

Исследователи Google DeepMind разработали NATURAL PLAN - эталон для оценки возможностей LLM по планированию реальных задач на основе подсказок естественного языка.
Следующая эволюция ИИ - это выход за пределы чат-платформы и выполнение агентских функций для выполнения задач на разных платформах от нашего имени. Но это сложнее, чем кажется.
Планирование таких задач, как назначение встречи или составление маршрута на отпуск, может показаться нам простым делом. Люди умеют просчитывать множество шагов и предсказывать, достигнет ли тот или иной ход действий поставленной цели или нет.
Вам это может показаться простым, но даже лучшие модели ИИ испытывают трудности с планированием. Можем ли мы сравнить их, чтобы узнать, какой LLM лучше всего справляется с планированием?
Эталон NATURAL PLAN тестирует LLM на 3 задачи планирования:
- Планирование поездки - Планирование маршрута поездки с учетом ограничений по перелету и пункту назначения
- Планирование встреч - Планирование встреч с несколькими друзьями в разных местах
- Календарное планирование - Планирование рабочих встреч между несколькими людьми с учетом существующих графиков и различных ограничений
Эксперимент начался с подсказок в несколько кадров, где моделям было предоставлено 5 примеров подсказок и соответствующих правильных ответов. Затем им были предложены подсказки по планированию различной сложности.
Вот пример подсказки и решения, предоставленного в качестве примера для моделей:

Результаты
Исследователи протестировали GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, и Gemini 1.5 ProНи один из них не показал хороших результатов в этих тестах.
В офисе DeepMind, должно быть, не остались равнодушными к результатам, поскольку Gemini 1.5 Pro заняла первое место.

Как и ожидалось, результаты ухудшались в геометрической прогрессии при выполнении более сложных заданий, в которых увеличивалось количество людей или городов. Например, посмотрите, как быстро ухудшается точность при добавлении большего количества людей в тест на планирование встречи.
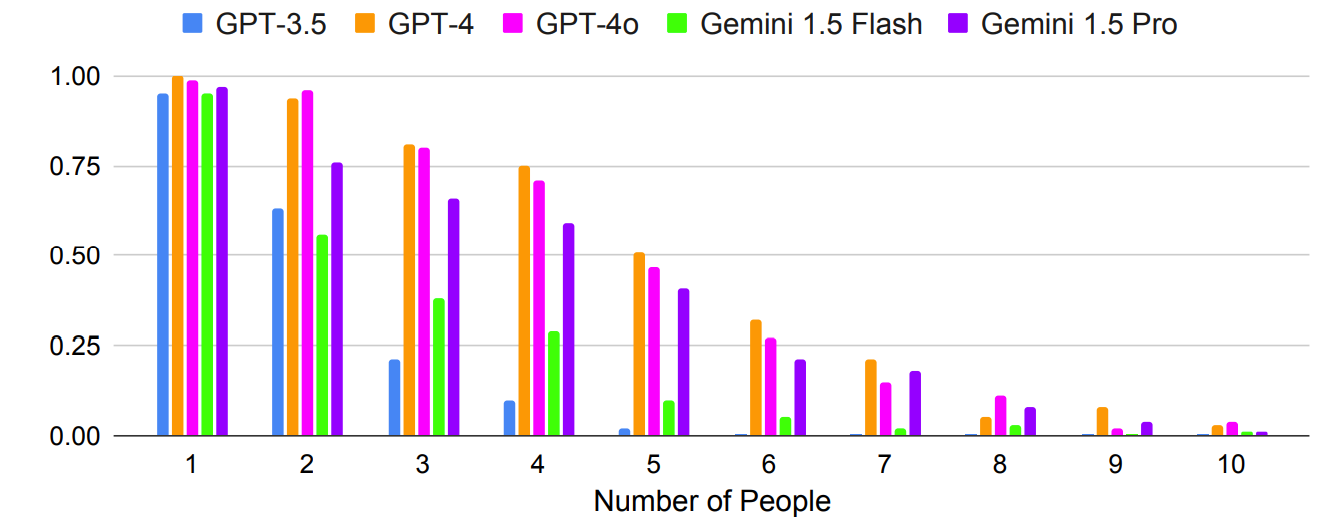
Может ли многокадровая подсказка привести к повышению точности? Результаты исследования показывают, что может, но только если модель имеет достаточно большое контекстное окно.
Увеличенное контекстное окно Gemini 1.5 Pro позволяет использовать больше контекстных примеров, чем в моделях GPT.
Исследователи обнаружили, что при планировании поездок увеличение количества выстрелов с 1 до 800 повышает точность Gemini Pro 1.5 с 2,7% до 39,9%.
Газета отметили: "Эти результаты показывают перспективность внутриконтекстного планирования, когда возможности длинного контекста позволяют LLM использовать дополнительный контекст для улучшения планирования".
Странным результатом стало то, что GPT-4o очень плохо справлялся с планированием поездок. Исследователи обнаружили, что он с трудом "понимает и соблюдает ограничения, связанные со стыковкой рейсов и датой поездки".
Еще одним странным результатом стало то, что самокоррекция привела к значительному снижению производительности модели во всех моделях. Когда моделям предлагалось проверить свою работу и внести исправления, они допускали больше ошибок.
Интересно, что более сильные модели, такие как GPT-4 и Gemini 1.5 Pro, при самокоррекции несли большие потери, чем GPT-3.5.
Агентный ИИ - это захватывающая перспектива, и мы уже видим некоторые практические примеры его использования в Microsoft Copilot агенты.
Но результаты эталонных тестов NATURAL PLAN показывают, что нам еще предстоит пройти определенный путь, прежде чем ИИ сможет справиться с более сложным планированием.
Исследователи DeepMind пришли к выводу, что "NATURAL PLAN очень сложно решить для современных моделей".
Похоже, что ИИ еще не скоро заменит туристических агентов и персональных помощников.



