

Anthropic Исследователи успешно определили миллионы концепций в Claude Сонет, один из их продвинутых магистров.
Модели ИИ часто считаются "черными ящиками", то есть вы не можете "заглянуть" в них, чтобы понять, как именно они работают.
Когда вы предоставляете LLM входные данные, он генерирует ответ, но причины его выбора непонятны.
Вы вводите данные, а на выходе получаете результат - и даже сами разработчики ИИ не понимают, что происходит внутри этой "коробки".
Нейронные сети создают свои собственные внутренние представления информации, когда они сопоставляют входные и выходные данные в процессе обучения. Строительные блоки этого процесса, называемые "активациями нейронов", представлены в виде числовых значений.
Каждое понятие распределено по нескольким нейронам, и каждый нейрон участвует в представлении нескольких понятий, что затрудняет непосредственное сопоставление понятий с отдельными нейронами.
Это в значительной степени аналогично нашему человеческому мозгу. Точно так же, как наш мозг обрабатывает сенсорные сигналы и генерирует мысли, поведение и воспоминания, миллиарды и даже триллионы процессов, лежащих в основе этих функций, остаются в основном неизвестными науке.
Anthropicисследование пытается заглянуть в "черный ящик" ИИ с помощью техники, называемой "обучение по словарю".
Это предполагает декомпозицию сложных паттернов в модели ИИ на линейные строительные блоки или "атомы", которые интуитивно понятны человеку.
Сопоставление LLM с помощью обучения по словарям
В октябре 2023 года, Anthropic Применив этот метод к крошечной "игрушечной" языковой модели, они обнаружили связные признаки, соответствующие таким понятиям, как текст в верхнем регистре, последовательности ДНК, фамилии в цитатах, математические существительные или аргументы функций в коде Python.
В последнем исследовании эта методика расширена до масштабов, позволяющих работать с современными более крупными языковыми моделями ИИ, в данном случае, Anthropic's Claude 3 Сонет.
Вот пошаговое описание того, как проходило исследование:
Выявление закономерностей с помощью обучения по словарям
Anthropic В ходе изучения словарей они анализировали активации нейронов в различных контекстах и выявляли общие закономерности.
Обучение по словарю группирует эти активации в меньший набор значимых "признаков", представляющих концепции более высокого уровня, изучаемые моделью.
Выявив эти особенности, исследователи смогут лучше понять, как модель обрабатывает и представляет информацию.
Извлечение признаков из среднего слоя
Исследователи сосредоточились на среднем слое Claude 3.0 Sonnet, который служит критической точкой в конвейере обработки модели.
Применение словарного обучения к этому слою извлекает миллионы признаков, которые отражают внутренние представления модели и изученные концепции на этом этапе.
Извлечение характеристик из среднего слоя позволяет исследователям изучить понимание моделью информации после он обработал входные данные до генерирование конечного результата.
Открытие разнообразных и абстрактных понятий
Извлеченные характеристики показали широкий спектр концепций, изученных ClaudeОт конкретных сущностей, таких как города и люди, до абстрактных понятий, связанных с научными областями и синтаксисом программирования.
Интересно, что признаки оказались мультимодальными, реагируя как на текстовые, так и на визуальные сигналы, что говорит о том, что модель может изучать и представлять концепции в различных модальностях.
Кроме того, многоязычные характеристики свидетельствуют о том, что модель способна воспринимать понятия, выраженные на разных языках.

Анализ организации концепций
Чтобы понять, как модель организует и связывает различные понятия, исследователи проанализировали сходство между признаками на основе их паттернов активации.
Они обнаружили, что признаки, представляющие связанные понятия, имеют тенденцию объединяться в кластеры. Например, признаки, связанные с городами или научными дисциплинами, имеют большее сходство друг с другом, чем с признаками, представляющими несвязанные понятия.
Это говорит о том, что внутренняя организация концептов в модели в определенной степени соответствует человеческой интуиции в отношении концептуальных отношений.
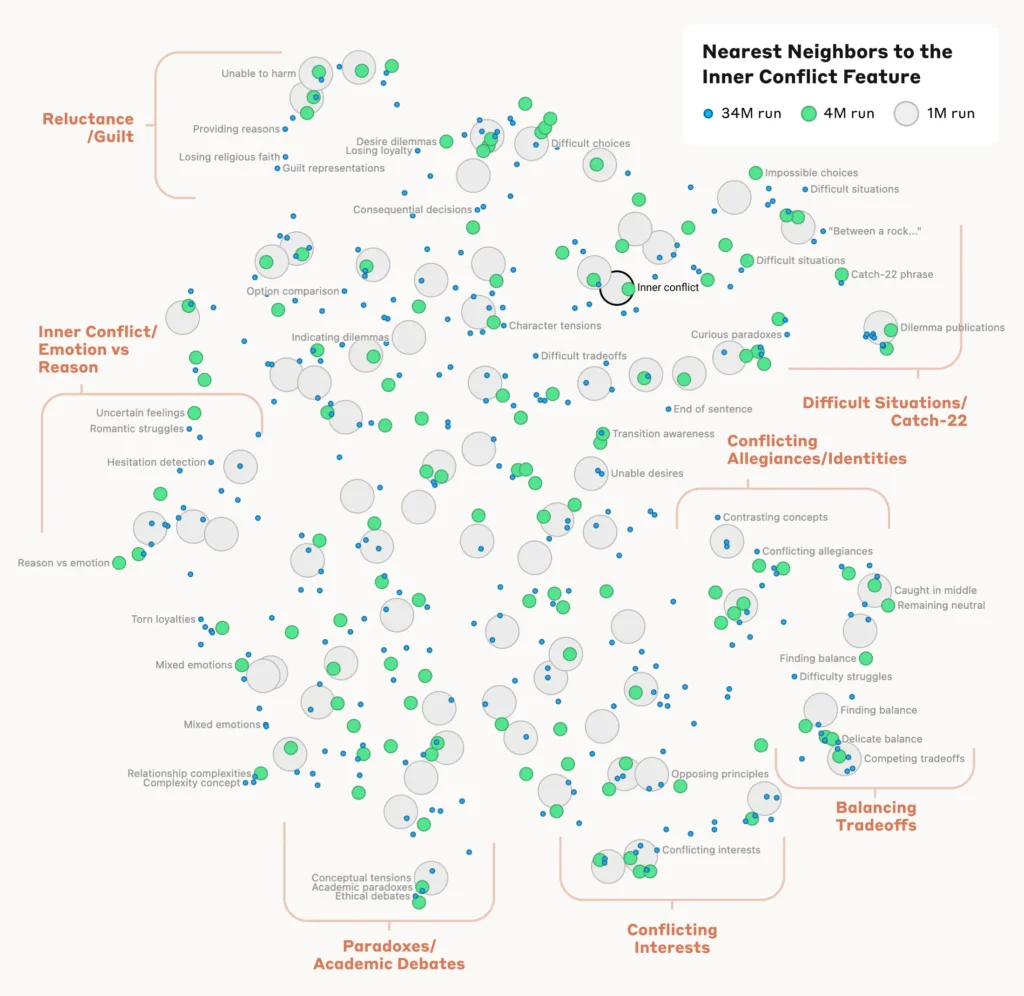
Проверка функций
Чтобы подтвердить, что выявленные особенности напрямую влияют на поведение и результаты модели, исследователи провели эксперименты по "управлению особенностями".
Для этого нужно было избирательно усиливать или подавлять активацию определенных функций во время обработки модели и наблюдать за тем, как это влияет на ее реакцию.
Манипулируя отдельными признаками, исследователи могли установить прямую связь между отдельными признаками и поведением модели. Например, усиление признака, связанного с конкретным городом, заставляло модель генерировать результаты, ориентированные на город, даже в нерелевантных контекстах.
Прочитать полный текст исследования здесь.
Почему интерпретируемость имеет решающее значение для безопасности ИИ
AnthropicИсследования компании имеют фундаментальное значение для интерпретируемости ИИ и, как следствие, безопасности.
Понимание того, как LLM обрабатывают и представляют информацию, помогает исследователям понять и снизить риски. Это закладывает основу для разработки более прозрачных и объяснимых систем ИИ.
Как Anthropic Мы надеемся, что мы и другие смогут использовать эти открытия, чтобы сделать модели более безопасными. Например, с помощью описанных здесь методов можно будет отслеживать системы ИИ на предмет опасного поведения (например, обмана пользователя), направлять их на достижение желаемых результатов (дебилизация) или полностью удалять опасные объекты".
Более глубокое понимание поведения ИИ приобретает первостепенное значение по мере того, как они становятся повсеместными для принятия важнейших решений в таких областях, как здравоохранение, финансы и уголовное правосудие. Это также поможет выявить первопричину смещениегаллюцинации и другие нежелательные или непредсказуемые формы поведения.
Например. недавнее исследование Специалисты Боннского университета выяснили, что графовые нейронные сети (ГНС), используемые для поиска лекарств, в значительной степени опираются на запоминание сходств из обучающих данных, а не на реальное изучение новых сложных химических взаимодействий.
Это затрудняет понимание того, как именно эти модели определяют новые соединения, представляющие интерес.
В прошлом году Правительство Великобритании вело переговоры с такими крупными технологическими гигантами, как OpenAI и DeepMindОни стремятся получить доступ к внутренним процессам принятия решений системами искусственного интеллекта.
Регулирование, как Закон ЕС об искусственном интеллекте заставит компании, занимающиеся разработкой ИИ, быть более прозрачными, хотя коммерческие секреты, похоже, останутся под замком.
AnthropicИсследование, проведенное компанией, позволяет взглянуть на то, что находится внутри коробки, путем "отображения" информации на модели.
Однако на самом деле эти модели настолько обширны, что, по Anthropicпо собственному признанию: "Мы думаем, что вполне вероятно, что нам не хватает порядков, и что если бы мы хотели получить все характеристики - во всех слоях! - нам пришлось бы использовать гораздо больше вычислений, чем требуется для обучения базовых моделей".
Это интересный момент - обратное проектирование модели является более сложным с вычислительной точки зрения, чем проектирование модели изначально.
Это напоминает такие дорогостоящие проекты в области нейронаук, как Проект "Мозг человека" (HBP), которая вложила миллиарды в составление карты нашего собственного человеческого мозга, но в итоге потерпела неудачу.
Никогда не стоит недооценивать, сколько всего скрывается в черном ящике.



