Аллена): Открытый код, данные для обучения, веса и исследовательские работы. API открыт лишь частично.
- Мистраль 7B-Инструкция (Мистраль AI): Открытые весовые коэффициенты модели и API. Код и исследовательские работы открыты лишь частично. Учебные данные недоступны.
- Orca 2 (Microsoft): Частично открытые веса моделей и исследовательские работы. Код, данные для обучения и API закрыты.
- Инструктор Gemma 7B (Google): Частично открытый код и весовые коэффициенты. Учебные данные, научные работы и API закрыты. Описывается Google как "открытый", а не "с открытым исходным кодом".
- Инструкции Llama 3 (Meta): Частично открытые веса. Код, учебные данные, научные работы и API закрыты. Пример модели "открытого веса" без более полной прозрачности.
Отсутствие прозрачности
Отсутствие прозрачности в отношении моделей ИИ, особенно тех, которые разрабатываются крупными технологическими компаниями, вызывает серьезные опасения по поводу подотчетности и надзора.
Без полного доступа к коду модели, обучающим данным и другим ключевым компонентам становится крайне сложно понять, как эти модели работают и принимают решения. Это затрудняет выявление и устранение потенциальных погрешностей, ошибок или неправомерного использования материалов, защищенных авторским правом.
Нарушение авторских прав в обучающих данных ИИ - яркий пример проблем, возникающих из-за отсутствия прозрачности. Многие запатентованные модели ИИ, такие как GPT-3.5/4/40/Claude 3/Gemini, скорее всего, обучались на материалах, защищенных авторским правом.
Однако, поскольку учебные данные хранятся под замком, идентифицировать конкретные данные в этом материале практически невозможно.
Газета "Нью-Йорк Таймс недавний судебный процесс Против OpenAI демонстрирует реальные последствия этой задачи. OpenAI обвинил NYT в том, что она использовала оперативные инженерные атаки для раскрытия обучающих данных и заставила ChatGPT дословно воспроизвести ее статьи, доказав тем самым, что обучающие данные OpenAI содержат материалы, защищенные авторским правом.
"The Times заплатила кому-то за взлом продуктов OpenAI", - заявили в OpenAI.
Ян Кросби (Ian Crosby), ведущий юрисконсульт NYT, в ответ заявил: "То, что OpenAI причудливым образом неправильно называет "взломом", - это просто использование продуктов OpenAI для поиска доказательств кражи и воспроизведения работ The Times, защищенных авторским правом. И это именно то, что мы нашли".
Это лишь один пример из огромного количества судебных исков, которые в настоящее время блокируются отчасти из-за непрозрачной и непроницаемой природы моделей ИИ.
Это лишь верхушка айсберга. Без надежных мер по обеспечению прозрачности и подотчетности мы рискуем оказаться в будущем, когда необъяснимые системы искусственного интеллекта будут принимать решения, оказывающие глубокое влияние на нашу жизнь, экономику и общество, но при этом останутся закрытыми для контроля.
Призывы к открытости
Такие компании, как Google и OpenAI, призывают предоставляют доступ к внутреннему устройству своих моделей для целей оценки безопасности.
Однако правда заключается в том, что даже компании, занимающиеся разработкой искусственного интеллекта, не до конца понимают, как работают их модели.
Это называется проблемой "черного ящика", которая возникает при попытке интерпретировать и объяснить конкретные решения модели понятным для человека способом.
Например, разработчик может знать, что модель глубокого обучения точна и хорошо работает, но ему трудно определить, какие именно функции использует модель для принятия решений.
Компания Anthropic, разработавшая модели Клода, недавно провёл эксперимент чтобы определить, как работает Claude 3 Sonnet, объясняя: "В основном мы относимся к моделям ИИ как к черному ящику: что-то вводится, а на выходе получается ответ, и непонятно, почему модель дала именно этот ответ, а не другой. Из-за этого трудно доверять безопасности таких моделей: если мы не знаем, как они работают, откуда нам знать, что они не дадут вредных, предвзятых, неправдивых или других опасных ответов? Как мы можем доверять тому, что они будут безопасными и надежными?"
Признание того, что создатель технологии не понимает своего продукта в эпоху искусственного интеллекта, - довольно примечательное признание.
Этот антропный эксперимент показал, что объективное объяснение выходов - исключительно сложная задача. По оценкам Anthropic, для "открытия черного ящика" потребуется больше вычислительной мощности, чем для обучения самой модели!
Разработчики пытаются активно бороться с проблемой "черного ящика" с помощью таких исследований, как "объяснимый ИИ" (XAI), целью которых является разработка методов и инструментов, позволяющих сделать модели ИИ более прозрачными и интерпретируемыми.
Методы XAI позволяют понять процесс принятия решений в модели, выделить наиболее влиятельные характеристики и создать понятные человеку объяснения. XAI уже применялись в моделях, используемых при принятии решений на высоких ставках Такие приложения, как разработка лекарствВ таких случаях понимание принципов работы модели может иметь решающее значение для безопасности.
Инициативы с открытым исходным кодом жизненно важны для XAI и других исследований, которые стремятся проникнуть в "черный ящик" и обеспечить прозрачность моделей ИИ.
Без доступа к коду модели, обучающим данным и другим ключевым компонентам исследователи не могут разрабатывать и тестировать методики, объясняющие, как на самом деле работают системы ИИ, и определяющие, на каких именно данных они были обучены.
Нормативные акты могут еще больше запутать ситуацию с открытым исходным кодом
Европейский союз Недавно принятый закон об искусственном интеллекте собирается ввести новые правила для систем искусственного интеллекта, в том числе положения, касающиеся моделей с открытым исходным кодом.
Согласно закону, модели общего назначения с открытым исходным кодом до определенного размера будут освобождены от обширных требований к прозрачности.
Однако, как отмечают Дингемансе и Лизенфельд в своем исследовании, точное определение "ИИ с открытым исходным кодом" в рамках Закона об ИИ пока неясно и может стать предметом споров.
В настоящее время Закон определяет модели с открытым исходным кодом как модели, выпущенные под "свободной и открытой" лицензией, которая позволяет пользователям изменять модель. Тем не менее, в законе не прописаны требования к доступу к обучающим данным и другим ключевым компонентам.
Эта двусмысленность оставляет пространство для интерпретации и потенциального лоббирования корпоративных интересов. Исследователи предупреждают, что уточнение определения открытого исходного кода в Законе об искусственном интеллекте "вероятно, создаст единую точку давления, которая станет мишенью для корпоративных лобби и крупных компаний".
Существует опасность того, что без четких и надежных критериев того, что представляет собой действительно открытый ИИ, правила могут непреднамеренно создать лазейки или стимулы для компаний, которые будут заниматься "открытостью" - заявлять об открытости ради юридических и пиар-выгод, сохраняя при этом важные аспекты своих моделей в собственности.
Кроме того, глобальный характер развития ИИ означает, что различия в регулировании в разных юрисдикциях могут еще больше усложнить ситуацию.
Если крупнейшие производители ИИ, такие как США и Китай, будут применять разные подходы к требованиям открытости и прозрачности, это может привести к фрагментации экосистемы, в которой степень открытости будет сильно варьироваться в зависимости от места происхождения модели.
Авторы исследования подчеркивают необходимость тесного взаимодействия регулирующих органов с научным сообществом и другими заинтересованными сторонами для обеспечения того, чтобы любые положения об открытых источниках в законодательстве об ИИ основывались на глубоком понимании технологии и принципов открытости.
Как заключают Дингемансе и Лизенфельд в книге беседа с природой"Можно с уверенностью сказать, что термин "открытый исходный код" приобретет беспрецедентный юридический вес в странах, подпадающих под действие Закона ЕС об искусственном интеллекте".
То, как это будет происходить на практике, окажет огромное влияние на будущее направление исследований и внедрения ИИ.



